p. 766
Visualizations of library data have been used to: • reveal relationships among subject areas for users. • illuminate circulation patterns. • suggest titles for weeding. • analyze citations and map scholarly communications
Each unit of data analyzed can be described as topical, asking “what.”6 • What is the number of courses offered in each major and minor? • What is expended in each subject area? • What is the size of the physical collection in each subject area? • What is student enrollment in each area? • What is the circulation in specific areas for one year?
libraries, if they are to survive, must rethink their collecting and service strategies in radical and possibly scary ways and to do so sooner rather than later. Anderson predicts that, in the next ten years, the “idea of collection” will be overhauled in favor of “dynamic access to a virtually unlimited flow of information products.” My note: in essence, the fight between Mark Vargas and the Acquisition/Cataloguing people
The library collection of today is changing, affected by many factors, such as demanddriven acquisitions, access, streaming media, interdisciplinary coursework, ordering enthusiasm, new areas of study, political pressures, vendor changes, and the individual faculty member following a focused line of research.
subject librarians may see opportunities in looking more closely at the relatively unexplored “intersection of circulation, interlibrary loan, and holdings.”
Using Visualizations to Address Library Problems
the difference between graphical representations of environments and knowledge visualization, which generates graphical representations of meaningful relationships among retrieved files or objects.
Exhaustive lists of data visualization tools include: • the DIRT Directory (http://dirtdirectory.org/categories/visualization) • Kathy Schrock’s educating through infographics (www.schrockguide.net/ infographics-as-an-assessment.html) • Dataviz list of online tools (www.improving-visualisation.org/case-studies/id=5)
Eugene O’Loughlin, National College of Ireland, is very helpful in composing the charts and is found here: https://youtu.be/4FyImh2G7N0.
p. 771 By looking at the data (my note – by visualizing the data), more questions are revealed, The visualizations provide greater comprehension than the two-dimensional “flatland” of the spreadsheets, in which valuable questions and insights are lost in the columns and rows of data.
By looking at data visualized in different combinations, library collection development teams can clearly compare important considerations in collection management: expenditures and purchases, circulation, student enrollment, and course hours. Library staff and administrators can make funding decisions or begin dialog based on data free from political pressure or from the influence of the squeakiest wheel in a department.
The Middlebury College Libraries had its non-personnel budget cut by nearly a third for the 2021 fiscal year, resulting in reduced or delayed access to databases, journals and books, as well as an increasing reliance on interlibrary loan (ILL).
Other services were transitioned to a token system. In contrast to the previous unlimited access model, the college now pays for a finite supply of tokens that are used to purchase access to sources individually.
This purpose of this second group project is to relate the concepts of the text to present organizations. Each Team will select an organization or create an organization and present on that organization. The focus of this project is sustainability, and accounts for 30% of the grade. The presentation will consist of 20 to 30 minutes, a presentation of 10 to slides 20 slides, complete with a 10-15-page paper. The presentation and paper will be due electronically prior to class. Members will be graded on 50% contribution and 50 % presentation. The objective of this exercise is to develop skills in working as a team as well as developing your presentation skills.
The paper shall address the following analysis to the selected organization:
The firm may a service or manufacturing firm, or one that you create.
Relate each Chapter of the book (minimum twelve chapter relationships)
The relationship could be made from a topic within that chapter.
All projects must be uploaded in D2L/Brightspace by start of class, 9:30 AM, March 30, 2021
Why Keyword Searching?
Why not just type in a phrase or sentence like you do in Google or Yahoo!?
Because most electronic databases store and retrieve information differently than Internet search engines.
A databases searches fields within a collection of records. These fields include the information commonly found in a citation plus an abstract (if available) and subject headings. Search engines search web content which is typically the full text of sources.
The bottom line: you get better results in a database by using effective keyword search strategies.
To develop an effective search strategy, you need to:
determine the key concepts in your topic and
develop a good list of keyword synonyms.
Why use synonyms?
Because there is more than one way to express a concept or idea. You don’t know if the article you’re looking for uses the same expression for a key concept that you are using.
Consider: Will an author use:
Hypertension or High Blood Pressure?
Teach or Instruct?
Therapy or Treatment?
Class assignment (5-10 Min)
Share keywords related to the Engineering Management Project
Getting Ready for Research (15-20 min)
Library Resources vs. the Internet (do we need to discuss?)
walk together through the eBooks dbases to figure out logins and search techniques.
Personal work with the librarian (5 min each student)
using the list of keywords and the information sources, collaborate with the librarian to find 3-5 references for your project
according to Pew Research Center, 68 percent of American adults get their news from social media—platforms where opinion is often presented as fact.
results of the international test revealed that only 14 percent of U.S. students were able to reliably distinguish between fact and opinion.
News and Media Literacy (and the lack of) is not very different from Information Literacy
An “information literate” student is able to “locate, evaluate, and effectively use information from diverse sources.” See more About Information Literacy.
How does information literacy help me?
Every day we have questions that need answers. Where do we go? Whom can we trust? How can we find information to help ourselves? How can we help our family and friends? How can we learn about the world and be a better citizen? How can we make our voice heard?
Standard 1. The information literate student determines the nature and extent of the information needed
Standard 2. The information literate student accesses needed information effectively and efficiently
Standard 3. The information literate student evaluates information and its sources critically and incorporates selected information into his or her knowledge base and value system
Standard 4. The information literate student, individually or as a member of a group, uses information effectively to accomplish a specific purpose
Standard 5. The information literate student understands many of the economic, legal, and social issues surrounding the use of information and accesses and uses information ethically and legally
Project Information Literacy
A national, longitudinal research study based in the University of Washington’s iSchool, compiling data on college students habits to seek and use information.
