Hi all, I don’t use Grammarly, but I hear that a lot of people find it useful. I am also hearing that some instructors/universities find its use problematic. Several years ago, a student that I knew was not a good writer was accused of plagiarism by another instructor. She claimed that her nearly flawless papers were written with the help of Grammarly. I am curious to know if you encourage or prohibit Grammarly in your classes and if your department or university has a policy concerning its use.
My summation of this thread:
naturally, opinions are for and against:
pros –
it helps/forces students understand the need to proofread
partially replaces the very initial work of instructor
cons –
algorithms/technology are/is not perfect
it does not replace a living person (sic!!!)
e.g. it detect passive voice, but does not teach the replacement
Radianti, J., Majchrzak, T. A., Fromm, J., & Wohlgenannt, I. (2020). A systematic review of immersive virtual reality applications for higher education: Design elements, lessons learned, and research agenda. Computers & Education, 147, 103778. https://doi.org/10.1016/j.compedu.2019.103778
p. 3
2.2. Learning paradigms
An understanding of the existing learning paradigms is essential for performing an analysis of the current state of VR applications in higher education. Thus, we introduce the main ideas behind the existing learning paradigms. Literature distinguishes between behaviorism, cognitivism, and constructivism (Schunk, 2012). Other scholars also include experiential learning (Kolb & Kolb, 2012) to this list and, recently, connectivism has been introduced as a new learning paradigm (Kathleen Dunaway, 2011; Siemens, 2014). Each learning paradigm has developed various theories about educational goals and outcomes (Schunk, 2012). Each of these theories also offers a different perspective on the learning goals, motivational process, learning performance, transfer of knowledge process, the role of emotions, and implications for the teaching methods.
Behaviorism assumes that knowledge is a repertoire of behavioral responses to environmental stimuli (Shuell, 1986; Skinner, 1989). Thus, learning is considered to be a passive absorption of a predefined body of knowledge by the learner. According to this paradigm, learning requires repetition and learning motivation is extrinsic, involving positive and negative reinforcement. The teacher serves as a role model who transfers the correct behavioral response.
Cognitivism understands the acquisition of knowledge systems as actively constructed by learners based on pre-existing prior knowledge structures. Hence, the proponents of cognitivism view learning as an active, constructive, and goal-oriented process, which involves active assimilation and accommodation of new information to an existing body of knowledge. The learning motivation is intrinsic and learners should be capable of defining their own goals and motivating themselves to learn. Learning is supported by providing an environment that encourages discovery and assimilation or accommodation of knowledge (Shuell, 1986),RN23. Cognitivism views learning as more complex cognitive processes such as thinking, problem-solving, verbal information, concept formation, and information processing. It addresses the issues of how information is received, organized, stored, and retrieved by the mind. Knowledge acquisition is a mental activity consisting of internal coding and structuring by the learner. Digital media, including VR-based learning can strengthen cognitivist learning design (Dede, 2008). Cognitive strategies such as schematic organization, analogical reasoning, and algorithmic problem solving will fit learning tasks requiring an increased level of processing, e.g. classifications, rule or procedural executions (Ertmer & Newby, 1993) and be supported by digital media (Dede, 2008).
Constructivism posits that learning is an active, constructive process. Learners serve as information constructors who actively construct their subjective representations and comprehensions of reality. New information is linked to the prior knowledge of each learner and, thus, mental representations are subjective (Fosnot, 2013; Fosnot & Perry, 1996). Therefore, constructivists argue that the instructional learning design has to provide macro and micro support to assist the learners in constructing their knowledge and engaging them for meaningful learning. The macro support tools include related cases, information resources, cognitive tools, conversation, and collaboration tools, and social or contextual support. A micro strategy makes use of multimedia and principles such as the spatial contiguity principle, coherence principle, modality principle, and redundancy principle to strengthen the learning process. VR-based learning fits the constructivist learning design (Lee & Wong, 2008; Sharma, Agada, & Ruffin, 2013). Constructivist strategies such as situated learning, cognitive apprenticeships, and social negotiation are appropriate for learning tasks demanding high levels of processing, for instance, heuristic problem solving, personal selection, and monitoring of cognitive strategies (Ertmer & Newby, 1993).
Experientialism describes learning as following a cycle of experiential stages, from concrete experience, observation and reflection, and abstract conceptualization to testing concepts in new situations. Experientialism adopts the constructivist’s point of view to some extent—e.g., that learning should be drawn from a learner’s personal experience. The teacher takes on the role of a facilitator to motivate learners to address the various stages of the learning cycle (Kolb & Kolb, 2012).
