Using Social Media for Research – November 16 12:00 – 1:00 p.m.
1314 Social Sciences
Professor Lee-Ann Kastman Breuch (Writing Studies) and Michael Beckstrand (Mixed-Methods Research Associate, LATIS) will discuss how to retrieve, prepare, and analyze social media data for research projects. Using two case studies, Lee-Ann will share examples of a grounded theory analysis of blog, Twitter, and Facebook data. Michael will speak about the technical aspects of retrieving and managing social media data. Pizza will be provided. Learn more and register here.
This event is part of the 2018-19 Research Development Friday Roundtable Series organized by the CLA Research Development Team.
Cross-Institution & Cross-Sector Collaboration Long-Term Trend: Driving Ed Tech adoption in higher education for five or more years
Although a variety of collaborations between higher education and industry have emerged, more-explicit frameworks and guidelines are needed to define how these partnerships should proceed to have the greatest impact.
Proliferation of Open Educational Resources Mid-Term Trend: Driving Ed Tech adoption in higher education for the next three to five years
The United States lags on the policy front. In September 2017, the Affordable College Textbook Act was once again introduced in both the US House of Representatives and the Senate “to expand the use of open textbooks
It is unlikely that ACTA will pass, however, as it has been unsuccessfully introduced to two previous Congresses.
The Rise of New Forms of Interdisciplinary Studies
Faculty members, administrators, and instructional designers are creating innovative pathways to college completion through interdisciplinary experiences, nanodegrees, and other alternative credentials, such as digital badges. Researchers, along with academic technologists and developers, are breaking new ground with data structures, visualizations, geospatial applications, and innovative uses of opensource tools.
Growing Focus on Measuring Learning
As societal and economic factors redefine the skills needed in today’s workforce, colleges and universities must rethink how to define, measure, and demonstrate subject mastery and soft skills such as creativity and collaboration. The proliferation of data-mining software and developments in online education, mobile learning, and learning management systems are coalescing toward learning environments that leverage analytics and visualization software to portray learning data in a multidimensional and portable manner
Redesigning Learning Spaces
upgrading wireless bandwidth and installing large displays that allow for more natural collaboration on digital projects. Some are exploring how mixed-reality technologies can blend 3D holographic content into physical spaces for simulations, such as experiencing Mars by controlling rover vehicles, or how they can enable multifaceted interaction with objects, such as exploring the human body in anatomy labs through detailed visuals. As higher education continues to move away from traditional, lecture-based lessons toward more hands-on activities, classrooms are starting to resemble real-world work and social environments
Authentic Learning Experiences
An increasing number of institutions have begun bridging the gap between academic knowledge and concrete applications by establishing relationships with the broader community; through active partnerships with local organizations
Improving Digital Literacy Solvable Challenge: Those that we understand and know how to solve
Digital literacy transcends gaining discrete technological skills to generating a deeper understanding of the digital environment, enabling intuitive and discerning adaptation to new contexts and cocreation of content.107 Institutions are charged with developing students’ digital citizenship, promoting the responsible and appropriate use of technology, including online communication etiquette and digital rights and responsibilities in blended and online learning settings. This expanded concept of digital competence is influencing curriculum design, professional development, and student-facing services and resources. Due to the multitude of elements of digital literacy, higher education leaders must obtain institution-wide buy-in and provide support for all stakeholders in developing these competencies.
Despite its growing importance, it remains a complex topic that can be challenging to pin down. Vanderbilt University established an ad hoc group of faculty, administrators, and staff that created a working definition of digital literacy on campus and produced a white paper recommending how to implement digital literacy to advance the university’s mission: https://vanderbilt.edu/ed-tech/committees/digital-literacy-committee.php
Adapting Organizational Designs to the Future of Work
Technology, shifting information demands, and evolving faculty roles are forcing institutions to rethink the traditional functional hierarchy. Institutions must adopt more flexible, teambased, matrixed structures to remain innovative and responsive to campus and stakeholder needs.