+++++++++++++++++++++++
Developing Your Research Topic/Question
Research always starts with a question. But the success of your research also depends on how you formulate that question. If your topic is too broad or too narrow, you may have trouble finding information when you search. When developing your question/topic, consider the following:
Research always starts with a question. But the success of your research also depends on how you formulate that question. If your topic is too broad or too narrow, you may have trouble finding information when you search. When developing your question/topic, consider the following:
Is my question one that is likely to have been researched and for which data have been published? Believe it or not, not every topic has been researched and/or published in the literature.
Be flexible. Consider broadening or narrowing the topic if you are getting a limited number or an overwhelming number of results when you search. In nursing it can be helpful to narrow by thinking about a specific population (gender, age, disease or condition, etc.), intervention, or outcome.
Discuss your topic with your professor and be willing to alter your topic according to the guidance you receive.
Getting Ready for Research
Library Resources vs. the Internet
How (where from) do you receive information about your professional interests?
Advantages/disadvantages of using Web Resources
Why Keyword Searching?
Why not just type in a phrase or sentence like you do in Google or Yahoo!?
Because most electronic databases store and retrieve information differently than Internet search engines.
A databases searches fields within a collection of records. These fields include the information commonly found in a citation plus an abstract (if available) and subject headings. Search engines search web content which is typically the full text of sources.
The bottom line: you get better results in a database by using effective keyword search strategies.
To develop an effective search strategy, you need to:
determine the key concepts in your topic and
develop a good list of keyword synonyms.
Why use synonyms?
Because there is more than one way to express a concept or idea. You don’t know if the article you’re looking for uses the same expression for a key concept that you are using.
Consider: Will an author use:
Hypertension or High Blood Pressure?
Teach or Instruct?
Therapy or Treatment?
Don’t get “keyword lock!” Be willing to try a different term as a keyword. If you are having trouble thinking of synonyms, check a thesaurus, dictionary, or reference book for ideas.
Keyword worksheet
Library Resources
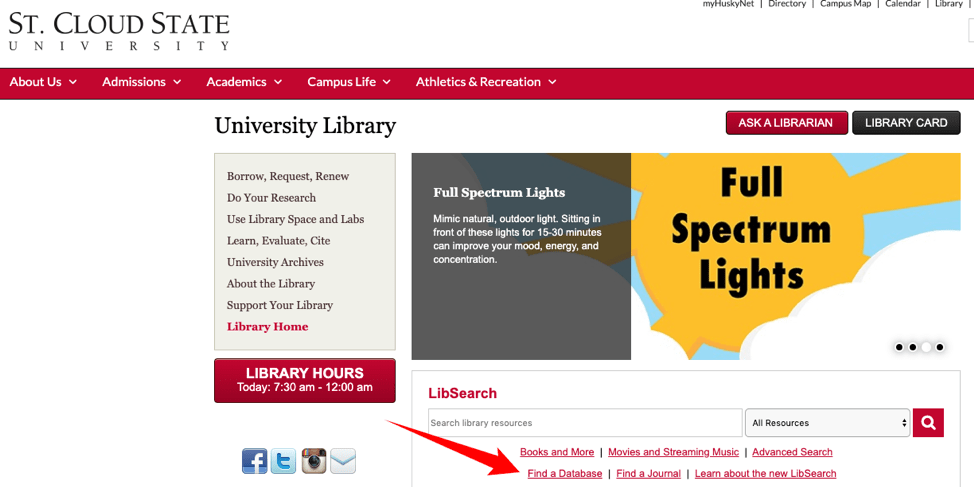
How to find the SCSU Library Website
SCSU online databases
SCSU Library Web page
Basic Research Skills
Locating and Defining a Database
Database Searching Overview:
You can search using the SCSU library online dbases by choosing:
Simple search
Advanced search
Identifying a Scholarly Source
Boolean operators
Databases:
CINAHL, MEDLINE, PubMed, Health Source: Consumer Edition, Health Source: Nursing/Academic Edition
Psychology:
PsychINFO
General Science
ScienceDirect
Arts & Humanities Citation Index
How do you evaluate a source of information to determine if it is appropriate for academic/scholarly use. There is no set “checklist” to complete but below are some criteria to consider when you are evaluating a source.
ACCURACY
Does the author cite reliable sources?
How does the information compare with that in other works on the topic?
Can you determine if the information has gone through peer-review?
Are there factual, spelling, typographical, or grammatical errors?
AUDIENCE
Who do you think the authors are trying to reach?
Is the language, vocabulary, style and tone appropriate for intended audience?
What are the audience demographics? (age, educational level, etc.)
Are the authors targeting a particular group or segment of society?
AUTHORITY
Who wrote the information found in the article or on the site?
What are the author’s credentials/qualifications for this particular topic?
Is the author affiliated with a particular organization or institution?
What does that affiliation suggest about the author?
CURRENCY
Is the content current?
Does the date of the information directly affect the accuracy or usefulness of the information?
OBJECTIVITY/BIAS
What is the author’s or website’s point of view?
Is the point of view subtle or explicit?
Is the information presented as fact or opinion?
If opinion, is the opinion supported by credible data or informed argument?
Is the information one-sided?
Are alternate views represented?
Does the point of view affect how you view the information?
PURPOSE
What is the author’s purpose or objective, to explain, provide new information or news, entertain, persuade or sell?
Does the purpose affect how you view the information presented?