Connectivism takes into account the digital-age by assuming that people process information by forming connections. This newly introduced paradigm suggests that people do not stop learning after completing their formal education. They continue to search for and gain knowledge outside of traditional education channels, such as job skills, networking, experience, and access to information, by making use of new technology tools (Siemens, 2014).
People who behaved in accordance with them—for example, by staying away from the overgrown pond bank where someone said there was a viper—were more likely to survive than those who did not.
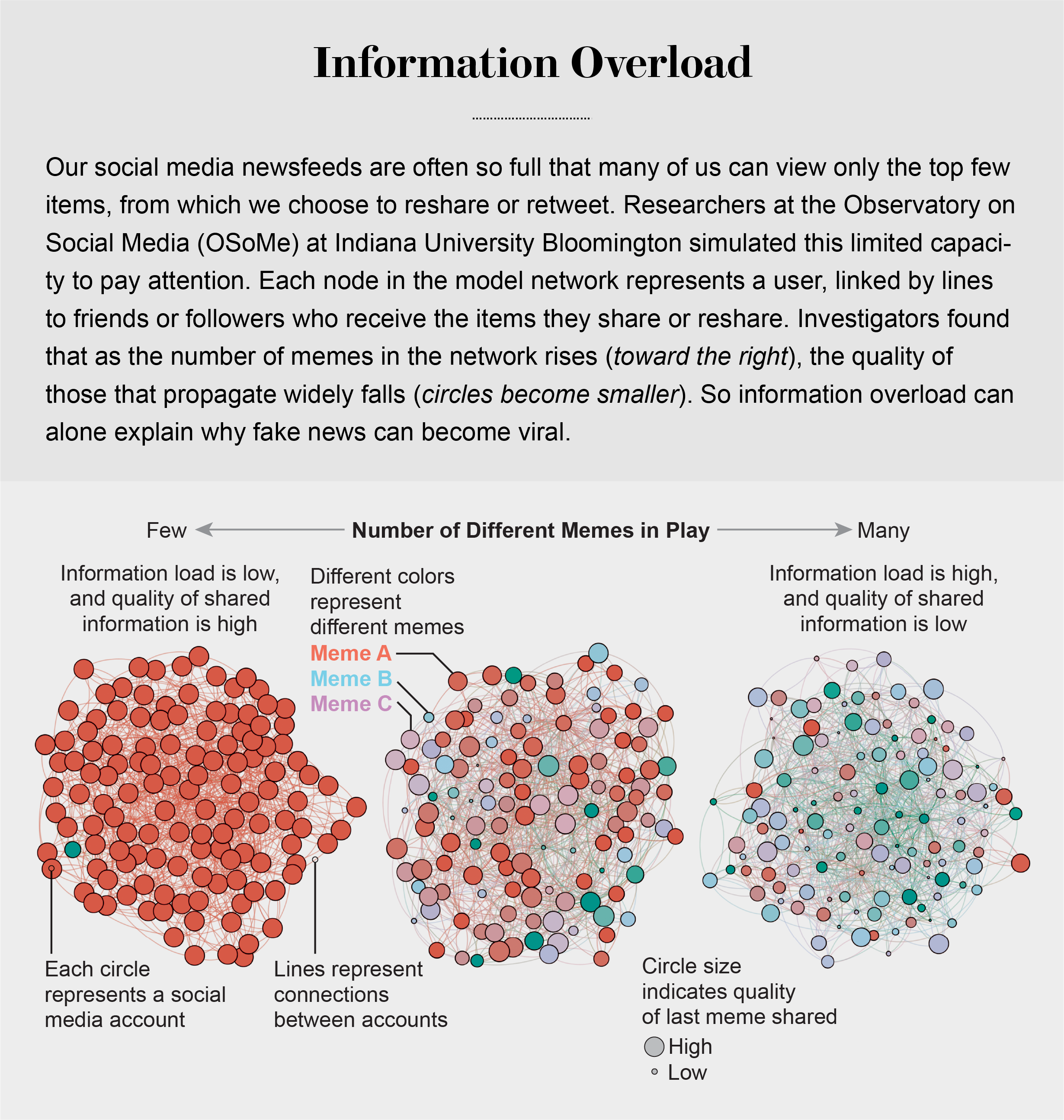
Compounding the problem is the proliferation of online information. Viewing and producing blogs, videos, tweets and other units of information called memes has become so cheap and easy that the information marketplace is inundated. My note: folksonomy in its worst.
At the University of Warwick in England and at Indiana University Bloomington’s Observatory on Social Media (OSoMe, pronounced “awesome”), our teams are using cognitive experiments, simulations, data mining and artificial intelligence to comprehend the cognitive vulnerabilities of social media users. developing analytical and machine-learning aids to fight social media manipulation.
