Eureka: machine learning tool, brainstorming engine. give it an initial idea and it returns similar ideas. Like Google: refine the idea, so the machine can understand it better. create a collection of ideas to translate into course design or others.
Netlix:
influencers and microinfluencers, pre- and doing the execution
a machine can construct a book with the help of a person. bionic book. machine and person working hand in hand. provide keywords and phrases from lecture notes, presentation materials. from there recommendations and suggestions based on own experience; then identify included and excluded content. then instructor can construct.
Design may be the least interesting part of the book for the faculty.
multiple choice quiz may be the least interesting part, and faculty might want to do much deeper assessment.
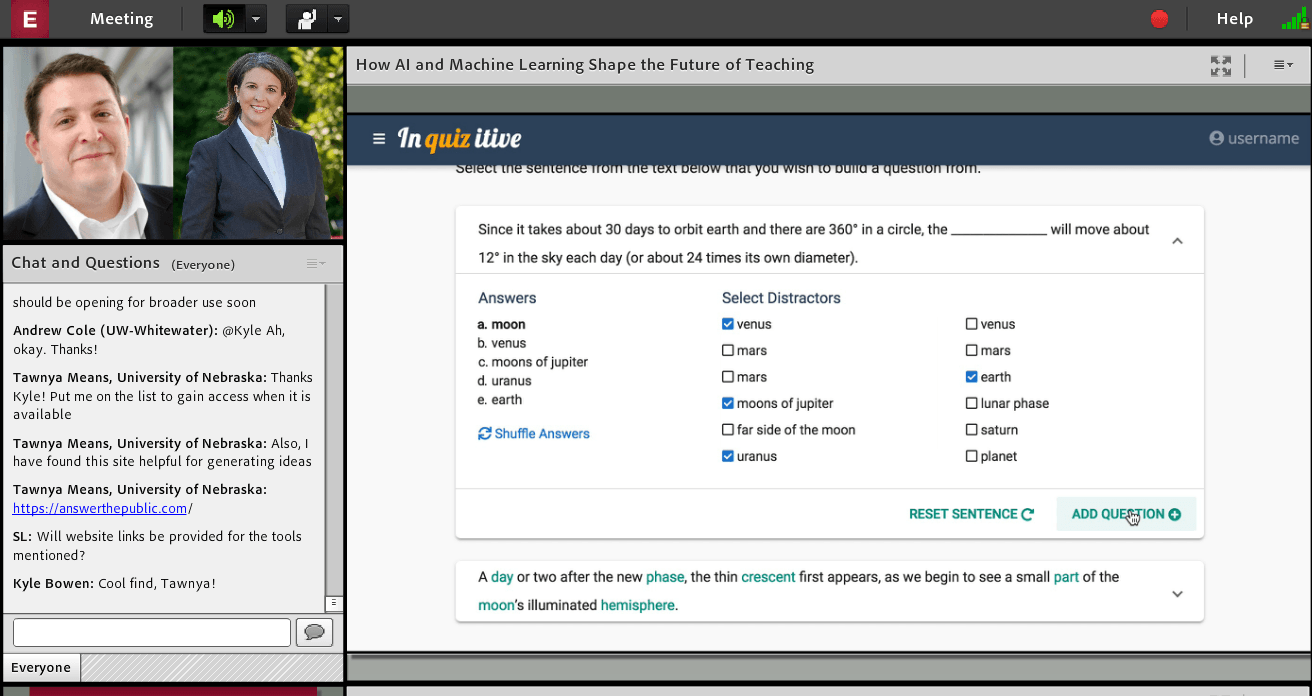
use these machine learning techniques to build assessment. how to more effectively. inquizitive is the machine learning
students engagements and similar prompts
presence in the classroom: pre-service teachers class. how to immerse them and practice classroom management skills
First class: marriage btw VR and use of AI – an environment headset: an algorithm reacts how teachers are interacting with the virtual kids. series of variables, oppty to interact with present behavior. classroom management skills. simulations and environments otherwise impossible to create. apps for these type of interactions
facilitation, reflection and research
AI for more human experience, allow more time for the faculty to be more human, more free time to contemplate.
Jason: Won’t the use of AI still reduce the amount of faculty needed?
Christina Dumeng: @Jason–I think it will most likely increase the amount of students per instructor.