JSON is a semi-structured data format for encoding data and is a popular language for data sharing and interchange – as such it is considered a good alternative to XML. This materials in this course will cover all the core JSON syntax and data structures as well as:
– structured data as a concept
– core data structuring approaches
– the differences between XML and JSON
– when to use XML, when to use JSON
Robert Chavez holds a PhD in Classical Studies from Indiana University. From 1994-1999 he worked in the Library Electronic Text Resource Service at Indiana University Bloomington as an electronic text specialist. From 1999-2007 Robert worked at Tufts University at the Perseus Project and the Digital Collections and Archives as a programmer, digital humanist, and institutional repository program manager. He currently works for the New England Journal of Medicine as Content Applications Architect.
Course Structure
This is an online class that is taught asynchronously, meaning that participants do the work on their own time as their schedules allow. The class does not meet together at any particular times, although the instructor may set up optional synchronous chat sessions. Instruction includes readings and assignments in one-week segments. Class participation is in an online forum environment.
according to Pew Research Center, 68 percent of American adults get their news from social media—platforms where opinion is often presented as fact.
results of the international test revealed that only 14 percent of U.S. students were able to reliably distinguish between fact and opinion.
News and Media Literacy (and the lack of) is not very different from Information Literacy
An “information literate” student is able to “locate, evaluate, and effectively use information from diverse sources.” See more About Information Literacy.
How does information literacy help me?
Every day we have questions that need answers. Where do we go? Whom can we trust? How can we find information to help ourselves? How can we help our family and friends? How can we learn about the world and be a better citizen? How can we make our voice heard?
Standard 1. The information literate student determines the nature and extent of the information needed
Standard 2. The information literate student accesses needed information effectively and efficiently
Standard 3. The information literate student evaluates information and its sources critically and incorporates selected information into his or her knowledge base and value system
Standard 4. The information literate student, individually or as a member of a group, uses information effectively to accomplish a specific purpose
Standard 5. The information literate student understands many of the economic, legal, and social issues surrounding the use of information and accesses and uses information ethically and legally
Project Information Literacy
A national, longitudinal research study based in the University of Washington’s iSchool, compiling data on college students habits to seek and use information.
+++++++++++++++++++++++
Developing Your Research Topic/Question
Research always starts with a question. But the success of your research also depends on how you formulate that question. If your topic is too broad or too narrow, you may have trouble finding information when you search. When developing your question/topic, consider the following:
Research always starts with a question. But the success of your research also depends on how you formulate that question. If your topic is too broad or too narrow, you may have trouble finding information when you search. When developing your question/topic, consider the following:
Is my question one that is likely to have been researched and for which data have been published? Believe it or not, not every topic has been researched and/or published in the literature.
Be flexible. Consider broadening or narrowing the topic if you are getting a limited number or an overwhelming number of results when you search. In nursing it can be helpful to narrow by thinking about a specific population (gender, age, disease or condition, etc.), intervention, or outcome.
Discuss your topic with your professor and be willing to alter your topic according to the guidance you receive.
Getting Ready for Research
Library Resources vs. the Internet
How (where from) do you receive information about your professional interests?
Advantages/disadvantages of using Web Resources
Why Keyword Searching?
Why not just type in a phrase or sentence like you do in Google or Yahoo!?
Because most electronic databases store and retrieve information differently than Internet search engines.
A databases searches fields within a collection of records. These fields include the information commonly found in a citation plus an abstract (if available) and subject headings. Search engines search web content which is typically the full text of sources.
The bottom line: you get better results in a database by using effective keyword search strategies.
To develop an effective search strategy, you need to:
determine the key concepts in your topic and
develop a good list of keyword synonyms.
Why use synonyms?
Because there is more than one way to express a concept or idea. You don’t know if the article you’re looking for uses the same expression for a key concept that you are using.
Consider: Will an author use:
Hypertension or High Blood Pressure?
Teach or Instruct?
Therapy or Treatment?
Don’t get “keyword lock!” Be willing to try a different term as a keyword. If you are having trouble thinking of synonyms, check a thesaurus, dictionary, or reference book for ideas.
Keyword worksheet
Library Resources
How to find the SCSU Library Website
SCSU online databases
SCSU Library Web page
Basic Research Skills
Locating and Defining a Database
Database Searching Overview:
You can search using the SCSU library online dbases by choosing:
Simple search
Advanced search
Identifying a Scholarly Source
Boolean operators
Databases:
CINAHL, MEDLINE, PubMed, Health Source: Consumer Edition, Health Source: Nursing/Academic Edition
Psychology:
PsychINFO
General Science
ScienceDirect
Arts & Humanities Citation Index
How do you evaluate a source of information to determine if it is appropriate for academic/scholarly use. There is no set “checklist” to complete but below are some criteria to consider when you are evaluating a source.
ACCURACY
Does the author cite reliable sources?
How does the information compare with that in other works on the topic?
Can you determine if the information has gone through peer-review?
Are there factual, spelling, typographical, or grammatical errors?
AUDIENCE
Who do you think the authors are trying to reach?
Is the language, vocabulary, style and tone appropriate for intended audience?
What are the audience demographics? (age, educational level, etc.)
Are the authors targeting a particular group or segment of society?
AUTHORITY
Who wrote the information found in the article or on the site?
What are the author’s credentials/qualifications for this particular topic?
Is the author affiliated with a particular organization or institution?
What does that affiliation suggest about the author?
CURRENCY
Is the content current?
Does the date of the information directly affect the accuracy or usefulness of the information?
OBJECTIVITY/BIAS
What is the author’s or website’s point of view?
Is the point of view subtle or explicit?
Is the information presented as fact or opinion?
If opinion, is the opinion supported by credible data or informed argument?
Is the information one-sided?
Are alternate views represented?
Does the point of view affect how you view the information?
PURPOSE
What is the author’s purpose or objective, to explain, provide new information or news, entertain, persuade or sell?
Does the purpose affect how you view the information presented?