As Nobel Prize–winning economist and psychologist Herbert A. Simon noted, “What information consumes is rather obvious: it consumes the attention of its recipients.”
attention economy
Our models revealed that even when we want to see and share high-quality information, our inability to view everything in our news feeds inevitably leads us to share things that are partly or completely untrue.
Frederic Bartlett
Cognitive biases greatly worsen the problem.
We now know that our minds do this all the time: they adjust our understanding of new information so that it fits in with what we already know. One consequence of this so-called confirmation bias is that people often seek out, recall and understand information that best confirms what they already believe.
This tendency is extremely difficult to correct.
Making matters worse, search engines and social media platforms provide personalized recommendations based on the vast amounts of data they have about users’ past preferences.
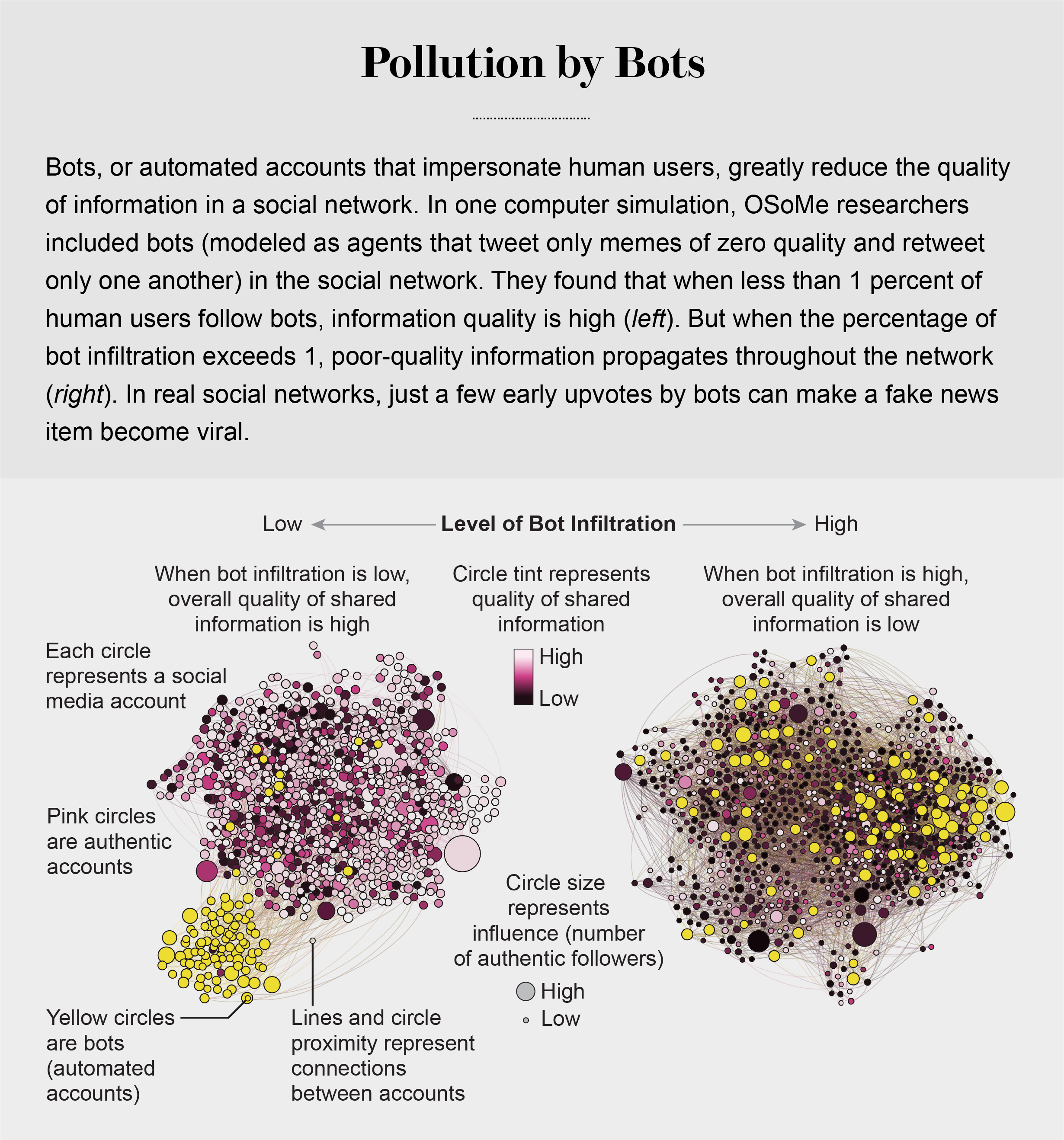
pollution by bots
Social Herding
social groups create a pressure toward conformity so powerful that it can overcome individual preferences, and by amplifying random early differences, it can cause segregated groups to diverge to extremes.