Andrew Cole (UW-Whitewater): I wonder if instead of reducing faculty, these types of platforms (e.g., analytic capabilities) might require instructors to also become experts in the various technology platforms.
Dirk Morrison: Also wonder what the implications of AI for informal, self-directed learning?
Kate Borowske: The context that you’re presenting this in, as “your own jazz band,” is brilliant. These tools presented as a “partner” in the “band” seems as though it might be less threatening to faculty. Sort of gamifies parts of course design…?
Dirk Morrison: Move from teacher-centric to student-centric? Recommender systems, AI-based tutoring?
Andrew Cole (UW-Whitewater): The course with the bot TA must have been 100-level right? It would be interesting to see if those results replicate in 300, 400 level courses
Both jazz and classical art forms require not only music literacy, but for the musician to be at the top of their game in technical proficiency, tonal quality and creativity in the case of the jazz idiom. Jazz masters like John Coltrane would practice six to nine hours a day, often cutting his practice only because his inner lower lip would be bleeding from the friction caused by his mouth piece against his gums and teeth. His ability to compose and create new styles and directions for jazz was legendary. With few exceptions such as Wes Montgomery or Chet Baker, if you couldn’t read music, you couldn’t play jazz.
Besides the decline of music literacy and participation, there has also been a decline in the quality of music which has been proven scientifically by Joan Serra, a postdoctoral scholar at the Artificial Intelligence Research Institute of the Spanish National Research Council in Barcelona. Joan and his colleagues looked at 500,000 pieces of music between 1955-2010, running songs through a complex set of algorithms examining three aspects of those songs:
1. Timbre- sound color, texture and tone quality
2. Pitch- harmonic content of the piece, including its chords, melody, and tonal arrangements
3. Loudness- volume variance adding richness and depth
In an interview, Billy Joel was asked what has made him a standout. He responded his ability to read and compose music made him unique in the music industry, which as he explained, was troubling for the industry when being musically literate makes you stand out. An astonishing amount of today’s popular music is written by two people: Lukasz Gottwald of the United States and Max Martin from Sweden, who are both responsible for dozens of songs in the top 100 charts. You can credit Max and Dr. Luke for most the hits of these stars:
Katy Perry, Britney Spears, Kelly Clarkson, Taylor Swift, Jessie J., KE$HA, Miley Cyrus, Avril Lavigne, Maroon 5, Taio Cruz, Ellie Goulding, NSYNC, Backstreet Boys, Ariana Grande, Justin Timberlake, Nick Minaj, Celine Dion, Bon Jovi, Usher, Adam Lambert, Justin Bieber, Domino, Pink, Pitbull, One Direction, Flo Rida, Paris Hilton, The Veronicas, R. Kelly, Zebrahead
Way back in 1983, I identified A.I. as one of 20 exponential technologies that would increasingly drive economic growth for decades to come.
Artificial intelligence applies to computing systems designed to perform tasks usually reserved for human intelligence using logic, if-then rules, decision trees and machine learning to recognize patterns from vast amounts of data, provide insights, predict outcomes and make complex decisions. A.I. can be applied to pattern recognition, object classification, language translation, data translation, logistical modeling and predictive modeling, to name a few. It’s important to understand that all A.I. relies on vast amounts of quality data and advanced analytics technology. The quality of the data used will determine the reliability of the A.I. output.
Machine learning is a subset of A.I. that utilizes advanced statistical techniques to enable computing systems to improve at tasks with experience over time. Chatbots like Amazon’s Alexa, Apple’s Siri, or any of the others from companies like Google and Microsoft all get better every year thanks to all of the use we give them and the machine learning that takes place in the background.
Deep learning is a subset of machine learning that uses advanced algorithms to enable an A.I. system to train itself to perform tasks by exposing multi-layered neural networks to vast amounts of data, then using what has been learned to recognize new patterns contained in the data. Learning can be Human Supervised Learning, Unsupervised Learningand/or Reinforcement Learning like Google used with DeepMind to learn how to beat humans at the complex game Go. Reinforcement learning will drive some of the biggest breakthroughs.
Autonomous computing uses advanced A.I. tools such as deep learning to enable systems to be self-governing and capable of acting according to situational data without human command. A.I. autonomy includes perception, high-speed analytics, machine-to-machine communications and movement. For example, autonomous vehicles use all of these in real time to successfully pilot a vehicle without a human driver.