Author Rights and Publishing & Finding Author Instructions for Publishing in Scholarly Journals
Plagiarism, academic honesty
Writing Tips
Dissemination of Research
++++++++++++++++++++++++++++++++++++++++++++++
Class Assignment:
Research on Disability – Middle Childhood
There are many interactions between childhood development and mental, physical, and socioemotional health – namely including interpersonal relationships and the child’s relationship with education. Using SCSU’s University Library, find a journal article that will help you learn more about a developmental abnormality (a disability) that relates to middle childhood. Make sure your chosen article includes the following:
1) the article focuses on one or includes participants with a disability
2) the population (or part of the population) being studied is within the life stage of middle childhood (defined as ages 6-12)
3) the article is empirical (peer-reviewed)
Use the article to respond to the following questions.
What is the title of the article?
In what journal was the article published?
What was the purpose of the study?
What were the methods? In particular, who were the participants?
What were the results?
What are two important facts/ideas/issues you learned about middle childhood and disability by reading this article?
according to Pew Research Center, 68 percent of American adults get their news from social media—platforms where opinion is often presented as fact.
results of the international test revealed that only 14 percent of U.S. students were able to reliably distinguish between fact and opinion.
News and Media Literacy (and the lack of) is not very different from Information Literacy
An “information literate” student is able to “locate, evaluate, and effectively use information from diverse sources.” See more About Information Literacy.
How does information literacy help me?
Every day we have questions that need answers. Where do we go? Whom can we trust? How can we find information to help ourselves? How can we help our family and friends? How can we learn about the world and be a better citizen? How can we make our voice heard?
Standard 1. The information literate student determines the nature and extent of the information needed
Standard 2. The information literate student accesses needed information effectively and efficiently
Standard 3. The information literate student evaluates information and its sources critically and incorporates selected information into his or her knowledge base and value system
Standard 4. The information literate student, individually or as a member of a group, uses information effectively to accomplish a specific purpose
Standard 5. The information literate student understands many of the economic, legal, and social issues surrounding the use of information and accesses and uses information ethically and legally
Project Information Literacy
A national, longitudinal research study based in the University of Washington’s iSchool, compiling data on college students habits to seek and use information.
+++++++++++++++++++++++
Developing Your Research Topic/Question
Research always starts with a question. But the success of your research also depends on how you formulate that question. If your topic is too broad or too narrow, you may have trouble finding information when you search. When developing your question/topic, consider the following:
Research always starts with a question. But the success of your research also depends on how you formulate that question. If your topic is too broad or too narrow, you may have trouble finding information when you search. When developing your question/topic, consider the following:
Is my question one that is likely to have been researched and for which data have been published? Believe it or not, not every topic has been researched and/or published in the literature.
Be flexible. Consider broadening or narrowing the topic if you are getting a limited number or an overwhelming number of results when you search. In nursing it can be helpful to narrow by thinking about a specific population (gender, age, disease or condition, etc.), intervention, or outcome.
Discuss your topic with your professor and be willing to alter your topic according to the guidance you receive.
Getting Ready for Research
Library Resources vs. the Internet
How (where from) do you receive information about your professional interests?
Advantages/disadvantages of using Web Resources
Why Keyword Searching?
Why not just type in a phrase or sentence like you do in Google or Yahoo!?
Because most electronic databases store and retrieve information differently than Internet search engines.
A databases searches fields within a collection of records. These fields include the information commonly found in a citation plus an abstract (if available) and subject headings. Search engines search web content which is typically the full text of sources.
The bottom line: you get better results in a database by using effective keyword search strategies.
To develop an effective search strategy, you need to:
determine the key concepts in your topic and
develop a good list of keyword synonyms.
Why use synonyms?
Because there is more than one way to express a concept or idea. You don’t know if the article you’re looking for uses the same expression for a key concept that you are using.
Consider: Will an author use:
Hypertension or High Blood Pressure?
Teach or Instruct?
Therapy or Treatment?
Don’t get “keyword lock!” Be willing to try a different term as a keyword. If you are having trouble thinking of synonyms, check a thesaurus, dictionary, or reference book for ideas.
Keyword worksheet
Library Resources
How to find the SCSU Library Website
SCSU online databases
SCSU Library Web page
Basic Research Skills
Locating and Defining a Database
Database Searching Overview:
You can search using the SCSU library online dbases by choosing:
Simple search
Advanced search
Identifying a Scholarly Source
Boolean operators
Databases:
CINAHL, MEDLINE, PubMed, Health Source: Consumer Edition, Health Source: Nursing/Academic Edition
Psychology:
PsychINFO
General Science
ScienceDirect
Arts & Humanities Citation Index
How do you evaluate a source of information to determine if it is appropriate for academic/scholarly use. There is no set “checklist” to complete but below are some criteria to consider when you are evaluating a source.
ACCURACY
Does the author cite reliable sources?
How does the information compare with that in other works on the topic?
Can you determine if the information has gone through peer-review?
Are there factual, spelling, typographical, or grammatical errors?
AUDIENCE
Who do you think the authors are trying to reach?
Is the language, vocabulary, style and tone appropriate for intended audience?
What are the audience demographics? (age, educational level, etc.)
Are the authors targeting a particular group or segment of society?
AUTHORITY
Who wrote the information found in the article or on the site?
What are the author’s credentials/qualifications for this particular topic?
Is the author affiliated with a particular organization or institution?
What does that affiliation suggest about the author?
CURRENCY
Is the content current?
Does the date of the information directly affect the accuracy or usefulness of the information?
OBJECTIVITY/BIAS
What is the author’s or website’s point of view?
Is the point of view subtle or explicit?
Is the information presented as fact or opinion?