Social media follows a similar dynamic. We confuse popularity with quality and end up copying the behavior we observe.
information is transmitted via “complex contagion”: when we are repeatedly exposed to an idea, typically from many sources, we are more likely to adopt and reshare it.
In addition to showing us items that conform with our views, social media platforms such as Facebook, Twitter, YouTube and Instagram place popular content at the top of our screens and show us how many people have liked and shared something.Few of us realize that these cues do not provide independent assessments of quality.
programmers who design the algorithms for ranking memes on social media assume that the “wisdom of crowds” will quickly identify high-quality items; they use popularity as a proxy for quality. My note: again, ill-conceived folksonomy.
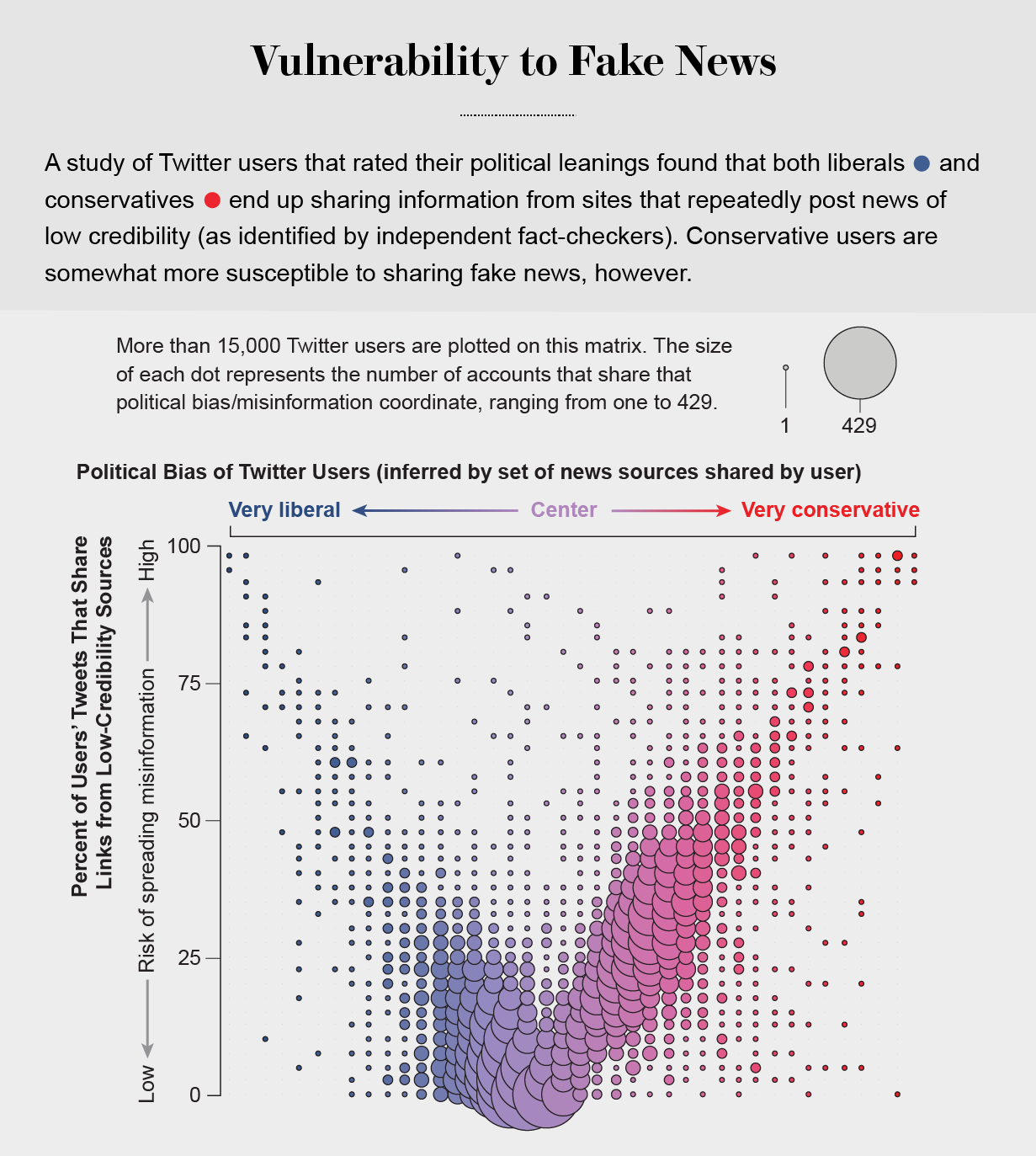
Echo Chambers
the political echo chambers on Twitter are so extreme that individual users’ political leanings can be predicted with high accuracy: you have the same opinions as the majority of your connections. This chambered structure efficiently spreads information within a community while insulating that community from other groups.
socially shared information not only bolsters our biases but also becomes more resilient to correction.
machine-learning algorithms to detect social bots. One of these, Botometer, is a public tool that extracts 1,200 features from a given Twitter account to characterize its profile, friends, social network structure, temporal activity patterns, language and other features. The program compares these characteristics with those of tens of thousands of previously identified bots to give the Twitter account a score for its likely use of automation.