Attempts to avoid bureaucracy also align with a streamlined workforce and cost elimination. Emphasis has been placed on designing better business models through a stronger focus on return on investment. This involves taking a strategic approach that connects financial practice (such as analyzing cost metrics and resource allocation) with institutional change models and goals.124
Faculty roles have been and continue to be impacted by organizational change, as well as by broader economic movements. Reflective of today’s “gig economy,” twothirds of faculty members are now non-tenure, with half working part-time, often in teaching roles at several institutions. This stands as a stark contrast to 1969, when almost 80 percent of faculty were tenured or tenuretrack; today’s figures are nearly inverted. Their wages are applying pressure to traditional organizational structures.Rethinking tenure programs represents another change to organizational designs that aligns with the future of work.
Organizational structures are continuing to evolve on the administrative side as well. With an emphasis on supporting student success, many institutions are rethinking their student services, which include financial aid, academic advising, and work-study programs. Much of this change is happening within the context of digital transformation, an umbrella term that denotes the transformation of an organization’s core business to better meet customer needs by leveraging technology and data.
+++++++++
added Nov 13, 2018
6 growing trends taking over academic libraries
BY MERIS STANSBURY
March 24th, 2017
Horizon Report details short-and long-term technologies, trends that will impact academic libraries worldwide in the next 5 years.
Research Data Management: The growing availability of research reports through online library databases is making it easier for students, faculty, and researchers to access and build upon existing ideas and work. “Archiving the observations that lead to new ideas has become a critical part of disseminating reports,” says the report.
Valuing the User Experience: Librarians are now favoring more user-centric approaches, leveraging data on patron touchpoints to identify needs and develop high-quality engaging experiences.
(Mid-Term, 3-5 years):
Patrons as Creators: Students, faculty, and researchers across disciplines are learning by making and creating rather than by simply consuming content. Creativity, as illustrated by the growth of user-generated videos, maker communities, and crowdfunded projects in the past few years, is increasingly the means for active, hands-on learning. People now look to libraries to assist them and provide tools for skill-building and making.
Rethinking Library Spaces: At a time when discovery can happen anywhere, students are relying less on libraries as the sole source for accessing information and more for finding a place to be productive. As a result, institutional leaders are starting to reflect on how the design of library spaces can better facilitate the face-to-face interactions.
(Long-Term, 5 or more years):
Cross-Institution Collaboration: Within the current climate of shrinking budgets and increased focus on digital collections, collaborations enable libraries to improve access to scholarly materials and engage in mission-driven cooperative projects.
Evolving Nature of the Scholarly Record: Once limited to print-based journals and monographic series, scholarly communications now reside in networked environments and can be accessed through an expansive array of publishing platforms. “As different kinds of scholarly communication are becoming more prevalent on the web, librarians are expected to discern the legitimacy of these innovative approaches and their impact in the greater research community through emerging altmetrics tools,” notes the report.
Improving digital literacy: According to the report, digital literacy transcends gaining isolated technological skills to “generate a deeper understanding of the digital environment, enabling intuitive adaptation to new contexts, co-creation of content with others, and an awareness of both the freedom and risks that digital interactions entail. Libraries are positioned to lead efforts to develop students’ digital citizenship, ensuring mastery of responsible and appropriate technology use, including online identity, communication etiquette, and rights and responsibilities.”
In April, a PLAYlive Nation lounge in Tracy, Calif., hosted its first Fortnite tournament and sold out. Hundreds of players bought tickets to play against one another and win prizes.
Joost van Dreunen, the CEO of Superdata Research, a video game analytics firm, says most shooter games are serious and simulate violence. Fortnite, he says, is more like a friendly game of tag.
His company estimates the game has made about $223 million across all platforms in March alone. In lifetime sales, it had made about $614 million. The game is free to play, but Epic Games, the company that owns Fortnite, makes money through microtransactions. Players can spend real money to make cosmetic changes to their characters in the game. They can buy things like skins, which are like costumes, for their characters or emotes, which are celebratory dance moves their characters can do after winning or killing another player in the game.