If opinion, is the opinion supported by credible data or informed argument?
Is the information one-sided?
Are alternate views represented?
Does the point of view affect how you view the information?
PURPOSE
What is the author’s purpose or objective, to explain, provide new information or news, entertain, persuade or sell?
Does the purpose affect how you view the information presented?
LITA listserv exchange on “Raspberry PI Counter for Library Users”
On 7/10/20, 10:05 AM, “lita-l-request@lists.ala.org on behalf of Hammer, Erich F” <lita-l-request@lists.ala.org on behalf of erich@albany.edu> wrote:
Jason,
I think that is a very interesting project. If I understand how it works (comparing reference images to live images), it should still work if a “fuzzy” or translucent filter were placed on the lens as a privacy measure, correct? You could even make the fuzzy video publicly accessible to prove to folks that privacy is protected.
If that’s the case, IMHO, it really is a commercially viable idea and it would have a market far beyond libraries. Open source code and hardware designs and sales of pre-packaged hardware and support. Time for some crowdsource funding! 🙂
My note:
In 2018, following the university president’s call for ANY possible savings, the library administrator was send a proposal requesting information regarding the license for the current library counters and proposing the save the money for the license by creating an in-house Arduino counter. The blueprints for such counter were share (as per another LITA listserv exchange). SCSU Physics professor agreement to lead the project was secured as well as the opportunity for SCSU Physics students to develop the project as part of their individual study plan. The proposal was never addressed neither by the middle nor the upper management.
Bibliographical data analysis with Zotero and nVivo
Bibliographic Analysis for Graduate Students, EDAD 518, Fri/Sat, May 15/16, 2020
This session will not be about qualitative research (QR) only, but rather about a modern 21st century approach toward the analysis of your literature review in Chapter 2.
However, the computational approach toward qualitative research is not much different than computational approach for your quantitative research; you need to be versed in each of them, thus familiarity with nVivo for qualitative research and with SPSS for quantitative research should be pursued by any doctoral student.
Once you complete the overview of the resources above, please make sure you have Zotero working on your computer; we will be reviewing the Zotero features before we move to nVivo.
Familiarity with Zotero is a prerequisite for successful work with nVivo, so please if you are already working with Zotero, try to expand your knowledge using the materials above.
Please use this link to install nVivo on your computer. Even if we were not in a quarantine and you would have been able to use the licensed nVivo software on campus, for convenience (working on your dissertation from home), most probably, you would have used the shareware. Shareware is fully functional on your computer for 14 days, so calculate the time you will be using it and mind the date of installation and your consequent work.
For the purpose of this workshop, please install nVivo on your computer early morning on Saturday, May 16, so we can work together on nVivo during the day and you can continue using the software for the next two weeks.
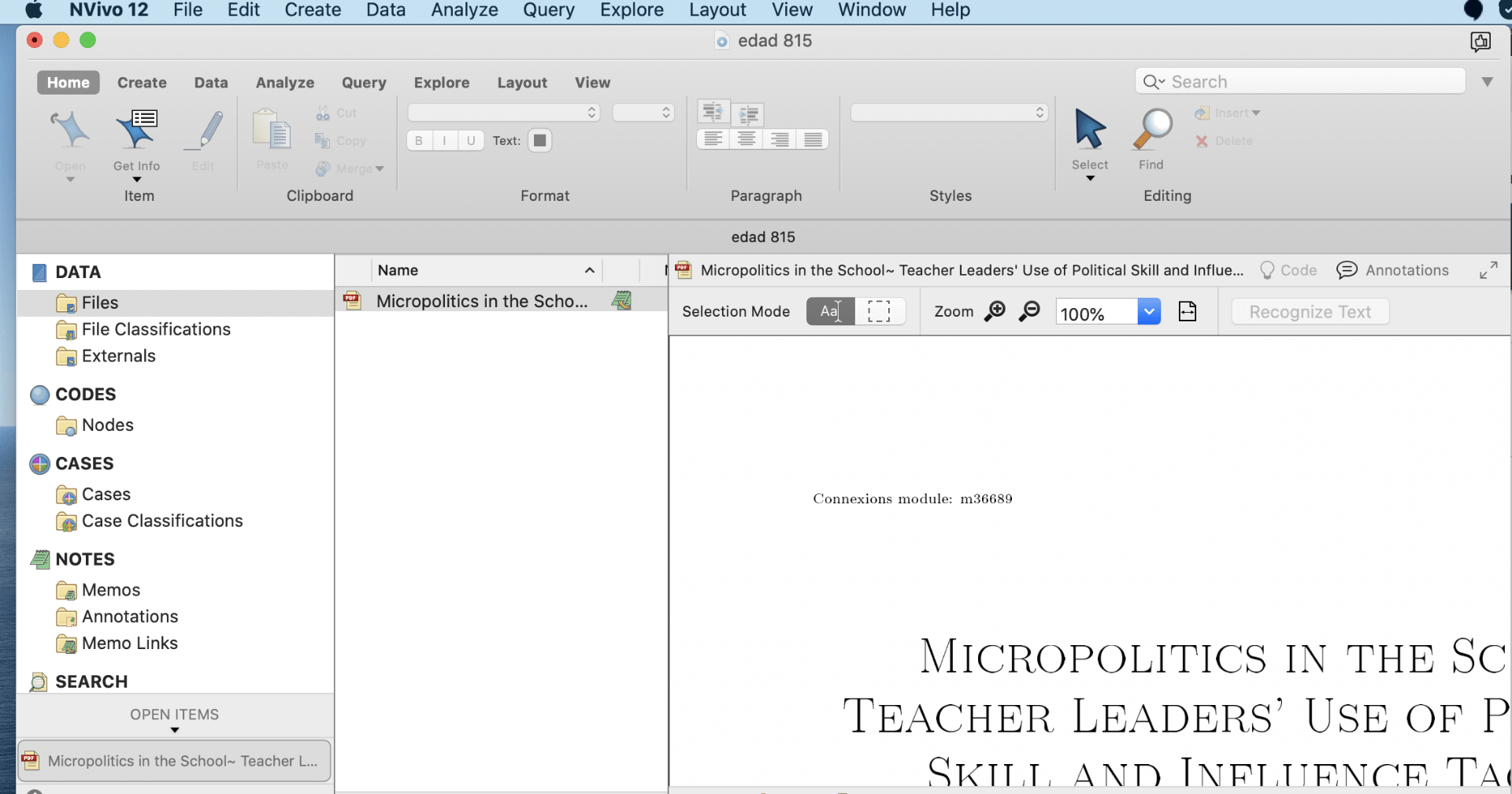
Please familiarize yourself with the two articles assigned in the EDAD 815 D2L course content “Practice Research Articles“ :
Brosky, D. (2011). Micropolitics in the School: Teacher Leaders’ Use of Political Skill and Influence Tactics. International Journal of Educational Leadership Preparation, 6(1). https://eric.ed.gov/?id=EJ972880
Tooms, A. K., Kretovics, M. A., & Smialek, C. A. (2007). Principals’ perceptions of politics. International Journal of Leadership in Education, 10(1), 89–100. https://doi.org/10.1080/13603120600950901
It is very important to be familiar with the articles when we start working with nVivo.