Some manipulators play both sides of a divide through separate fake news sites and bots, driving political polarization or monetization by ads.
recently uncovered a network of inauthentic accounts on Twitter that were all coordinated by the same entity. Some pretended to be pro-Trump supporters of the Make America Great Again campaign, whereas others posed as Trump “resisters”; all asked for political donations.
a mobile app called Fakey that helps users learn how to spot misinformation. The game simulates a social media news feed, showing actual articles from low- and high-credibility sources. Users must decide what they can or should not share and what to fact-check. Analysis of data from Fakey confirms the prevalence of online social herding: users are more likely to share low-credibility articles when they believe that many other people have shared them.
Hoaxy, shows how any extant meme spreads through Twitter. In this visualization, nodes represent actual Twitter accounts, and links depict how retweets, quotes, mentions and replies propagate the meme from account to account.
Free communication is not free. By decreasing the cost of information, we have decreased its value and invited its adulteration.
Algorithmic proctoring software has been around for several years, but its use exploded as the COVID-19 pandemic forced schools to quickly transition to remote learning. Proctoring companies cite studies estimating that between 50 and 70 percent of college students will attempt some form of cheating, and warn that cheating will be rampant if students are left unmonitored in their own homes.
Like many other tech companies, they also balk at the suggestion that they are responsible for how their software is used. While their algorithms flag behavior that the designers have deemed suspicious, these companies argue that the ultimate determination of whether cheating occurred rests in the hands of the class instructor.
As more evidence emerges about how the programs work, and fail to work, critics say the tools are bound to hurt low-income students, students with disabilities, students with children or other dependents, and other groups who already face barriers in higher education.
“Each academic department has almost complete agency to design their curriculum as far as I know, and each professor has the freedom to design their own exams and use whatever monitoring they see fit,” Rohan Singh, a computer engineering student at Michigan State University, told Motherboard.
after students approached faculty members at the University of California Santa Barbara, the faculty association sent a letter to the school’s administration raising concerns about whether ProctorU would share student data with third parties. In response, a ProctorU attorney threatened to sue the faculty association for defamation and violating copyright law (because the association had used the company’s name and linked to its website). He also accused the faculty association of “directly impacting efforts to mitigate civil disruption across the United States” by interfering with education during a national emergency, and said he was sending his complaint to the state’s Attorney General.
here is a link to a community discussion regarding this and similar software use:
They then worked with a deepfake artist who used an open-source algorithm to swap in Putin’s and Kim’s faces. A post-production crew cleaned up the leftover artifacts of the algorithm to make the video look more realistic. All in all the process took only 10 days. Attempting the equivalent with CGI likely would have taken months, the team says. It also could have been prohibitively expensive.
digital ethics, which I define simply as “doing the right thing at the intersection of technology innovation and accepted social values.”
Weapons of Math Destruction: How Big Data Increases Inequality and Threatens Democracy, written by Cathy O’Neil in early 2016, continues to be relevant and illuminating. O’Neil’s book revolves around her insight that “algorithms are opinions embedded in code,” in distinct contrast to the belief that algorithms are based on—and produce—indisputable facts.
Safiya Umoja Noble’s book Algorithms of Oppression: How Search Engines Reinforce Racism
The Age of Surveillance Capitalism: The Fight for a Human Future at the New Frontier of Power
The larger discussions, from what constitutes a nutritious diet to what actions will best further U.S. interests, require conversations between ordinary citizens and experts. But increasingly, citizens don’t want to have those conversations. Rather, they want to weigh in and have their opinions treated with deep respect and their preferences honored not on the strength of their arguments or on the evidence they present but based on their feelings, emotions, and whatever stray information they may have picked up here or there along the way.
Hofstadter argued that this overwhelming complexity produced feelings of helplessness and anger among a citizenry that knew itself to be increasingly at the mercy of more sophisticated elites. “
Credentialism can run amok, and guilds can use it cynically to generate revenue or protect their fiefdoms with unnecessary barriers to entry. But it can also reflect actual learning and professional competence, helping separate real experts from amateurs or charlatans.