Augmented thinking: Over the next five years and beyond, A.I. will become increasingly embedded at the chip level into objects, processes, products and services, and humans will augment their personal problem-solving and decision-making abilities with the insights A.I. provides to get to a better answer faster.
Technology is not good or evil, it is how we as humans apply it. Since we can’t stop the increasing power of A.I., I want us to direct its future, putting it to the best possible use for humans.
Artificial intelligence could erase many practical advantages of democracy, and erode the ideals of liberty and equality. It will further concentrate power among a small elite if we don’t take steps to stop it.
Ordinary people may not understand artificial intelligence and biotechnology in any detail, but they can sense that the future is passing them by. In 1938 the common man’s condition in the Soviet Union, Germany, or the United States may have been grim, but he was constantly told that he was the most important thing in the world, and that he was the future (provided, of course, that he was an “ordinary man,” rather than, say, a Jew or a woman).
n 2018 the common person feels increasingly irrelevant. Lots of mysterious terms are bandied about excitedly in ted Talks, at government think tanks, and at high-tech conferences—globalization, blockchain, genetic engineering, AI, machine learning—and common people, both men and women, may well suspect that none of these terms is about them.
Fears of machines pushing people out of the job market are, of course, nothing new, and in the past such fears proved to be unfounded. But artificial intelligence is different from the old machines. In the past, machines competed with humans mainly in manual skills. Now they are beginning to compete with us in cognitive skills.
Israel is a leader in the field of surveillance technology, and has created in the occupied West Bank a working prototype for a total-surveillance regime. Already today whenever Palestinians make a phone call, post something on Facebook, or travel from one city to another, they are likely to be monitored by Israeli microphones, cameras, drones, or spy software. Algorithms analyze the gathered data, helping the Israeli security forces pinpoint and neutralize what they consider to be potential threats.
The conflict between democracy and dictatorship is actually a conflict between two different data-processing systems. AI may swing the advantage toward the latter.
As we rely more on Google for answers, our ability to locate information independently diminishes. Already today, “truth” is defined by the top results of a Google search. This process has likewise affected our physical abilities, such as navigating space.
So what should we do?
For starters, we need to place a much higher priority on understanding how the human mind works—particularly how our own wisdom and compassion can be cultivated.
Sejnowski, T. J. (2018). The Deep Learning Revolution. Cambridge, MA: The MIT Press.
How deep learning―from Google Translate to driverless cars to personal cognitive assistants―is changing our lives and transforming every sector of the economy.
The deep learning revolution has brought us driverless cars, the greatly improved Google Translate, fluent conversations with Siri and Alexa, and enormous profits from automated trading on the New York Stock Exchange. Deep learning networks can play poker better than professional poker players and defeat a world champion at Go. In this book, Terry Sejnowski explains how deep learning went from being an arcane academic field to a disruptive technology in the information economy.
Sejnowski played an important role in the founding of deep learning, as one of a small group of researchers in the 1980s who challenged the prevailing logic-and-symbol based version of AI. The new version of AI Sejnowski and others developed, which became deep learning, is fueled instead by data. Deep networks learn from data in the same way that babies experience the world, starting with fresh eyes and gradually acquiring the skills needed to navigate novel environments. Learning algorithms extract information from raw data; information can be used to create knowledge; knowledge underlies understanding; understanding leads to wisdom. Someday a driverless car will know the road better than you do and drive with more skill; a deep learning network will diagnose your illness; a personal cognitive assistant will augment your puny human brain. It took nature many millions of years to evolve human intelligence; AI is on a trajectory measured in decades. Sejnowski prepares us for a deep learning future.
Buzzwords like “deep learning” and “neural networks” are everywhere, but so much of the popular understanding is misguided, says Terrence Sejnowski, a computational neuroscientist at the Salk Institute for Biological Studies.
Sejnowski, a pioneer in the study of learning algorithms, is the author of The Deep Learning Revolution(out next week from MIT Press). He argues that the hype about killer AI or robots making us obsolete ignores exciting possibilities happening in the fields of computer science and neuroscience, and what can happen when artificial intelligence meets human intelligence.