Ninja, the gamer name taken by 26-year-old Tyler Blevins, is now a legend in the Fortnite world. He is a master at the game and rocketed into popularity after playing in an online battle with rap artists Drake and Travis Scott on March 14. That battle has been watched more than 9 million times.
++++++++++++++++++++
Educators Battle ‘Fortnite’ for Students’ Attention
Many educators want to ban the game from their classrooms, but some are taking the opposite approach, attempting to weave students’ interest in Fortnite into class discussions and assignments.
Nick Fisher, a science teacher at Fort Zumwalt North High School in O’Fallon, Mo., said his students like to take screenshots of gameplay and send them to friends over Snapchat. Teenagers want to broadcast their victories, and because the game is on their phones, it’s easy to post updates to social media, making Fortnite “the perfect concoction of addiction,” said Fisher.
North High blocks all social media and gaming sites on its WiFi, said Fisher, but students tell him how they circumvent the restriction: They use virtual private networks, or VPNs, to establish independent internet connections. (Dozens of YouTube videos provide step-by-step tutorials for students looking to get around school WiFi controls.)
“Kids can’t multitask,” she said. “Even having a digital device within sight can cognitively distract the student enough that they can’t focus on the academics.”
Schools and teachers should be guiding parents when it comes to appropriate limits around screen time, said Kolb. Most parents will appreciate research-based recommendations, such as turning off all screens a set amount of time before bed, she said.
Games like Fortnite can even have social benefits, said John Velez, an assistant professor of journalism and electronic media at Texas Tech University. Velez, who studies the positive effects of video games, has found that playing violent games cooperatively with helpful teammates promotes pro-social behavior.
Chris Aviles, the coordinator of innovation, technology, and 21st century skills for the Fair Haven Public Schools in New Jersey, wrote “A Teacher’s Guide to Surviving Fortnite,” an exploration of ways the game can be used for instructional purposes. The guide, posted to his blog Teched Up Teacher, suggests how to integrate the game into writing prompts, math lessons on probability, and physics.
Aviles doesn’t advocate playing the game at school. There isn’t any educational value in letting students engage in virtual combat during a lesson, he said. Instead, teachers can build a lesson around one aspect of the game, such as having students calculate the best angle of approach as they jump from the “Battle Bus,” the floating bus that drops players onto the map at the beginning of each match.
++++++++++++++++++
Instagram, Snapchat, Fortnite: The distractions are endless. Here’s how to help kids cope.
In January, two of Apple’s shareholder groups asked the company to look at the addictive effects of iPhones on children. Google’s recent developer conference highlighted tools to help users better control smartphone usage.
A 2015 survey of more than 1,800 teachers and 400 principals in Alberta, B.C., found that nearly three-fourths of teachers frequently or very frequently observed students multitasking with technology, and 67 percent of teachers believed that the number of students negatively distracted by digital technologies in the classroom was growing.
The best approach is to use empathy, compassion and collaboration to help the young people in your life find ways to manage their digital workflow.
Encourage visualization for inspiration and motivation. The first step is getting students to buy in and to want to make behavioral changes.
Focus on compartmentalization. A 2009 study from Stanford researchers found that people who juggled several streams of electronic information were not able to pay attention, remember key information or switch tasks as effectively as those who completed one task at a time.
Using the Pomodoro technique of spending 25 minutes focused on one task followed by a five-minute break can be an easy way to have students begin to shift from a multitasking to a monotasking mind-set.
Make focus fun. There are now numerous ways to use technology to help us be more productive with technology, and it doesn’t have to be arduous. Students in my office use apps such as Forest or Flipd to motivate them to stay off their phones during class or when doing homework. Forest has a simple interface that will build a digital tree for users who stay off their phones. Flipd allows users to hide certain apps, allot time off their phone based on their schedule and, for a premium, track their progress over time.