whereas the snapshots are replaced with snapshots from nVivol, version 12, which we will be using in our course and for our dissertations.
Concept of bibliographic data
Bibliographic Data is an organized collection of references to publish in literature that includes journals, magazine articles, newspaper articles, conference proceedings, reports, government and legal publications. The bibliographical data is important for writing the literature review of a research. This data is usually saved and organized in databases like Mendeley or Endnote. Nvivo provides the option to import bibliographical data from these databases directly. One can import End Note library or Mendeley library into Nvivo. Similar to interview transcripts, one can represent and analyze bibliographical data using Nvivo. To start with bibliographical data representation, this article previews the processing of literature review in Nvivo.
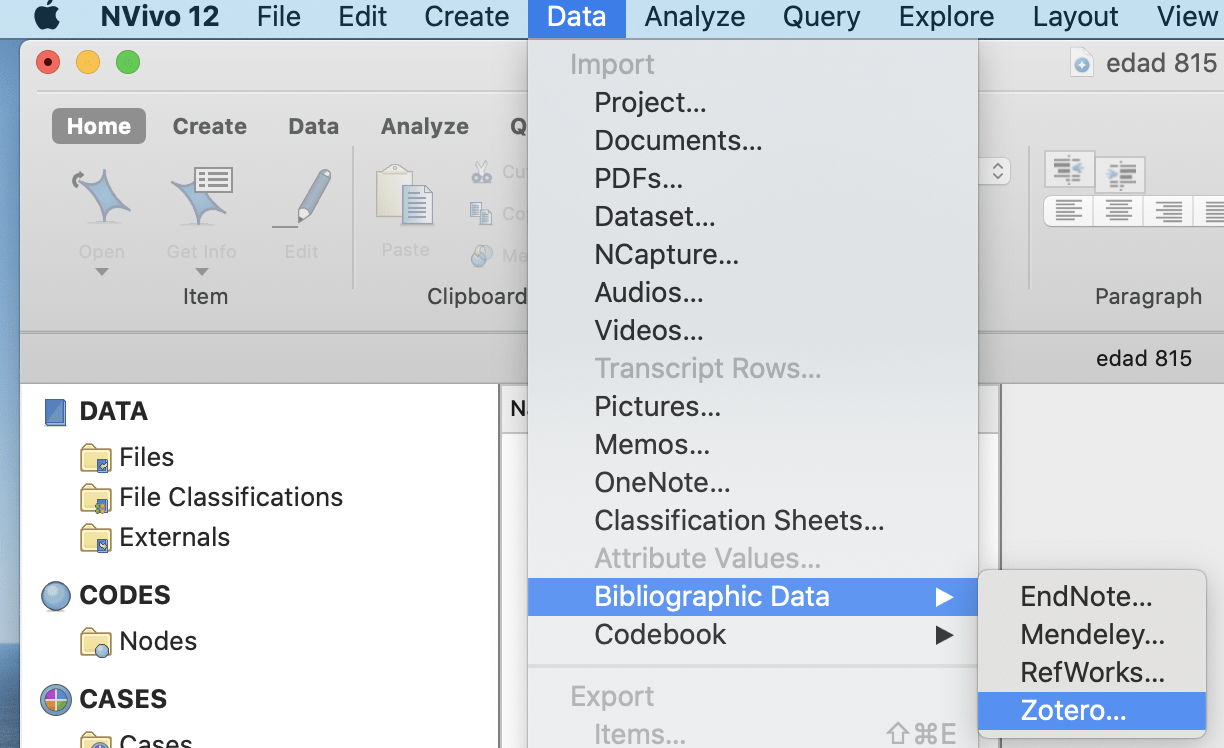
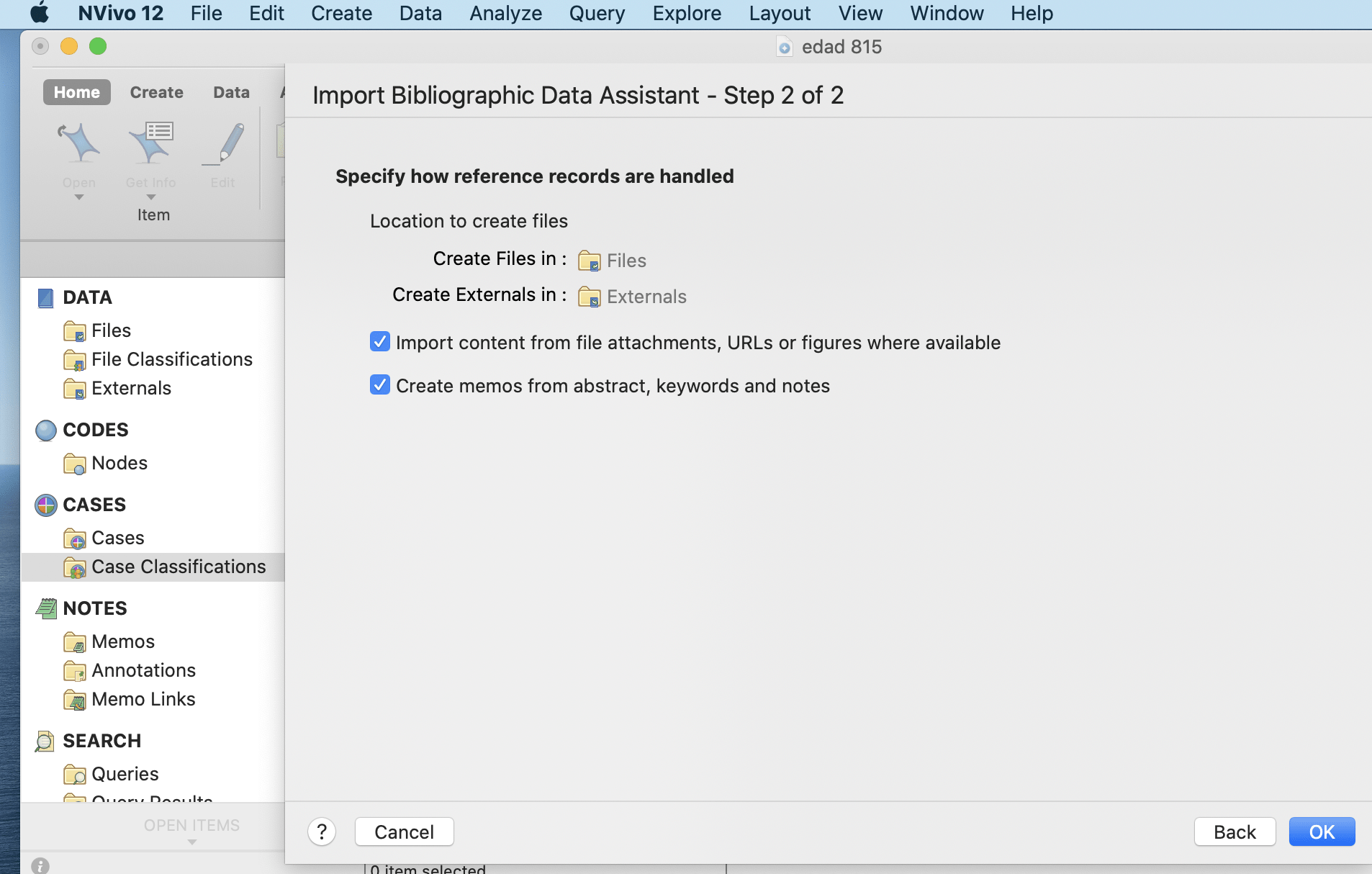
Importing bibliographical data
Bibliographic Data is imported using Mendeley, Endnote and other such databases or applications that are supported with Nvivo. Bibliographical data here refers to material in the form of articles, journals or conference proceedings. Common factors among all of these data are the author’s name and year of publication. Therefore, Nvivo helps to import and arrange these data with their titles as author’s name and year of publication. The process of importing bibliographical data is presented in the figures below.
select the appropriate data from external folder
Coding strategies for literature review
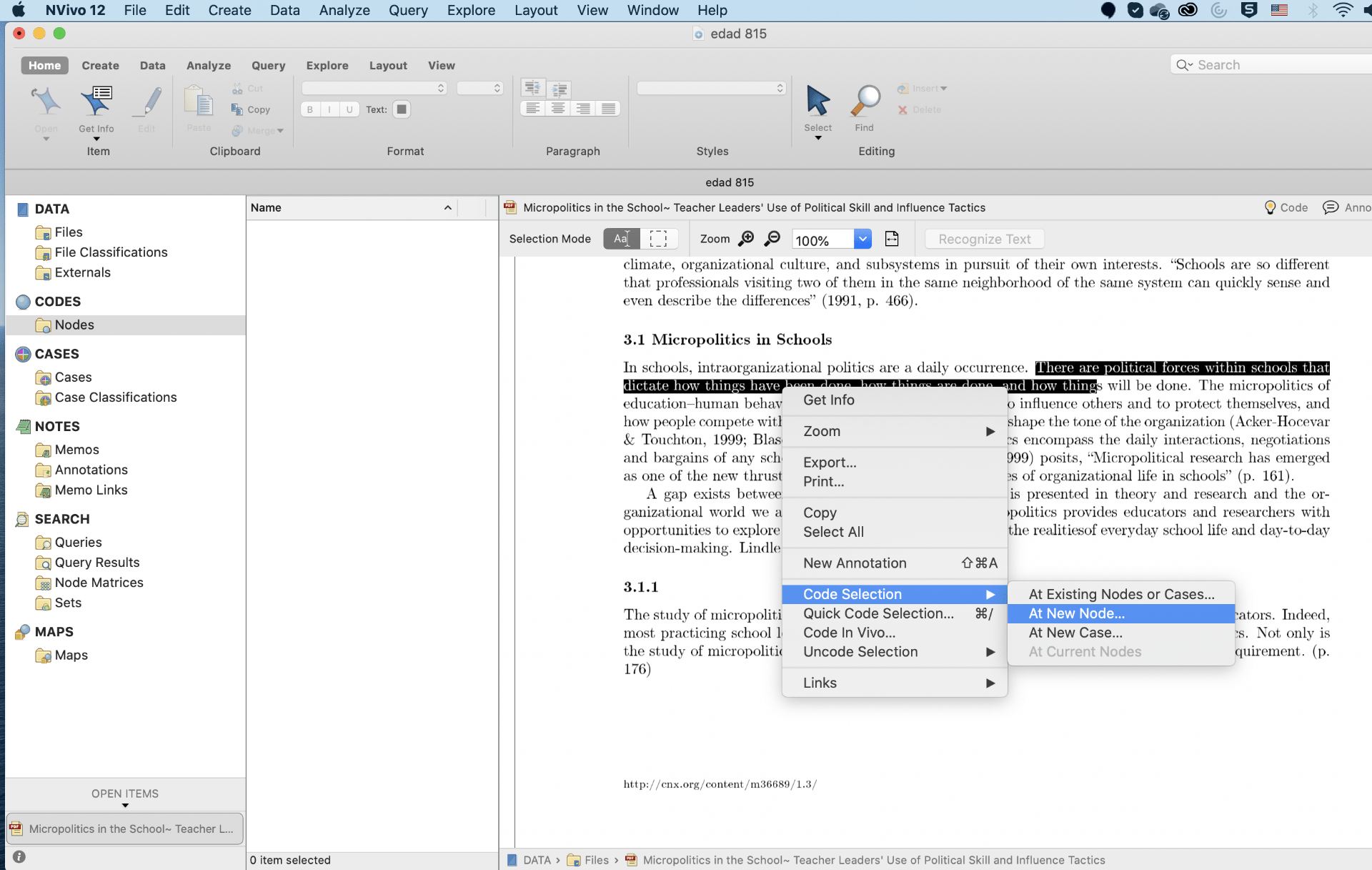
Coding is a process of identifying important parts or patterns in the sources and organizing them in theme node. Sources in case of literature review include material in the form of PDF. That means literature review in Nvivo requires grouping of information from PDF files in the forms of theme nodes. Nodes directly do not create content for literature review, they present ideas simply to help in framing a literature review. Nodes can be created on the basis of theme of the study, results of the study, major findings of the study or any other important information of the study. After creating nodes, code the information of each of the articles into its respective codes.