Machine learning is a very large field and goes way back. Originally, people were calling it “pattern recognition,” but the algorithms became much broader and much more sophisticated mathematically. Within machine learning are neural networks inspired by the brain, and then deep learning. Deep learning algorithms have a particular architecture with many layers that flow through the network. So basically, deep learning is one part of machine learning and machine learning is one part of AI.
December 2012 at the NIPS meeting, which is the biggest AI conference. There, [computer scientist] Geoff Hinton and two of his graduate students showed you could take a very large dataset called ImageNet, with 10,000 categories and 10 million images, and reduce the classification error by 20 percent using deep learning.Traditionally on that dataset, error decreases by less than 1 percent in one year. In one year, 20 years of research was bypassed. That really opened the floodgates.
The inspiration for deep learning really comes from neuroscience.
AlphaGo, the program that beat the Go champion included not just a model of the cortex, but also a model of a part of the brain called the basal ganglia, which is important for making a sequence of decisions to meet a goal. There’s an algorithm there called temporal differences, developed back in the ‘80s by Richard Sutton, that, when coupled with deep learning, is capable of very sophisticated plays that no human has ever seen before.
there’s a convergence occurring between AI and human intelligence. As we learn more and more about how the brain works, that’s going to reflect back in AI. But at the same time, they’re actually creating a whole theory of learning that can be applied to understanding the brain and allowing us to analyze the thousands of neurons and how their activities are coming out. So there’s this feedback loop between neuroscience and AI
Summary This short paper lays out an attempt to measure how much activity from Russian state-operated accounts released in the dataset made available by Twitter in October 2018 was targeted at the United Kingdom. Finding UK-related Tweets is not an easy task. By applying a combination of geographic inference, keyword analysis and classification by algorithm, we identified UK-related Tweets sent by these accounts and subjected them to further qualitative and quantitative analytic techniques.
We find:
There were three phases in Russian influence operations : under-the-radar account building, minor Brexit vote visibility, and larger-scale visibility during the London terror attacks.
Russian influence operations linked to the UK were most visible when discussing Islam . Tweets discussing Islam over the period of terror attacks between March and June 2017 were retweeted 25 times more often than their other messages.
The most widely-followed and visible troll account, @TEN_GOP, shared 109 Tweets related to the UK. Of these, 60 percent were related to Islam .
The topology of tweet activity underlines the vulnerability of social media users to disinformation in the wake of a tragedy or outrage.
Focus on the UK was a minor part of wider influence operations in this data . Of the nine million Tweets released by Twitter, 3.1 million were in English (34 percent). Of these 3.1 million, we estimate 83 thousand were in some way linked to the UK (2.7%). Those Tweets were shared 222 thousand times. It is plausible we are therefore seeing how the UK was caught up in Russian operations against the US .
Influence operations captured in this data show attempts to falsely amplify other news sources and to take part in conversations around Islam , and rarely show attempts to spread ‘fake news’ or influence at an electoral level.
On 17 October 2018, Twitter released data about 9 million tweets from 3,841 blocked accounts affiliated with the Internet Research Agency (IRA) – a Russian organisation founded in 2013 and based in St Petersburg, accused of using social media platforms to push pro-Kremlin propaganda and influence nation states beyond their borders, as well as being tasked with spreading pro-Kremlin messaging in Russia. It is one of the first major datasets linked to state-operated accounts engaging in influence operations released by a social media platform.
Conclusion
This report outlines the ways in which accounts linked to the Russian Internet ResearchAgency (IRA) carried out influence operations on social media and the ways their operationsintersected with the UK.The UK plays a reasonably small part in the wider context of this data. We see two possibleexplanations: either influence operations were primarily targeted at the US and British Twitterusers were impacted as collate, or this dataset is limited to US-focused operations whereevents in the UK were highlighted in an attempt to impact US public, rather than a concertedeffort against the UK. It is plausible that such efforts al so existed but are not reflected inthis dataset.Nevertheless, the data offers a highly useful window into how Russian influence operationsare carried out, as well as highlighting the moments when we might be most vulnerable tothem.Between 2011 and 2016, these state-operated accounts were camouflaged. Through manualand automated methods, they were able to quietly build up the trappings of an active andwell-followed Twitter account before eventually pivoting into attempts to influence the widerTwitter ecosystem. Their methods included engaging in unrelated and innocuous topics ofconversation, often through automated methods, and through sharing and engaging withother, more mainstream sources of news.Although this data shows levels of electoral and party-political influence operations to berelatively low, the day of the Brexit referendum results showed how messaging originatingfrom Russian state-controlled accounts might come to be visible – on June 24th 2016, we believe UK Twitter users discussing the Brexit Vote would have encountered messages originating from these accounts.As early as 2014, however, influence operations began taking part in conversations aroundIslam, and these accounts came to the fore during the three months of terror attacks thattook place between March and June 2017. In the immediate wake of these attacks, messagesrelated to Islam and circulated by Russian state-operated Twitter accounts were widelyshared, and would likely have been visible in the UK.The dataset released by Twitter begins to answer some questions about attempts by a foreignstate to interfere in British affairs online. It is notable that overt political or electoralinterference is poorly represented in this dataset: rather, we see attempts at stirring societaldivision, particularly around Islam in the UK, as the messages that resonated the most overthe period.What is perhaps most interesting about this moment is its portrayal of when we as socialmedia users are most vulnerable to the kinds of messages circulated by those looking toinfluence us. In the immediate aftermath of terror attacks, the data suggests, social mediausers were more receptive to this kind of messaging than at any other time.
It is clear that hostile states have identified the growth of online news and social media as aweak spot, and that significant effort has gone into attempting to exploit new media toinfluence its users. Understanding the ways in which these platforms have been used tospread division is an important first step to fighting it.Nevertheless, it is clear that this dataset provides just one window into the ways in whichforeign states have attempted to use online platforms as part of wider information warfare
and influence campaigns. We hope that other platforms will follow Twitter’s lead and release
similar datasets and encourage their users to proactively tackle those who would abuse theirplatforms.
The main thing distinguishing a blockchain from a normal database is that there are specific rules about how to put data into the database. That is, it cannot conflict with some other data that’s already in the database (consistent), it’s append-only (immutable), and the data itself is locked to an owner (ownable), it’s replicable and available. Finally, everyone agrees on what the state of the things in the database are (canonical) without a central party (decentralized).
It is this last point that really is the holy grail of blockchain. Decentralization is very attractive because it implies there is no single point of failure.
The Cost of Blockchains
Development is stricter and slower
Incentive structures are difficult to design
Maintenance is very costly
Users are sovereign
All upgrades are voluntary
Scaling is really hard
Centralization is a lot easier
Like it or not, the word “blockchain” has taken on a life of its own. Very few people actually understand what it is, but want to appear hip so use these words as a way to sound more intelligent. Just like “cloud” means someone else’s computer and “AI” means a tweaked algorithm, “blockchain” in this context means a slow, expensive database.“blockchain” is really just a way to get rid of the heavy apparatus of government regulation. This is overselling what blockchain can do. Blockchain doesn’t magically take away human conflict.
So what is blockchain good for?
Most industries require new features or upgrades and the freedom to change and expand as necessary. Given that blockchains are hard to upgrade, hard to change and hard to scale, most industries don’t have much use for a blockchain. a lot of companies looking to use the blockchain are not really wanting a blockchain at all, but rather IT upgrades to their particular industry. This is all well and good, but using the word “blockchain” to get there is dishonest and overselling its capability.
the standard set of middle-class Democratic Party values: Public safety nets were a force for good, corporate greed was a real threat, civil and reproductive rights were paramount.
I remember how good it felt to stand with my friends in our matching college sweatshirts shouting “never again!” and “my body, my choice!”
We would all go to the mat for women’s rights, gay rights, or pretty much any rights other than gun rights. We lived, for the most part, in big cities in blue states.
When Barack Obama came into the picture, we loved him with the delirium of crushed-out teenagers, perhaps less for his policies than for being the kind of person who also listens to NPR. We loved Hillary Clinton with the fraught resignation of a daughter’s love for her mother. We loved her even if we didn’t like her. We were liberals, after all. We were family.
Words like “mansplaining” and “gaslighting” were suddenly in heavy rotation, often invoked with such elasticity as to render them nearly meaningless. Similarly, the term “woke,” which originated in black activism, was being now used to draw a bright line between those on the right side of things and those on the wrong side of things.
From the Black Guys on Bloggingheads, YouTube’s algorithms bounced me along a path of similarly unapologetic thought criminals: the neuroscientist Sam Harris and his Waking Up podcast; Christina Hoff Sommers, aka “The Factual Feminist”; the comedian turned YouTube interviewer Dave Rubin; the counter-extremist activist Maajid Nawaz; and a cantankerous and then little-known Canadian psychology professor named Jordan Peterson, who railed against authoritarianism on both the left and right but reserved special disdain for postmodernism, which he believed was eroding rational thought on campuses and elsewhere.
the sudden national obsession with female endangerment on college campuses struck me much the same way it had in the early 1990s: well-intended but ultimately infantilizing to women and essentially unfeminist.
Weinstein and his wife, the evolutionary biologist Heather Heying, who also taught at Evergreen, would eventually leave the school and go on to become core members of the “intellectual dark web.”
Weinstein talked about intellectual “feebleness” in academia and in the media, about the demise of nuance, about still considering himself a progressive despite his feeling that the far left was no better at offering practical solutions to the world’s problems than the far right.
an American Enterprise Institute video of Sommers, the Factual Feminist, in conversation with the scholar and social critic Camille Paglia — “My generation fought for the freedom for women to risk getting raped!” I watched yet another video in which Paglia sat by herself and expounded volcanically about the patriarchal history of art (she was all for it).
James Baldwin’s line, “I love America more than any other country in the world, and, exactly for this reason, I insist on the right to criticize her perpetually
Jordan Peterson Twelve Rules for Life: An Antidote for Chaos, is a sort of New and Improved Testament for the purpose-lacking young person (often but not always male) for whom tough-love directives like “clean up your room!” go down a lot easier when dispensed with a Jungian, evo-psych panache.
Quillette, a new online magazine that billed itself as “a platform for free thought”
the more honest we are about what we think, the more we’re alone with our thoughts. Just as you can’t fight Trumpism with tribalism, you can’t fight tribalism with a tribe.
Understanding what sources to trust is a basic tenet of media literacy education.
Think about how this might play out in communities where the “liberal media” is viewed with disdain as an untrustworthy source of information…or in those where science is seen as contradicting the knowledge of religious people…or where degrees are viewed as a weapon of the elite to justify oppression of working people. Needless to say, not everyone agrees on what makes a trusted source.
Students are also encouraged to reflect on economic and political incentives that might bias reporting. Follow the money, they are told. Now watch what happens when they are given a list of names of major power players in the East Coast news media whose names are all clearly Jewish. Welcome to an opening for anti-Semitic ideology.
In the United States, we believe that worthy people lift themselves up by their bootstraps. This is our idea of freedom. To take away the power of individuals to control their own destiny is viewed as anti-American by so much of this country. You are your own master.
Children are indoctrinated into this cultural logic early, even as their parents restrict their mobility and limit their access to social situations. But when it comes to information, they are taught that they are the sole proprietors of knowledge. All they have to do is “do the research” for themselves and they will know better than anyone what is real.
Many marginalized groups are justifiably angry about the ways in which their stories have been dismissed by mainstream media for decades.It took five days for major news outlets to cover Ferguson. It took months and a lot of celebrities for journalists to start discussing the Dakota Pipeline. But feeling marginalized from news media isn’t just about people of color.
Keep in mind that anti-vaxxers aren’t arguing that vaccinations definitively cause autism. They are arguing that we don’t know. They are arguing that experts are forcing children to be vaccinated against their will, which sounds like oppression. What they want is choice — the choice to not vaccinate. And they want information about the risks of vaccination, which they feel are not being given to them. In essence, they are doing what we taught them to do: questioning information sources and raising doubts about the incentives of those who are pushing a single message. Doubt has become tool.
Addressing so-called fake news is going to require a lot more than labeling. It’s going to require a cultural change about how we make sense of information, whom we trust, and how we understand our own role in grappling with information. Quick and easy solutions may make the controversy go away, but they won’t address the underlying problems.
boyd, danah. (2014). It’s Complicated: The Social Lives of Networked Teens (1 edition). New Haven: Yale University Press.
p. 8 networked publics are publics that are reconstructed by networked technologies. they are both space and imagined community.
p. 11 affordances: persistence, visibility, spreadability, searchability.
p. technological determinism both utopian and dystopian
p. 30 adults misinterpret teens online self-expression.
p. 31 taken out of context. Joshua Meyrowitz about Stokely Charmichael.
p. 43 as teens have embraced a plethora of social environment and helped co-create the norms that underpin them, a wide range of practices has emerged. teens have grown sophisticated with how they manage contexts and present themselves in order to be read by their intended audience.
p. 54 privacy. p. 59 Privacy is a complex concept without a clear definition. Supreme Court Justice Brandeis: the right to be let alone, but also ‘measure of th access others have to you through information, attention, and physical proximity.’
control over access and visibility
p. 65 social steganography. hiding messages in plain sight
p. 69 subtweeting. encoding content
p. 70 living with surveillance . Foucault Discipline and Punish
p. 77 addition. what makes teens obsessed w social media.
p. 81 Ivan Goldberg coined the term internet addiction disorder. jokingly
p. 89 the decision to introduce programmed activities and limit unstructured time is not unwarranted; research has shown a correlation between boredom and deviance.
My interview with Myra, a middle-class white fifteen-year-old from Iowa, turned funny and sad when “lack of time” became a verbal trick in response to every question. From learning Czech to trakc, from orchestra to work in a nursery, she told me that her mother organized “98%” of her daily routine. Myra did not like all of these activities, but her mother thought they were important.
Myra noted that her mother meant well, but she was exhausted and felt socially disconnected because she did not have time to connect with friends outside of class.
p. 100 danger
are sexual predators lurking everywhere
p. 128 bullying. is social media amplifying meanness and cruelty.
p. 131 defining bullying in a digital era. p. 131 Dan Olweus narrowed in the 70s bulling to three components: aggression, repetition and imbalance on power. p. 152 SM has not radically altered the dynamics of bullying, but it has made these dynamics more visible to more people. we must use this visibility not to justify increased punishment, but to help youth who are actually crying out for attention.
p. 153 inequality. can SM resolve social divisions?
p. 176 literacy. are today’s youth digital natives? p. 178 Barlow and Rushkoff p. 179 Prensky. p. 180 youth need new literacies. p. 181 youth must become media literate. when they engage with media–either as consumers or producers–they need to have the skills to ask questions about the construction and dissemination of particular media artifacts. what biases are embedded in the artifact? how did the creator intend for an audience to interpret the artifact, and what are the consequences of that interpretation.
p. 183 the politics of algorithms (see also these IMS blog entrieshttps://blog.stcloudstate.edu/ims?s=algorithms) Wikipedia and google are fundamentally different sites. p. 186 Eli Pariser, The Filter Bubble: the personalization algorithms produce social divisions that undermine any ability to crate an informed public. Harvard’s Berkman Center have shown, search engines like Google shape the quality of information experienced by youth.
p. 192 digital inequality. p. 194 (bottom) 195 Eszter Hargittai: there are signifficant difference in media literacy and technical skills even within age cohorts. teens technological skills are strongly correlated with socio-economic status. Hargittai argues that many youth, far from being digital natives, are quite digitally naive.
p. 195 Dmitry Epstein: when society frames the digital divide as a problem of access, we see government and industry as the responsible party for the addressing the issue. If DD as skills issue, we place the onus on learning how to manage on individuals and families.
p. 196 beyond digital natives
Palfrey, J., & Gasser, U. (2008). Born Digital: Understanding the First Generation of Digital Natives (1 edition). New York: Basic Books.
John Palfrey, Urs Gasser: Born Digital
Digital Natives share a common global culture that is defined not by age, strictly, but by certain attributes and experience related to how they interact with information technologies, information itself, one another, and other people and institutions. Those who were not “born digital’ can be just as connected, if not more so, than their younger counterparts. And not everyone born since, say 1982, happens to be a digital native.” (see also https://blog.stcloudstate.edu/ims/2018/04/15/no-millennials-gen-z-gen-x/
p. 197. digital native rhetoric is worse than inaccurate: it is dangerous
many of the media literacy skills needed to be digitally savvy require a level of engagement that goes far beyond what the average teen pick up hanging out with friends on FB or Twitter. Technical skills, such as the ability to build online spaces requires active cultivation. Why some search queries return some content before others. Why social media push young people to learn how to to build their own systems, versus simply using a social media platforms. teens social status and position alone do not determine how fluent or informed they are via-a-vis technology.