Provide structured support as needed. A middle school student with whom I worked recently was relieved when his mother used the Mac OS app SelfControl to block YouTube and ESPN while he was doing his homework (Cold Turkey is a similar PC-based app).
Allow opportunities for regrouping. Even the best plans can go awry (for adults and kids alike). It’s important to focus on progress rather than perfection. Create time daily or weekly for students to think about what went well in terms of managing distractions and improving productivity, and what they would like to do better. Ask open-ended questions without judgment or expectation
The key campus tech issues are no longer about IT (in the past e.g.: MS versus Apple). IT is the “easy part” of technology on campus. The challenges: people, planning policy, programs, priorities, silos, egos, and IT entitlements
How do we make Digital Learning compelling and safe for the faculty? provide evidence of impact, support, recognition and reward for faculty; communicate about effectiveness of and need for IT resources.
technology is not capital cost, it is operational cost. reoccurring.
Visualization:
underlying issues; can i do this? why should i do this? evidence of benefit?
the more things change, the more things stay the same. new equilibrium.
change: from what did you do wrong to how do we do better. Use data as a resources, not as a weapon. there is a fear of trying, because there is no recognition or reward
Machiavelli: 1. concentrate your efforts 2. pick your issues carefully, know when to fight 3. know the history 4. build coalitions 5. set modest goals – and realistic 6. leverage the value of data (use it as resource not weapon) 7. anticipate personnel turnover 8. set deadlines for decisions
Colleagues,
We apologize for the short notice, but wanted to make you aware of the following opportunity: provide
From Ken Graetz at Winona State University:
As part of our Digital Faculty Fellows Program at WSU, Dr. Kenneth C. Green will be speaking this Thursday, March 22nd in Stark 103 Miller Auditorium from 11:30 to 12:30 on “Innovation, Infrastructure, and Digital Learning.” We will be streaming Casey’s talk using Skype Meeting Broadcast and you can join as a guest using the following link: Join the presentation. This will allow you to see and hear his presentation, as well as post moderated questions. By way of a teaser, here is a recent quote from Dr. Green’s blog, DigitalTweed, published by Inside Higher Ed:
“If trustees, presidents, provosts, deans, and department chairs really want to address the fear of trying and foster innovation in instruction, then they have to recognize that infrastructure fosters innovation. And infrastructure, in the context of technology and instruction, involves more than just computer hardware, software, digital projectors in classrooms, learning management systems, and campus web sites. The technology is actually the easy part. The real challenges involve a commitment to research about the impact of innovation in instruction, and recognition and reward for those faculty who would like to pursue innovation in their instructional activities.”
Dr. Green is the founding director of The Campus Computing Project, the largest continuing study of the role of digital learning and information technology in American colleges and universities. Campus Computing is widely cited as a definitive source for data, information, and insight about IT planning and policy issues affecting higher education. Dr. Green also serves as the director, moderator, and co-producer of TO A DEGREE, the postsecondary success podcast of the Bill & Melinda Gates Foundation. He is the author or editor of some 20 books and published research reports and more than 100 articles and commentaries that have appeared in academic journals and professional publications. In 2002, Dr. Green received the first EDUCAUSE Award for Leadership in Public Policy and Practice. The EDUCAUSE award cites his work in creating The Campus Computing Project and recognizes his, “prominence in the arena of national and international technology agendas, and the linking of higher education to those agendas.”
Effective communication is one critical characteristics of effective and successful school principal. Research on effective schools and instructional leadership emphasizes the impact of principal leadership on creating safe and secure learning environment and positive nurturing school climate (Halawah, 2005, p. 334)
Halawah, I. (2005). The Relationship between Effective Communication of High School Principal and School Climate. Education, 126(2), 334-345.