Nvivo allows coding the articles for preparing a literature review. Articles have tremendous amount of text and information in the forms of graphs, more importantly, articles are in the format of PDF. Since Nvivo does not allow editing PDF files, apply manual coding in case of literature review. There are two strategies of coding articles in Nvivo.
Code the text of PDF files into a new Node.
Code the text of PDF file into an existing Node. The procedure of manual coding in literature review is similar to interview transcripts.
The Case Nodes of articles are created as per the author name or year of the publication.
For example: Create a case node with the name of that author and attach all articles in case of multiple articles of same Author in a row with different information. For instance in figure below, five articles of same author’s name, i.e., Mr. Toppings have been selected together to group in a case Node. Prepare case nodes like this then effortlessly search information based on different author’s opinion for writing empirical review in the literature.
Nvivo questions for literature review
Apart from the coding on themes, evidences, authors or opinions in different articles, run different queries based on the aim of the study. Nvivo contains different types of search tools that helps to find information in and across different articles. With the purpose of literature review, this article presents a brief overview of word frequency search, text search, and coding query in Nvivo.
Word frequency
Word frequency in Nvivo allows searching for different words in the articles. In case of literature review, use word frequency to search for a word. This will help to find what different author has stated about the word in the article. Run word frequency on all types of sources and limit the number of words which are not useful to write the literature.
For example, run the command of word frequency with the limit of 100 most frequent words . This will help in assessing if any of these words remotely provide any new information for the literature (figure below).