Experts are often wrong, and the good ones among them are the first to admit it…. Yet these days, members of the public search for expert errors and revel in finding them—<b>not to improve understanding but rather to give themselves license to disregard all expert advice they don’t like.<b>
The convenience of the Internet is a tremendous boon, but mostly for people already trained in research and who have some idea what they’re looking for. It does little good, unfortunately, for a student or an untrained layperson who has never been taught how to judge the provenance of information or the reputability of a writer.
Libraries, or at least their reference and academic sections, once served as a kind of first cut through the noise of the marketplace. The Internet, however, is less a library than a giant repository where anyone can dump anything. In practice, this means that a search for information will rely on algorithms usually developed by for-profit companies using opaque criteria. Actual research is hard and often boring. It requires the ability to find authentic information, sort through it, analyze it, and apply it.
Government and expertise rely on each other, especially in a democracy. The technological and economic progress that ensures the well-being of a population requires a division of labor, which in turn leads to the creation of professions. Professionalism encourages experts to do their best to serve their clients, respect their own knowledge boundaries, and demand that their boundaries be respected by others, as part of an overall service to the ultimate client: society itself.
Dictatorships, too, demand this same service of experts, but they extract it by threat and direct its use by command. This is why dictatorships are actually less efficient and less productive than democracies (despite some popular stereotypes to the contrary). In a democracy, the expert’s service to the public is part of the social contract.
Too few citizens today understand democracy to mean a condition of political equality in which all get the franchise and are equal in the eyes of the law. Rather, they think of it as a state of actual equality, in which every opinion is as good as any other, regardless of the logic or evidentiary base behind it.
#DunningKrugerEffect #metacognition #democracy #science #academy #fakenews #conspiracytheories #politics #idiocracy #InformationTechnology #Internet
Instructure has made it clear through their own language that they view the student data they aggregated as one of their chief assets, although they have also insisted that they do not use that data improperly. My note: “improperly” is relative and requires defining.
Yet an article published in the Virginia Journal of Law and Technology, titled “Transparency and the Marketplace for Student Data,” pointed out that there is “an overall lack of transparency in the student information commercial marketplace and an absence of law to protect student information.” As such, some students at the University of California are concerned that — despite reassurances to the contrary — their institution’s new financial relationship with Thoma Bravo will mean their personal data can be sold or otherwise misused.
Holland, B. (2020). Emerging Technology and Today’s Libraries. In Holland, B. (Eds.), Emerging Trends and Impacts of the Internet of Things in Libraries (pp. 1-33). IGI Global. http://doi:10.4018/978-1-7998-4742-7.ch001
The purpose of this chapter is to examine emerging technology and today’s libraries. New technology stands out first and foremost given that they will end up revolutionizing every industry in an age where digital transformation plays a major role. Major trends will define technological disruption. The next-gen of communication, core computing, and integration technologies will adopt new architectures. Major technological, economic, and environmental changes have generated interest in smart cities. Sensing technologies have made IoT possible, but also provide the data required for AI algorithms and models, often in real-time, to make intelligent business and operational decisions. Smart cities consume different types of electronic internet of things (IoT) sensors to collect data and then use these data to manage assets and resources efficiently. This includes data collected from citizens, devices, and assets that are processed and analyzed to monitor and manage, schools, libraries, hospitals, and other community services.
Makori, E. O. (2020). Blockchain Applications and Trends That Promote Information Management. In Holland, B. (Eds.), Emerging Trends and Impacts of the Internet of Things in Libraries (pp. 34-51). IGI Global. http://doi:10.4018/978-1-7998-4742-7.ch002
Blockchain revolutionary paradigm is the new and emerging digital innovation that organizations have no choice but to embrace and implement in order to sustain and manage service delivery to the customers. From disruptive to sustaining perspective, blockchain practices have transformed the information management environment with innovative products and services. Blockchain-based applications and innovations provide information management professionals and practitioners with robust and secure opportunities to transform corporate affairs and social responsibilities of organizations through accountability, integrity, and transparency; information governance; data and information security; as well as digital internet of things.
Hahn, J. (2020). Student Engagement and Smart Spaces: Library Browsing and Internet of Things Technology. In Holland, B. (Eds.), Emerging Trends and Impacts of the Internet of Things in Libraries (pp. 52-70). IGI Global. http://doi:10.4018/978-1-7998-4742-7.ch003
The purpose of this chapter is to provide evidence-based findings on student engagement within smart library spaces. The focus of smart libraries includes spaces that are enhanced with the internet of things (IoT) infrastructure and library collection maps accessed through a library-designed mobile application. The analysis herein explored IoT-based browsing within an undergraduate library collection. The open stacks and mobile infrastructure provided several years (2016-2019) of user-generated smart building data on browsing and selecting items in open stacks. The methods of analysis used in this chapter include transactional analysis and data visualization of IoT infrastructure logs. By analyzing server logs from the computing infrastructure that powers the IoT services, it is possible to infer in greater detail than heretofore possible the specifics of the way library collections are a target of undergraduate student engagement.