Selection of school principals in Hong Kong. The findings confirm a four-factor set of expectations sought from applicants; these are Generic Managerial Skills; Communication and Presentation Skills; Knowledge and Experience; and Religious Value Orientation.
Kwan, P. (2012). Assessing school principal candidates: perspectives of the hiring superintendents. International Journal Of Leadership In Education, 15(3), 331-349. doi:10.1080/13603124.2011.617838
Yee, D. L. (2000). Images of school principals’ information and communications technology leadership. Journal of Information Technology for Teacher Education, 9(3), 287–302. https://doi.org/10.1080/14759390000200097
Catano, N., & Stronge, J. H. (2007). What do we expect of school principals? Congruence between principal evaluation and performance standards. International Journal of Leadership in Education, 10(4), 379–399. https://doi.org/10.1080/13603120701381782
Communication can consist of two large areas:
broadcasting information: PR, promotions, notifications etc.
two-way communication: collecting feedback, “office hours” type of communication, backchanneling, etc.
Further communication initiated by/from principals can have different audiences
Reyes, P., & Hoyle, D. (1992). Teachers’ Satisfaction With Principals’ Communication. The Journal of Educational Research, 85(3), 163–168. https://doi.org/10.1080/00220671.1992.9944433
parents: involvement, feeling of empowerment, support, volunteering
students
board members
community
Epstein, J. L. (1995). School/family/community partnerships – ProQuest. Phi Delta Kappan, 76(9), 701.
Others
Communication and Visualization
The ever-growing necessity to be able to communicate data to different audiences in digestible format.
considering the information discussed in class, split in groups of 4 and develop your institution strategy for effective and modern communication across and out of your school.
University libraries have held collections of books and printed material throughout their existence and continue to be perceived as repositories for physical collections. Other non-print specialized collections of interest have been held in various departments on campus such as Anthropology, Art, and Biology due to the unique needs of the collections and their usage. With the advent of electronic media, it becomes possible to store these non-print collections in a central place, such as the Libray.
The skills needed to curate artifacts from an archeological excavation, biological specimens from various life forms, and sculpture work are very different, making it difficult for smaller university libraries to properly hold, curate, and make available such collections. In addition, faculty in the various departments tend to want those collections near their coursework and research, so it can be readily available to students and researchers. With the expansion of online learning, the need for such availability becomes increasingly pronounced.
With the advent of 3 dimensional (3D) scanners, it has become possible for a smaller library to hold digital representations of these collections in an archive that can be curated from the various departments by experts in the discipline. The Library can then make the digital representations available to other researchers, students, and the public through kiosks in the Library or via the Internet. Current methods to scan and store an artifact in 3Dstill require expertise not often found in a Library.
We propose to use existing technology to build an easy-to-use system to scan smaller artifacts in 3D. The project will include purchase and installation of a workstation in the Library where the artifact collection can be accessed using a large touch-screen monitor, and a portable, easy-to-use 3D scanning station. Curators of collections from various departments on the St. Cloud State University campus can check out the scanning station, connect to power and Internet where the collection is located, and scan their collection into the libraries digital archives, making the collection easily available to students, other researchers and the public.
The project would include assembly of two workstations previously mentioned and potentially develop the robotic scanner. Software would be produced to automate the workflow from the scanner to archiving the digital representation and then make the collection available on the Internet.
This project would be a collaboration between the St. Cloud State University Library (https://www.stcloudstate.edu/library/ and Visualization Laboratory (https://www.facebook.com/SCSUVizLab/). The project would use the expertise and services of the St. Cloud State Visualization Laboratory. Dr. Plamen Miltenoff, a faculty with the Library will coordinate the Library initiatives related to the use of the 3D scanner. Mark Gill, Visualization Engineer, and Dr. Mark Petzold, Associate Professor of Electrical and Computer Engineering will lead a group of students in developing the software to automate the scanning, storage, and retrieval of the 3D models. The Visualization Lab has already had success in 3D scanning objects for other departments and in creating interactive displays allowing retrieval of various digital content, including 3D scanned objects such animal skulls and video. A collaboration between the Library, VizLab and the Center for Teaching and Learning (, https://www.stcloudstate.edu/teaching/) will enable campus faculty to overcome technical and financial obstacles. It will promote the VizLab across campus, while sharing its technical resources with the Library and making those resources widely available across campus. Such work across silos will expose the necessity (if any) of standardization and will help faculty embrace stronger collaborative practices as well as spur the process of reproduction of best practices across disciplines.
