wireless charger
View this post on Instagram
Digital Literacy for St. Cloud State University
View this post on Instagram
this infographic from the European Association for Viewers Interests which took me on a tour of ten types of misleading news—propaganda, clickbait, sponsored content, satire and hoax, error, partisan, conspiracy theory, pseudoscience, misinformation and bogus information.
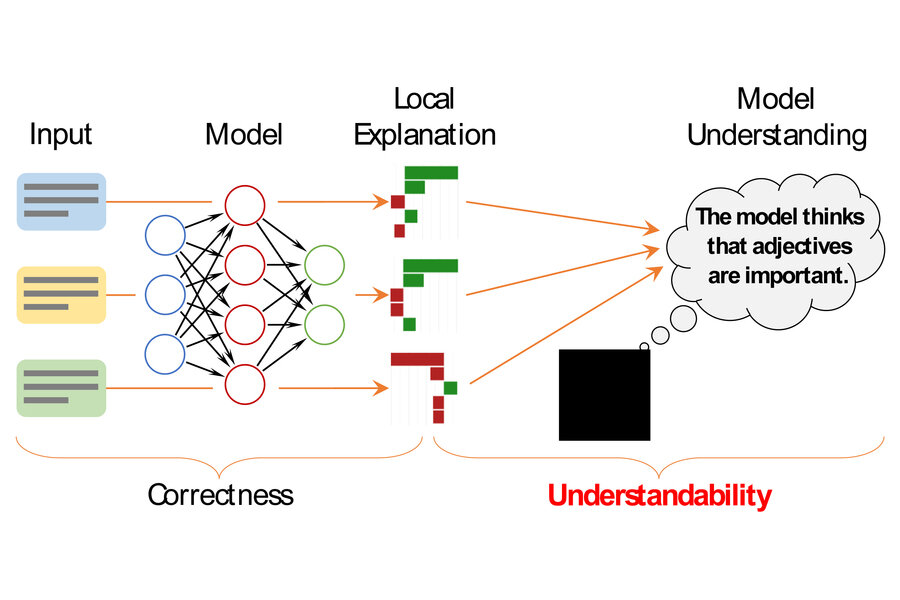
https://techxplore.com/news/2022-05-framework-individual-machine-learning-decisions.html
++++++++++++++++++++++
more on machine learning in this IMS blog
https://blog.stcloudstate.edu/ims?s=machine+learning
A Senate hearing this week and a new law in Europe show how “transparency” advocates are winning
the Platform Transparency and Accountability Act, was introduced in December by (an ever-so-slightly) bipartisan group of senators.
“YouTube, TikTok, Telegram, and Snapchat represent some of the largest and most influential platforms in the United States, and they provide almost no functional transparency into their systems. And as a result, they avoid nearly all of the scrutiny and criticism that comes with it.”
When we do hear about what happens inside a tech company, it’s often because a Frances Haugen-type employee decides to leak it.
Cruz expressed great confusion about why he got relatively few new Twitter followers in the days before Elon Musk said he was going to buy it, but then got many more after the acquisition was announced.
The actual explanation is that Musk has lots of conservative fans, they flocked back to the platform when they heard he was buying it, and from there Twitter’s recommendation algorithms kicked into gear.
As usual, though, Europe is much further ahead of us. The Digital Services Act, which regulators reached an agreement on in April, includes provisions that would require big platforms to share data with qualified researchers. The law is expected to go into effect by next year. And so even if Congress dithers after today, transparency is coming to platforms one way or another. Here’s hoping it can begin to answer some very important questions.
https://www.iste.org/explore/computational-thinking-and-data-analysis-go-hand-hand
Two-pronged technique detects manipulated facial expressions and identity swaps
https://news.ucr.edu/articles/2022/05/03/new-method-detects-deepfake-videos-99-accuracy
https://www.cnet.com/news/privacy/india-orders-vpn-companies-to-collect-and-hand-over-user-data/
A new government order will force virtual private networks to store user data for five years or longer.
The directive isn’t limited to VPN providers. Data centers and cloud service providers are both listed under the same provision. The companies will have to keep customer information even after the customer has canceled their subscription or account.
India has a history of applying a heavy hand to online activity.
In April, India banned 22 YouTube channels. In 2021, Facebook, Google Twitter ended a tense stand-off with the Indian government when they largely complied with the government’s expanded control over social media content in the country. In 2020, the country banned over 200 Chinese apps, including TikTok, and ultimately banned 9,849 social media URLs.