Treskon, M. (2020). Providing an Environment for Authentic Learning Experiences. In Holland, B. (Eds.), Emerging Trends and Impacts of the Internet of Things in Libraries (pp. 71-86). IGI Global. http://doi:10.4018/978-1-7998-4742-7.ch004
The Loyola Notre Dame Library provides authentic learning environments for undergraduate students by serving as “client” for senior capstone projects. Through the creative application of IoT technologies such as Arduinos and Raspberry Pis in a library setting, the students gain valuable experience working through software design methodology and create software in response to a real-world challenge. Although these proof-of-concept projects could be implemented, the library is primarily interested in furthering the research, teaching, and learning missions of the two universities it supports. Whether the library gets a product that is worth implementing is not a requirement; it is a “bonus.”
Rashid, M., Nazeer, I., Gupta, S. K., & Khanam, Z. (2020). Internet of Things: Architecture, Challenges, and Future Directions. In Holland, B. (Ed.), Emerging Trends and Impacts of the Internet of Things in Libraries (pp. 87-104). IGI Global. http://doi:10.4018/978-1-7998-4742-7.ch005
The internet of things (IoT) is a computing paradigm that has changed our daily livelihood and functioning. IoT focuses on the interconnection of all the sensor-based devices like smart meters, coffee machines, cell phones, etc., enabling these devices to exchange data with each other during human interactions. With easy connectivity among humans and devices, speed of data generation is getting multi-fold, increasing exponentially in volume, and is getting more complex in nature. In this chapter, the authors will outline the architecture of IoT for handling various issues and challenges in real-world problems and will cover various areas where usage of IoT is done in real applications. The authors believe that this chapter will act as a guide for researchers in IoT to create a technical revolution for future generations.
Martin, L. (2020). Cloud Computing, Smart Technology, and Library Automation. In Holland, B. (Eds.), Emerging Trends and Impacts of the Internet of Things in Libraries (pp. 105-123). IGI Global. http://doi:10.4018/978-1-7998-4742-7.ch006
As technology continues to change, the landscape of the work of librarians and libraries continue to adapt and adopt innovations that support their services. Technology also continues to be an essential tool for dissemination, retrieving, storing, and accessing the resources and information. Cloud computing is an essential component employed to carry out these tasks. The concept of cloud computing has long been a tool utilized in libraries. Many libraries use OCLC to catalog and manage resources and share resources, WorldCat, and other library applications that are cloud-based services. Cloud computing services are used in the library automation process. Using cloud-based services can streamline library services, minimize cost, and the need to have designated space for servers, software, or other hardware to perform library operations. Cloud computing systems with the library consolidate, unify, and optimize library operations such as acquisitions, cataloging, circulation, discovery, and retrieval of information.
Owusu-Ansah, S. (2020). Developing a Digital Engagement Strategy for Ghanaian University Libraries: An Exploratory Study. In Holland, B. (Eds.), Emerging Trends and Impacts of the Internet of Things in Libraries (pp. 124-139). IGI Global. http://doi:10.4018/978-1-7998-4742-7.ch007
This study represents a framework that digital libraries can leverage to increase usage and visibility. The adopted qualitative research aims to examine a digital engagement strategy for the libraries in the University of Ghana (UG). Data is collected from participants (digital librarians) who are key stakeholders of digital library service provision in the University of Ghana Library System (UGLS). The chapter reveals that digital library services included rare collections, e-journal, e-databases, e-books, microfilms, e-theses, e-newspapers, and e-past questions. Additionally, the research revealed that the digital library service patronage could be enhanced through outreach programmes, open access, exhibitions, social media, and conferences. Digital librarians recommend that to optimize digital library services, literacy programmes/instructions, social media platforms, IT equipment, software, and website must be deployed. In conclusion, a DES helps UGLS foster new relationships, connect with new audiences, and establish new or improved brand identity.
Nambobi, M., Ssemwogerere, R., & Ramadhan, B. K. (2020). Implementation of Autonomous Library Assistants Using RFID Technology. In Holland, B. (Ed.), Emerging Trends and Impacts of the Internet of Things in Libraries (pp. 140-150). IGI Global. http://doi:10.4018/978-1-7998-4742-7.ch008
This is an interesting time to innovate around disruptive technologies like the internet of things (IoT), machine learning, blockchain. Autonomous assistants (IoT) are the electro-mechanical system that performs any prescribed task automatically with no human intervention through self-learning and adaptation to changing environments. This means that by acknowledging autonomy, the system has to perceive environments, actuate a movement, and perform tasks with a high degree of autonomy. This means the ability to make their own decisions in a given set of the environment. It is important to note that autonomous IoT using radio frequency identification (RFID) technology is used in educational sectors to boost the research the arena, improve customer service, ease book identification and traceability of items in the library. This chapter discusses the role, importance, the critical tools, applicability, and challenges of autonomous IoT in the library using RFID technology.
Priya, A., & Sahana, S. K. (2020). Processor Scheduling in High-Performance Computing (HPC) Environment. In Holland, B. (Ed.), Emerging Trends and Impacts of the Internet of Things in Libraries (pp. 151-179). IGI Global. http://doi:10.4018/978-1-7998-4742-7.ch009
Processor scheduling is one of the thrust areas in the field of computer science. The future technologies use a huge amount of processing for execution of their tasks like huge games, programming software, and in the field of quantum computing. In real-time, many complex problems are solved by GPU programming. The primary concern of scheduling is to reduce the time complexity and manpower. Several traditional techniques exit for processor scheduling. The performance of traditional techniques is reduced when it comes to the huge processing of tasks. Most scheduling problems are NP-hard in nature. Many of the complex problems are recently solved by GPU programming. GPU scheduling is another complex issue as it runs thousands of threads in parallel and needs to be scheduled efficiently. For such large-scale scheduling problems, the performance of state-of-the-art algorithms is very poor. It is observed that evolutionary and genetic-based algorithms exhibit better performance for large-scale combinatorial and internet of things (IoT) problems.
Kirsch, B. (2020). Virtual Reality in Libraries. In Holland, B. (Eds.), Emerging Trends and Impacts of the Internet of Things in Libraries (pp. 180-193). IGI Global. http://doi:10.4018/978-1-7998-4742-7.ch010
Librarians are beginning to offer virtual reality (VR) services in libraries. This chapter reviews how libraries are currently using virtual reality for both consumption and creation purposes. Virtual reality tools will be compared and contrasted, and recommendations will be given for purchasing and circulating headsets and VR equipment. Google Tour Creator and a smartphone or 360-degree camera can be used to create a virtual tour of the library and other virtual reality content. These new library services will be discussed along with practical advice and best practices for incorporating virtual reality into the library for instructional and entertainment purposes.
Heffernan, K. L., & Chartier, S. (2020). Augmented Reality Gamifies the Library: A Ride Through the Technological Frontier. In Holland, B. (Ed.), Emerging Trends and Impacts of the Internet of Things in Libraries (pp. 194-210). IGI Global. http://doi:10.4018/978-1-7998-4742-7.ch011
Two librarians at a University in New Hampshire attempted to integrate gamification and mobile technologies into the exploration of, and orientation to, the library’s services and resources. From augmented reality to virtual escape rooms and finally an in-house app created by undergraduate, campus-based, game design students, the library team learned much about the triumphs and challenges that come with attempting to utilize new technologies to reach users in the 21st century. This chapter is a narrative describing years of various attempts, innovation, and iteration, which have led to the library team being on the verge of introducing an app that could revolutionize campus discovery and engagement.
Miltenoff, P. (2020). Video 360 and Augmented Reality: Visualization to Help Educators Enter the Era of eXtended Reality. In Holland, B. (Eds.), Emerging Trends and Impacts of the Internet of Things in Libraries (pp. 211-225). IGI Global. http://doi:10.4018/978-1-7998-4742-7.ch012
The advent of all types of eXtended Reality (XR)—VR, AR, MR—raises serious questions, both technological and pedagogical. The setup of campus services around XR is only the prelude to the more complex and expensive project of creating learning content using XR. In 2018, the authors started a limited proof-of-concept augmented reality (AR) project for a library tour. Building on their previous research and experience creating a virtual reality (VR) library tour, they sought a scalable introduction of XR services and content for the campus community. The AR library tour aimed to start us toward a matrix for similar services for the entire campus. They also explored the attitudes of students, faculty, and staff toward this new technology and its incorporation in education, as well as its potential and limitations toward the creation of a “smart” library.
The upside for businesses is that this new, “anonymized” video no longer gives away the exact identity of a customer—which, Perry says, means companies using D-ID can “eliminate the need for consent” and analyze the footage for business and marketing purposes. A store might, for example, feed video of a happy-looking white woman to an algorithm that can surface the most effective ad for her in real time.
Three leading European privacy experts who spoke to MIT Technology Review voiced their concerns about D-ID’s technology and its intentions. All say that, in their opinion, D-ID actually violates GDPR.