Budget:
Hardware
Cost
42” Touch Screen Monitor
$2200
Monitor Mount
$400
2 Computer Workstations
$5000
Installation
$500
Cart for Mobile 3D Scanner
$1000
3D Scanner (either purchase or develop in-house)
$2000
Total
$11100
The budget covers two computer workstations. One will be installed in the library as a way to access the digital catalog, and will include a 42 inch touch screen monitor mounted to a wall or stand. This installation will provide students a way to interact with the models in a more natural way. The second workstation would be mounted on a mobile cart and connected to the 3D scanner. This would allow collection curators from different parts of campus to check out the scanner and scan their collections. The ability to bring the scanner to the collection would increase the likelihood the collections to be scanned into the library collection.
The 3D scanner would either be purchased off-the shelf or designed by a student team from the Engineering Department. A solution will be sought to use and minimize the amount of training the operator would need. If the scanner is developed in-house, a simple optical scanner such as an XBox Kinect device and a turntable or robotic arm will be used. Support for the XBox Kinect is built into Microsoft Visual Studio, thus creating the interface efficient and costeffective.
Dr. Miltenoff is part of a workgroup within the academic library, which works with faculty, students and staff on the application of new technologies in education. Dr. Miltenoff’s most recent research with Mark Gill is on the impact of Video 360 on students during library orientation:http://web.stcloudstate.edu/pmiltenoff/bi/
Mark Petzold, Ph.D. mcpetzold@stcloudstate.edu
320-308-4182
Dr. Petzold is an Associate Professor in Electrical and Computer Engineering. His current projects involve visualization of meteorological data in a virtual reality environment and research into student retention issues. He is co-PI on a $5 million NSF S-STEM grant which gives scholarships to low income students and investigates issues around student transitions to college.
Mr. Gill is a Visualization Engineer for the College of Science and Engineering and runs the Visualization Laboratory. He has worked for several major universities as well as Stennis Space Center and Mechdyne, Inc. He holds a Masters of Science in Software Engineering.
+++++++++++++
University of Nevada, Reno and Pennsylvania State University 41 campus libraries to include collaborative spaces where faculty and students gather to transform virtual ideas into reality.
Maker Commons in the Modern Library 6 REASONS 3D PRINTERS SHOULD BE IN YOUR LIBRARY
1. Librarians Know How to Share 2. Librarians Work Well with IT People 3. Librarians Serve Everybody 4. Librarians Can Fill Learning Gaps 5. Librarians like Student Workers 6. Librarians are Cross-Discipline
How algorithms impact our browsing behavior? browsing history? What is the connection between social media algorithms and fake news? Are there topic-detection algorithms as they are community-detection ones?
How can I change the content of a [Google] search return? Can I?
Massanari, A. (2017). #Gamergate and The Fappening: How Reddit’s algorithm, governance, and culture support toxic technocultures. New Media & Society, 19(3), 329-346. doi:10.1177/1461444815608807
CRUZ, J. D., BOTHOREL, C., & POULET, F. (2014). Community Detection and Visualization in Social Networks: Integrating Structural and Semantic Information. ACM Transactions On Intelligent Systems & Technology, 5(1), 1-26. doi:10.1145/2542182.2542193
Bai, X., Yang, P., & Shi, X. (2017). An overlapping community detection algorithm based on density peaks. Neurocomputing, 2267-15. doi:10.1016/j.neucom.2016.11.019
Zeng, J., & Zhang, S. (2009). Incorporating topic transition in topic detection and tracking algorithms. Expert Systems With Applications, 36(1), 227-232. doi:10.1016/j.eswa.2007.09.013
Zhou, E., Zhong, N., & Li, Y. (2014). Extracting news blog hot topics based on the W2T Methodology. World Wide Web, 17(3), 377-404. doi:10.1007/s11280-013-0207-7
The W2T (Wisdom Web of Things) methodology considers the information organization and management from the perspective of Web services, which contributes to a deep understanding of online phenomena such as users’ behaviors and comments in e-commerce platforms and online social networks. (https://link.springer.com/chapter/10.1007/978-3-319-44198-6_10)
ethics of algorithm
Mittelstadt, B. D., Allo, P., Taddeo, M., Wachter, S., & Floridi, L. (2016). The ethics of algorithms: Mapping the debate. Big Data & Society, 3(2), 2053951716679679. https://doi.org/10.1177/2053951716679679
Significant Challenges Impeding Technology Adoption in K–12 Education
Improving Digital Literacy.
Schools are charged with developing students’ digital citizenship, ensuring mastery of responsible and appropriate technology use, including online etiquette and digital rights and responsibilities in blended and online learning settings. Due to the multitude of elements comprising digital literacy, it is a challenge for schools to implement a comprehensive and cohesive approach to embedding it in curricula.
Rethinking the Roles of Teachers.
Pre-service teacher training programs are also challenged to equip educators with digital and social–emotional competencies, such as the ability to analyze and use student data, amid other professional requirements to ensure classroom readiness.
p. 28 Improving Digital Literacy
Digital literacy spans across subjects and grades, taking a school-wide effort to embed it in curricula. This can ensure that students are empowered to adapt in a quickly changing world
Education Overview: Digital Literacy Has to Encompass More Than Social Use
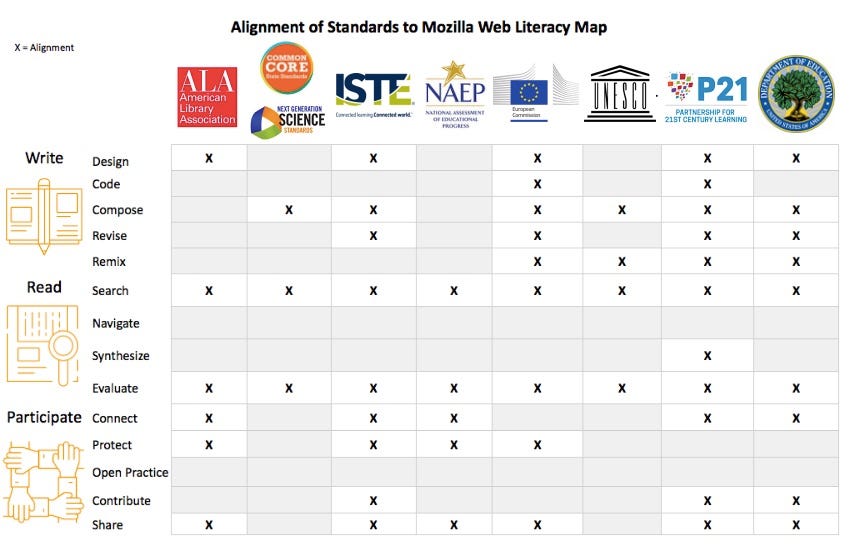
The American Library Association (ALA) defines digital literacy as “the ability to use information and communication technologies to find, evaluate, create, and communicate or share information, requiring both cognitive and technical skills.” While the ALA’s definition does align to some of the skills in “Participate”, it does not specifically mention the skills related to the “Open Practice.”
The library community’s digital and information literacy standards do not specifically include the coding, revision and remixing of digital content as skills required for creating digital information. Most digital content created for the web is “dynamic,” rather than fixed, and coding and remixing skills are needed to create new content and refresh or repurpose existing content. Leaving out these critical skills ignores the fact that library professionals need to be able to build and contribute online content to the ever-changing Internet.
p. 30 Rethinking the Roles of Teachers
Teachers implementing new games and software learn alongside students, which requires
a degree of risk on the teacher’s part as they try new methods and learn what works
p. 32 Teaching Computational Thinking
p. 36 Sustaining Innovation through Leadership Changes
shift the role of teachers from depositors of knowledge to mentors working alongside students;
p. 38 Important Developments in Educational Technology for K–12 Education
Consumer technologies are tools created for recreational and professional purposes and were not designed, at least initially, for educational use — though they may serve well as learning aids and be quite adaptable for use in schools.
Drones > Real-Time Communication Tools > Robotics > Wearable Technology
Digital strategies are not so much technologies as they are ways of using devices and software to enrich teaching and learning, whether inside or outside the classroom.
> Games and Gamification > Location Intelligence > Makerspaces > Preservation and Conservation Technologies
Enabling technologies are those technologies that have the potential to transform what we expect of our devices and tools. The link to learning in this category is less easy to make, but this group of technologies is where substantive technological innovation begins to be visible. Enabling technologies expand the reach of our tools, making them more capable and useful
Affective Computing > Analytics Technologies > Artificial Intelligence > Dynamic Spectrum and TV White Spaces > Electrovibration > Flexible Displays > Mesh Networks > Mobile Broadband > Natural User Interfaces > Near Field Communication > Next Generation Batteries > Open Hardware > Software-Defined Networking > Speech-to-Speech Translation > Virtual Assistants > Wireless Powe
Internet technologies include techniques and essential infrastructure that help to make the technologies underlying how we interact with the network more transparent, less obtrusive, and easier to use.
Bibliometrics and Citation Technologies > Blockchain > Digital Scholarship Technologies > Internet of Things > Syndication Tools
Learning technologies include both tools and resources developed expressly for the education sector, as well as pathways of development that may include tools adapted from other purposes that are matched with strategies to make them useful for learning.
Adaptive Learning Technologies > Microlearning Technologies > Mobile Learning > Online Learning > Virtual and Remote Laboratories
Social media technologies could have been subsumed under the consumer technology category, but they have become so ever-present and so widely used in every part of society that they have been elevated to their own category.
Crowdsourcing > Online Identity > Social Networks > Virtual Worlds
Visualization technologies run the gamut from simple infographics to complex forms of visual data analysis
3D Printing > GIS/Mapping > Information Visualization > Mixed Reality > Virtual Reality
p. 46 Virtual Reality
p. 48 AI
p. 50 IoT
+++++++++++++++
more on NMC Horizon Reports in this IMS blog
But it gets even more interesting when virtual and augmented reality meet the Internet of Things
when Second Life began, there was a lot of interest, but the toolset was limited — just because of the timeframe, not that the toolset wasn’t a good one for that period. But, things matured. I think it was, in particular, the ability to work in HD that improved things a lot. Then came the ability to bring in datasets — creating dashboards and ways for people to access other data that they could bring into the virtual reality experiment. I think those two things were real forces for change.
A dashboard could pop up, and you could select among several tools, and you could get a feed from somewhere on the Internet — maybe a video or a presentation. And you can use these things as you move through this hyper reality: The datasets you select can be manipulated and be part of the entire experience.
So, the hyper reality experience became deeper, richer with tools and data via the IoT; and with HD it became more real.
We can’t deny the fact that curriculum and the way we teach is becoming unbundled. Some things are going to happen online and in the virtual space, and other things will happen in the classroom. And the expense of education is going to drive how we operate. Virtual reality tools, augmented reality tools, and visualization tools can offer experiences that can be mass-produced and sent out to lots of students, machine to machine, at a lower cost. Virtual field trips and other kinds of virtual learning experiences will become much more commonplace in the next 5 years.