and
and
Text search
Text search is more elaborative tool then word frequency search in Nvivo. It allows Nvivo to search for a particular phrase or expression in the articles. Also, Nvivo gives the opportunity to make a node out of text search if a particular word, phrase or expression is found useful for literature.
For example: conduct a text search query to find a word “Scaffolding” in the articles. In this case Nvivo will provide all the words, phrases and expression slightly related to this word across all the articles (Figure 8 & 9). The difference between test search and word frequency lies in generating texts, sentences and phrases in the latter related to the queried word.
Coding query
Apart from text search and word frequency search Nvivo also provides the option of coding query. Coding query helps in literature review to know the intersection between two Nodes. As mentioned previously, nodes contains the information from the articles. Furthermore it is also possible that two nodes contain similar set of information. Therefore, coding query helps to condense this information in the form of two way table which represents the intersection between selected nodes.
For example, in below figure, researcher have search the intersection between three nodes namely, academics, psychological and social on the basis of three attributes namely qantitative, qualitative and mixed research. This coding theory is performed to know which of the selected themes nodes have all types of attributes. Like, Coding Matrix in figure below shows that academic have all three types of attributes that is research (quantitative, qualitative and mixed). Where psychological has only two types of attributes research (quantitative and mixed).
In this way, Coding query helps researchers to generate intersection between two or more theme nodes. This also simplifies the pattern of qualitative data to write literature.
+++++++++++++++++++
Please do not hesitate to contact me with questions, suggestions before, during or after our workshop and about ANY questions and suggestions you may have about your Chapter 2 and, particularly about your literature review: