05
Jan
2018
Jan
2018
replacement for common phrases
categories: information literacy

+++++++++++++++
more on proofreading in this IMS blog
https://blog.stcloudstate.edu/ims?s=proofreading
Digital Literacy for St. Cloud State University
+++++++++++++++
more on proofreading in this IMS blog
https://blog.stcloudstate.edu/ims?s=proofreading
Please have an FAQ-kind of list of the Google Group postings regarding resources and information on research and writing of Chapter 2
digital resource sets available through MnPALS Plus
https://blog.stcloudstate.edu/ims/2017/10/21/digital-resource-sets-available-through-mnpals-plus/
+++++++++++++++++++++++++
[how to] write chapter 2
You were reminded to look at dissertations of your peers from previous cohorts and use their dissertations as a “template”: http://repository.stcloudstate.edu/do/discipline_browser/articles?discipline_key=1230
You also were reminded to use the documents in Google Drive: e.g. https://drive.google.com/open?id=0B7IvS0UYhpxFVTNyRUFtNl93blE
Please have also materials, which might help you organize our thoughts and expedite your Chapter 2 writing….
Do you agree with (did you use) the following observations:
The purpose of the review of the literature is to prove that no one has studied the gap in the knowledge outlined in Chapter 1. The subjects in the Review of Literature should have been introduced in the Background of the Problem in Chapter 1. Chapter 2 is not a textbook of subject matter loosely related to the subject of the study. Every research study that is mentioned should in some way bear upon the gap in the knowledge, and each study that is mentioned should end with the comment that the study did not collect data about the specific gap in the knowledge of the study as outlined in Chapter 1.
The review should be laid out in major sections introduced by organizational generalizations. An organizational generalization can be a subheading so long as the last sentence of the previous section introduces the reader to what the next section will contain. The purpose of this chapter is to cite major conclusions, findings, and methodological issues related to the gap in the knowledge from Chapter 1. It is written for knowledgeable peers from easily retrievable sources of the most recent issue possible.
Empirical literature published within the previous 5 years or less is reviewed to prove no mention of the specific gap in the knowledge that is the subject of the dissertation is in the body of knowledge. Common sense should prevail. Often, to provide a history of the research, it is necessary to cite studies older than 5 years. The object is to acquaint the reader with existing studies relative to the gap in the knowledge and describe who has done the work, when and where the research was completed, and what approaches were used for the methodology, instrumentation, statistical analyses, or all of these subjects.
If very little literature exists, the wise student will write, in effect, a several-paragraph book report by citing the purpose of the study, the methodology, the findings, and the conclusions. If there is an abundance of studies, cite only the most recent studies. Firmly establish the need for the study. Defend the methods and procedures by pointing out other relevant studies that implemented similar methodologies. It should be frequently pointed out to the reader why a particular study did not match the exact purpose of the dissertation.
The Review of Literature ends with a Conclusion that clearly states that, based on the review of the literature, the gap in the knowledge that is the subject of the study has not been studied. Remember that a “summary” is different from a “conclusion.” A Summary, the final main section, introduces the next chapter.
from http://dissertationwriting.com/wp/writing-literature-review/
Here is the template from a different school (then SCSU)
http://semo.edu/education/images/EduLead_DissertGuide_2007.pdf
+++++++++++++++++
When conducting qualitative data, how many people should be interviewed? Is there a minimum or a max
Here is my take on it:
Simple question, not so simple answer.
It depends.
Generally, the number of respondents depends on the type of qualitative inquiry: case study methodology, phenomenological study, ethnographic study, or ethnomethodology. However, a rule of thumb is for scholars to achieve saturation point–that is the point in which no fresh information is uncovered in response to an issue that is of interest to the researcher.
If your qualitative method is designed to meet rigor and trustworthiness, thick, rich data is important. To achieve these principles you would need at least 12 interviews, ensuring your participants are the holders of knowledge in the area you intend to investigate. In grounded theory you could start with 12 and interview more if your data is not rich enough.
In IPA the norm tends to be 6 interviews.
You may check the sample size in peer reviewed qualitative publications in your field to find out about popular practice. In all depends on the research problem, choice of specific qualitative approach and theoretical framework, so the answer to your question will vary from few to few dozens.
How many interviews are needed in a qualitative research?
There are different views in literature and no one agreed to the exact number. Here I reviewed some mostly cited references. Based Creswell (2014), it is estimated that 16 participants will provide rich and detailed data. There are a couple of researchers agreed on 10–15 in-depth interviews are sufficient (Guest, Bunce & Johnson 2006; Baker & Edwards 2012).
your methodological choices need to reflect your ontological position and understanding of knowledge production, and that’s also where you can argue a strong case for smaller qualitative studies, as you say. This is not only a problem for certain subjects, I think it’s a problem in certain departments or journals across the board of social science research, as it’s a question of academic culture.
here more serious literature and research (in case you need to cite in Chapter 3)
Sample Size and Saturation in PhD Studies Using Qualitative Interviews
http://www.qualitative-research.net/index.php/fqs/article/view/1428/3027
https://researcholic.wordpress.com/2015/03/20/sample_size_interviews/
Gaskell, George (2000). Individual and Group Interviewing. In Martin W. Bauer & George Gaskell (Eds.), Qualitative Researching With Text, Image and Sound. A Practical Handbook (pp. 38-56). London: SAGE Publications.
Lieberson, Stanley 1991: “Small N’s and Big Conclusions.” Social Forces 70:307-20. (http://www.jstor.org/pss/2580241)
Savolainen, Jukka 1994: “The Rationality of Drawing Big Conclusions Based on Small Samples.” Social Forces 72:1217-24. (http://www.jstor.org/pss/2580299).
Small, M.(2009) ‘How many cases do I need ? On science and the logic of case selection in field-based research’ Ethnography 10(1) 5-38
Williams,M. (2000) ‘Interpretivism and generalisation ‘ Sociology 34(2) 209-224
http://james-ramsden.com/semi-structured-interviews-how-many-interviews-is-enough/
+++++++++++++++++
how to start your writing process
If you are a Pinterest user, you are welcome to just sbuscribe to the board:
https://www.pinterest.com/aidedza/doctoral-cohort/
otherwise, I am mirroring the information also in the IMS blog:
https://blog.stcloudstate.edu/ims/2017/08/13/analytical-essay/
+++++++++++++++++++++++++++
APA citing of “unusual” resources
https://blog.stcloudstate.edu/ims/2017/08/06/apa-citation/
+++++++++++++++++++++++
statistical modeling: your guide to Chapter 3
working on your dissertation, namely Chapter 3, you probably are consulting with the materials in this shared folder:
https://drive.google.com/drive/folders/0B7IvS0UYhpxFVTNyRUFtNl93blE?usp=sharing
In it, there is a subfolder, called “stats related materials”
https://drive.google.com/open?id=0B7IvS0UYhpxFcVg3aWxCX0RVams
where you have several documents from the Graduate school and myself to start building your understanding and vocabulary regarding your quantitative, qualitative or mixed method research.
It has been agreed that before you go to the Statistical Center (Randy Kolb), it is wise to be prepared and understand the terminology as well as the basics of the research methods.
Please have an additional list of materials available through the SCSU library and the Internet. They can help you further with building a robust foundation to lead your research:
https://blog.stcloudstate.edu/ims/2017/07/10/intro-to-stat-modeling/
In this blog entry, I shared with you:
I (and the future cohorts) will deeply appreciate if you remember to share those “suitable sources for your learning style” either by sharing in this Google Group thread and/or sharing in the comments section of the blog entry: https://blog.stcloudstate.edu/ims/2017/07/10/intro-to-stat-modeling. Your Facebook group page is also a good place to discuss among ourselves best practices to learn and use research methods for your chapter 3.
++++++++++++++++
search for sources
Google just posted on their Facebook profile a nifty short video on Google Search
https://blog.stcloudstate.edu/ims/2017/06/26/google-search/
Watching the video, you may remember the same #BooleanSearch techniques from our BI (bibliography instruction) session of last semester.
Considering the fact of preponderance of information in 2017: your Chapter 2 is NOT ONLY about finding information regrading your topic.
Your Chapter 2 is about proving your extensive research of the existing literature.
The techniques presented in the short video will arm you with methods to dig deeper and look further.
If you would like to do a decent job exploring all corners of the vast area called Internet, please consider other search engines similar to Google Scholar:
Microsoft Semantic Scholar (Semantic Scholar); Microsoft Academic Search; Academicindex.net; Proquest Dialog; Quetzal; arXiv;
https://www.google.com/; https://scholar.google.com/ (3 min); http://academic.research.microsoft.com/; http://www.dialog.com/; http://www.quetzal-search.info; http://www.arXiv.org; http://www.journalogy.com/
More about such search engines in the following blog entries:
https://blog.stcloudstate.edu/ims/2017/01/19/digital-literacy-for-glst-495/
and
https://blog.stcloudstate.edu/ims/2017/05/01/history-becker/
Let me know, if more info needed and/or you need help embarking on the “deep” search
+++++++++++++++++
tips for writing and proofreading
please have several infographics to help you with your writing habits (organization) and proofreading, posted in the IMS blog:
https://blog.stcloudstate.edu/ims/2017/06/11/writing-first-draft/
https://blog.stcloudstate.edu/ims/2017/06/11/prewriting-strategies/
https://blog.stcloudstate.edu/ims/2017/06/11/essay-checklist/
++++++++++++++
letter – request copyright permission
Here are several samples on mastering such letter:
https://brocku.ca/webfm_send/25032
+++++++++++++++++
Applications for the 2018 Institute will be accepted between December 1, 2017 and January 27, 2018. Scholars accepted to the program will be notified in early March 2018.
Title:
Learning to Harness Big Data in an Academic Library
Abstract (200)
Research on Big Data per se, as well as on the importance and organization of the process of Big Data collection and analysis, is well underway. The complexity of the process comprising “Big Data,” however, deprives organizations of ubiquitous “blue print.” The planning, structuring, administration and execution of the process of adopting Big Data in an organization, being that a corporate one or an educational one, remains an elusive one. No less elusive is the adoption of the Big Data practices among libraries themselves. Seeking the commonalities and differences in the adoption of Big Data practices among libraries may be a suitable start to help libraries transition to the adoption of Big Data and restructuring organizational and daily activities based on Big Data decisions.
Introduction to the problem. Limitations
The redefinition of humanities scholarship has received major attention in higher education. The advent of digital humanities challenges aspects of academic librarianship. Data literacy is a critical need for digital humanities in academia. The March 2016 Library Juice Academy Webinar led by John Russel exemplifies the efforts to help librarians become versed in obtaining programming skills, and respectively, handling data. Those are first steps on a rather long path of building a robust infrastructure to collect, analyze, and interpret data intelligently, so it can be utilized to restructure daily and strategic activities. Since the phenomenon of Big Data is young, there is a lack of blueprints on the organization of such infrastructure. A collection and sharing of best practices is an efficient approach to establishing a feasible plan for setting a library infrastructure for collection, analysis, and implementation of Big Data.
Limitations. This research can only organize the results from the responses of librarians and research into how libraries present themselves to the world in this arena. It may be able to make some rudimentary recommendations. However, based on each library’s specific goals and tasks, further research and work will be needed.
Research Literature
“Big data is like teenage sex: everyone talks about it, nobody really knows how to do it, everyone thinks everyone else is doing it, so everyone claims they are doing it…”
– Dan Ariely, 2013 https://www.asist.org/publications/bulletin/aprilmay-2017/big-datas-impact-on-privacy-for-librarians-and-information-professionals/
Big Data is becoming an omnipresent term. It is widespread among different disciplines in academia (De Mauro, Greco, & Grimaldi, 2016). This leads to “inconsistency in meanings and necessity for formal definitions” (De Mauro et al, 2016, p. 122). Similarly, to De Mauro et al (2016), Hashem, Yaqoob, Anuar, Mokhtar, Gani and Ullah Khan (2015) seek standardization of definitions. The main connected “themes” of this phenomenon must be identified and the connections to Library Science must be sought. A prerequisite for a comprehensive definition is the identification of Big Data methods. Bughin, Chui, Manyika (2011), Chen et al. (2012) and De Mauro et al (2015) single out the methods to complete the process of building a comprehensive definition.
In conjunction with identifying the methods, volume, velocity, and variety, as defined by Laney (2001), are the three properties of Big Data accepted across the literature. Daniel (2015) defines three stages in big data: collection, analysis, and visualization. According to Daniel, (2015), Big Data in higher education “connotes the interpretation of a wide range of administrative and operational data” (p. 910) and according to Hilbert (2013), as cited in Daniel (2015), Big Data “delivers a cost-effective prospect to improve decision making” (p. 911).
The importance of understanding the process of Big Data analytics is well understood in academic libraries. An example of such “administrative and operational” use for cost-effective improvement of decision making are the Finch & Flenner (2016) and Eaton (2017) case studies of the use of data visualization to assess an academic library collection and restructure the acquisition process. Sugimoto, Ding & Thelwall (2012) call for the discussion of Big Data for libraries. According to the 2017 NMC Horizon Report “Big Data has become a major focus of academic and research libraries due to the rapid evolution of data mining technologies and the proliferation of data sources like mobile devices and social media” (Adams, Becker, et al., 2017, p. 38).
Power (2014) elaborates on the complexity of Big Data in regard to decision-making and offers ideas for organizations on building a system to deal with Big Data. As explained by Boyd and Crawford (2012) and cited in De Mauro et al (2016), there is a danger of a new digital divide among organizations with different access and ability to process data. Moreover, Big Data impacts current organizational entities in their ability to reconsider their structure and organization. The complexity of institutions’ performance under the impact of Big Data is further complicated by the change of human behavior, because, arguably, Big Data affects human behavior itself (Schroeder, 2014).
De Mauro et al (2015) touch on the impact of Dig Data on libraries. The reorganization of academic libraries considering Big Data and the handling of Big Data by libraries is in a close conjunction with the reorganization of the entire campus and the handling of Big Data by the educational institution. In additional to the disruption posed by the Big Data phenomenon, higher education is facing global changes of economic, technological, social, and educational character. Daniel (2015) uses a chart to illustrate the complexity of these global trends. Parallel to the Big Data developments in America and Asia, the European Union is offering access to an EU open data portal (https://data.europa.eu/euodp/home ). Moreover, the Association of European Research Libraries expects under the H2020 program to increase “the digitization of cultural heritage, digital preservation, research data sharing, open access policies and the interoperability of research infrastructures” (Reilly, 2013).
The challenges posed by Big Data to human and social behavior (Schroeder, 2014) are no less significant to the impact of Big Data on learning. Cohen, Dolan, Dunlap, Hellerstein, & Welton (2009) propose a road map for “more conservative organizations” (p. 1492) to overcome their reservations and/or inability to handle Big Data and adopt a practical approach to the complexity of Big Data. Two Chinese researchers assert deep learning as the “set of machine learning techniques that learn multiple levels of representation in deep architectures (Chen & Lin, 2014, p. 515). Deep learning requires “new ways of thinking and transformative solutions (Chen & Lin, 2014, p. 523). Another pair of researchers from China present a broad overview of the various societal, business and administrative applications of Big Data, including a detailed account and definitions of the processes and tools accompanying Big Data analytics. The American counterparts of these Chinese researchers are of the same opinion when it comes to “think about the core principles and concepts that underline the techniques, and also the systematic thinking” (Provost and Fawcett, 2013, p. 58). De Mauro, Greco, and Grimaldi (2016), similarly to Provost and Fawcett (2013) draw attention to the urgent necessity to train new types of specialists to work with such data. As early as 2012, Davenport and Patil (2012), as cited in Mauro et al (2016), envisioned hybrid specialists able to manage both technological knowledge and academic research. Similarly, Provost and Fawcett (2013) mention the efforts of “academic institutions scrambling to put together programs to train data scientists” (p. 51). Further, Asomoah, Sharda, Zadeh & Kalgotra (2017) share a specific plan on the design and delivery of a big data analytics course. At the same time, librarians working with data acknowledge the shortcomings in the profession, since librarians “are practitioners first and generally do not view usability as a primary job responsibility, usually lack the depth of research skills needed to carry out a fully valid” data-based research (Emanuel, 2013, p. 207).
Borgman (2015) devotes an entire book to data and scholarly research and goes beyond the already well-established facts regarding the importance of Big Data, the implications of Big Data and the technical, societal, and educational impact and complications posed by Big Data. Borgman elucidates the importance of knowledge infrastructure and the necessity to understand the importance and complexity of building such infrastructure, in order to be able to take advantage of Big Data. In a similar fashion, a team of Chinese scholars draws attention to the complexity of data mining and Big Data and the necessity to approach the issue in an organized fashion (Wu, Xhu, Wu, Ding, 2014).
Bruns (2013) shifts the conversation from the “macro” architecture of Big Data, as focused by Borgman (2015) and Wu et al (2014) and ponders over the influx and unprecedented opportunities for humanities in academia with the advent of Big Data. Does the seemingly ubiquitous omnipresence of Big Data mean for humanities a “railroading” into “scientificity”? How will research and publishing change with the advent of Big Data across academic disciplines?
Reyes (2015) shares her “skinny” approach to Big Data in education. She presents a comprehensive structure for educational institutions to shift “traditional” analytics to “learner-centered” analytics (p. 75) and identifies the participants in the Big Data process in the organization. The model is applicable for library use.
Being a new and unchartered territory, Big Data and Big Data analytics can pose ethical issues. Willis (2013) focusses on Big Data application in education, namely the ethical questions for higher education administrators and the expectations of Big Data analytics to predict students’ success. Daries, Reich, Waldo, Young, and Whittinghill (2014) discuss rather similar issues regarding the balance between data and student privacy regulations. The privacy issues accompanying data are also discussed by Tene and Polonetsky, (2013).
Privacy issues are habitually connected to security and surveillance issues. Andrejevic and Gates (2014) point out in a decision making “generated by data mining, the focus is not on particular individuals but on aggregate outcomes” (p. 195). Van Dijck (2014) goes into further details regarding the perils posed by metadata and data to the society, in particular to the privacy of citizens. Bail (2014) addresses the same issue regarding the impact of Big Data on societal issues, but underlines the leading roles of cultural sociologists and their theories for the correct application of Big Data.
Library organizations have been traditional proponents of core democratic values such as protection of privacy and elucidation of related ethical questions (Miltenoff & Hauptman, 2005). In recent books about Big Data and libraries, ethical issues are important part of the discussion (Weiss, 2018). Library blogs also discuss these issues (Harper & Oltmann, 2017). An academic library’s role is to educate its patrons about those values. Sugimoto et al (2012) reflect on the need for discussion about Big Data in Library and Information Science. They clearly draw attention to the library “tradition of organizing, managing, retrieving, collecting, describing, and preserving information” (p.1) as well as library and information science being “a historically interdisciplinary and collaborative field, absorbing the knowledge of multiple domains and bringing the tools, techniques, and theories” (p. 1). Sugimoto et al (2012) sought a wide discussion among the library profession regarding the implications of Big Data on the profession, no differently from the activities in other fields (e.g., Wixom, Ariyachandra, Douglas, Goul, Gupta, Iyer, Kulkami, Mooney, Phillips-Wren, Turetken, 2014). A current Andrew Mellon Foundation grant for Visualizing Digital Scholarship in Libraries seeks an opportunity to view “both macro and micro perspectives, multi-user collaboration and real-time data interaction, and a limitless number of visualization possibilities – critical capabilities for rapidly understanding today’s large data sets (Hwangbo, 2014).
The importance of the library with its traditional roles, as described by Sugimoto et al (2012) may continue, considering the Big Data platform proposed by Wu, Wu, Khabsa, Williams, Chen, Huang, Tuarob, Choudhury, Ororbia, Mitra, & Giles (2014). Such platforms will continue to emerge and be improved, with librarians as the ultimate drivers of such platforms and as the mediators between the patrons and the data generated by such platforms.
Every library needs to find its place in the large organization and in society in regard to this very new and very powerful phenomenon called Big Data. Libraries might not have the trained staff to become a leader in the process of organizing and building the complex mechanism of this new knowledge architecture, but librarians must educate and train themselves to be worthy participants in this new establishment.
Method
The study will be cleared by the SCSU IRB.
The survey will collect responses from library population and it readiness to use and use of Big Data. Send survey URL to (academic?) libraries around the world.
Data will be processed through SPSS. Open ended results will be processed manually. The preliminary research design presupposes a mixed method approach.
The study will include the use of closed-ended survey response questions and open-ended questions. The first part of the study (close ended, quantitative questions) will be completed online through online survey. Participants will be asked to complete the survey using a link they receive through e-mail.
Mixed methods research was defined by Johnson and Onwuegbuzie (2004) as “the class of research where the researcher mixes or combines quantitative and qualitative research techniques, methods, approaches, concepts, or language into a single study” (Johnson & Onwuegbuzie, 2004 , p. 17). Quantitative and qualitative methods can be combined, if used to complement each other because the methods can measure different aspects of the research questions (Sale, Lohfeld, & Brazil, 2002).
Sampling design
Project Schedule
Complete literature review and identify areas of interest – two months
Prepare and test instrument (survey) – month
IRB and other details – month
Generate a list of potential libraries to distribute survey – month
Contact libraries. Follow up and contact again, if necessary (low turnaround) – month
Collect, analyze data – two months
Write out data findings – month
Complete manuscript – month
Proofreading and other details – month
Significance of the work
While it has been widely acknowledged that Big Data (and its handling) is changing higher education (https://blog.stcloudstate.edu/ims?s=big+data) as well as academic libraries (https://blog.stcloudstate.edu/ims/2016/03/29/analytics-in-education/), it remains nebulous how Big Data is handled in the academic library and, respectively, how it is related to the handling of Big Data on campus. Moreover, the visualization of Big Data between units on campus remains in progress, along with any policymaking based on the analysis of such data (hence the need for comprehensive visualization).
This research will aim to gain an understanding on: a. how librarians are handling Big Data; b. how are they relating their Big Data output to the campus output of Big Data and c. how librarians in particular and campus administration in general are tuning their practices based on the analysis.
Based on the survey returns (if there is a statistically significant return), this research might consider juxtaposing the practices from academic libraries, to practices from special libraries (especially corporate libraries), public and school libraries.
References:
Adams Becker, S., Cummins M, Davis, A., Freeman, A., Giesinger Hall, C., Ananthanarayanan, V., … Wolfson, N. (2017). NMC Horizon Report: 2017 Library Edition.
Andrejevic, M., & Gates, K. (2014). Big Data Surveillance: Introduction. Surveillance & Society, 12(2), 185–196.
Asamoah, D. A., Sharda, R., Hassan Zadeh, A., & Kalgotra, P. (2017). Preparing a Data Scientist: A Pedagogic Experience in Designing a Big Data Analytics Course. Decision Sciences Journal of Innovative Education, 15(2), 161–190. https://doi.org/10.1111/dsji.12125
Bail, C. A. (2014). The cultural environment: measuring culture with big data. Theory and Society, 43(3–4), 465–482. https://doi.org/10.1007/s11186-014-9216-5
Borgman, C. L. (2015). Big Data, Little Data, No Data: Scholarship in the Networked World. MIT Press.
Bruns, A. (2013). Faster than the speed of print: Reconciling ‘big data’ social media analysis and academic scholarship. First Monday, 18(10). Retrieved from http://firstmonday.org/ojs/index.php/fm/article/view/4879
Bughin, J., Chui, M., & Manyika, J. (2010). Clouds, big data, and smart assets: Ten tech-enabled business trends to watch. McKinsey Quarterly, 56(1), 75–86.
Chen, X. W., & Lin, X. (2014). Big Data Deep Learning: Challenges and Perspectives. IEEE Access, 2, 514–525. https://doi.org/10.1109/ACCESS.2014.2325029
Cohen, J., Dolan, B., Dunlap, M., Hellerstein, J. M., & Welton, C. (2009). MAD Skills: New Analysis Practices for Big Data. Proc. VLDB Endow., 2(2), 1481–1492. https://doi.org/10.14778/1687553.1687576
Daniel, B. (2015). Big Data and analytics in higher education: Opportunities and challenges. British Journal of Educational Technology, 46(5), 904–920. https://doi.org/10.1111/bjet.12230
Daries, J. P., Reich, J., Waldo, J., Young, E. M., Whittinghill, J., Ho, A. D., … Chuang, I. (2014). Privacy, Anonymity, and Big Data in the Social Sciences. Commun. ACM, 57(9), 56–63. https://doi.org/10.1145/2643132
De Mauro, A. D., Greco, M., & Grimaldi, M. (2016). A formal definition of Big Data based on its essential features. Library Review, 65(3), 122–135. https://doi.org/10.1108/LR-06-2015-0061
De Mauro, A., Greco, M., & Grimaldi, M. (2015). What is big data? A consensual definition and a review of key research topics. AIP Conference Proceedings, 1644(1), 97–104. https://doi.org/10.1063/1.4907823
Dumbill, E. (2012). Making Sense of Big Data. Big Data, 1(1), 1–2. https://doi.org/10.1089/big.2012.1503
Eaton, M. (2017). Seeing Library Data: A Prototype Data Visualization Application for Librarians. Publications and Research. Retrieved from http://academicworks.cuny.edu/kb_pubs/115
Emanuel, J. (2013). Usability testing in libraries: methods, limitations, and implications. OCLC Systems & Services: International Digital Library Perspectives, 29(4), 204–217. https://doi.org/10.1108/OCLC-02-2013-0009
Graham, M., & Shelton, T. (2013). Geography and the future of big data, big data and the future of geography. Dialogues in Human Geography, 3(3), 255–261. https://doi.org/10.1177/2043820613513121
Harper, L., & Oltmann, S. (2017, April 2). Big Data’s Impact on Privacy for Librarians and Information Professionals. Retrieved November 7, 2017, from https://www.asist.org/publications/bulletin/aprilmay-2017/big-datas-impact-on-privacy-for-librarians-and-information-professionals/
Hashem, I. A. T., Yaqoob, I., Anuar, N. B., Mokhtar, S., Gani, A., & Ullah Khan, S. (2015). The rise of “big data” on cloud computing: Review and open research issues. Information Systems, 47(Supplement C), 98–115. https://doi.org/10.1016/j.is.2014.07.006
Hwangbo, H. (2014, October 22). The future of collaboration: Large-scale visualization. Retrieved November 7, 2017, from http://usblogs.pwc.com/emerging-technology/the-future-of-collaboration-large-scale-visualization/
Laney, D. (2001, February 6). 3D Data Management: Controlling Data Volume, Velocity, and Variety.
Miltenoff, P., & Hauptman, R. (2005). Ethical dilemmas in libraries: an international perspective. The Electronic Library, 23(6), 664–670. https://doi.org/10.1108/02640470510635746
Philip Chen, C. L., & Zhang, C.-Y. (2014). Data-intensive applications, challenges, techniques and technologies: A survey on Big Data. Information Sciences, 275(Supplement C), 314–347. https://doi.org/10.1016/j.ins.2014.01.015
Power, D. J. (2014). Using ‘Big Data’ for analytics and decision support. Journal of Decision Systems, 23(2), 222–228. https://doi.org/10.1080/12460125.2014.888848
Provost, F., & Fawcett, T. (2013). Data Science and its Relationship to Big Data and Data-Driven Decision Making. Big Data, 1(1), 51–59. https://doi.org/10.1089/big.2013.1508
Reilly, S. (2013, December 12). What does Horizon 2020 mean for research libraries? Retrieved November 7, 2017, from http://libereurope.eu/blog/2013/12/12/what-does-horizon-2020-mean-for-research-libraries/
Reyes, J. (2015). The skinny on big data in education: Learning analytics simplified. TechTrends: Linking Research & Practice to Improve Learning, 59(2), 75–80. https://doi.org/10.1007/s11528-015-0842-1
Schroeder, R. (2014). Big Data and the brave new world of social media research. Big Data & Society, 1(2), 2053951714563194. https://doi.org/10.1177/2053951714563194
Sugimoto, C. R., Ding, Y., & Thelwall, M. (2012). Library and information science in the big data era: Funding, projects, and future [a panel proposal]. Proceedings of the American Society for Information Science and Technology, 49(1), 1–3. https://doi.org/10.1002/meet.14504901187
Tene, O., & Polonetsky, J. (2012). Big Data for All: Privacy and User Control in the Age of Analytics. Northwestern Journal of Technology and Intellectual Property, 11, [xxvii]-274.
van Dijck, J. (2014). Datafication, dataism and dataveillance: Big Data between scientific paradigm and ideology. Surveillance & Society; Newcastle upon Tyne, 12(2), 197–208.
Waller, M. A., & Fawcett, S. E. (2013). Data Science, Predictive Analytics, and Big Data: A Revolution That Will Transform Supply Chain Design and Management. Journal of Business Logistics, 34(2), 77–84. https://doi.org/10.1111/jbl.12010
Weiss, A. (2018). Big-Data-Shocks-An-Introduction-to-Big-Data-for-Librarians-and-Information-Professionals. Rowman & Littlefield Publishers. Retrieved from https://rowman.com/ISBN/9781538103227/Big-Data-Shocks-An-Introduction-to-Big-Data-for-Librarians-and-Information-Professionals
West, D. M. (2012). Big data for education: Data mining, data analytics, and web dashboards. Governance Studies at Brookings, 4, 1–0.
Willis, J. (2013). Ethics, Big Data, and Analytics: A Model for Application. Educause Review Online. Retrieved from https://docs.lib.purdue.edu/idcpubs/1
Wixom, B., Ariyachandra, T., Douglas, D. E., Goul, M., Gupta, B., Iyer, L. S., … Turetken, O. (2014). The current state of business intelligence in academia: The arrival of big data. CAIS, 34, 1.
Wu, X., Zhu, X., Wu, G. Q., & Ding, W. (2014). Data mining with big data. IEEE Transactions on Knowledge and Data Engineering, 26(1), 97–107. https://doi.org/10.1109/TKDE.2013.109
Wu, Z., Wu, J., Khabsa, M., Williams, K., Chen, H. H., Huang, W., … Giles, C. L. (2014). Towards building a scholarly big data platform: Challenges, lessons and opportunities. In IEEE/ACM Joint Conference on Digital Libraries (pp. 117–126). https://doi.org/10.1109/JCDL.2014.6970157
alternatives for proofreading, grammar and spelling checker, vocabulary uses, citation suggestions:
http://alternativeto.net/software/grammarly-grammar-checker/
http://www.tricksroad.com/2016/02/grammarly-alternatives.html
https://www.codeinwp.com/blog/grammarly-vs-jetpack-vs-ginger-vs-hemingway-for-wordpress/
https://www.pinterest.com/pin/301670875030195868/
are you a Pinterest user? Here is the link to the board with more materials of this kind:
https://www.pinterest.com/aidedza/doctoral-cohort/

+++++++++++++++++++++
more on dissertation writing in this IMS blog
https://blog.stcloudstate.edu/ims?s=proofreading
http://www.apastyle.org/learn/
if Allport’s work is cited in Nicholson and you did not read Allport’s work, list the Nicholson reference in the reference list. In the text, use the following citation:
http://www.educatorstechnology.com/2017/08/this-is-how-to-cite-online-sources-in.html
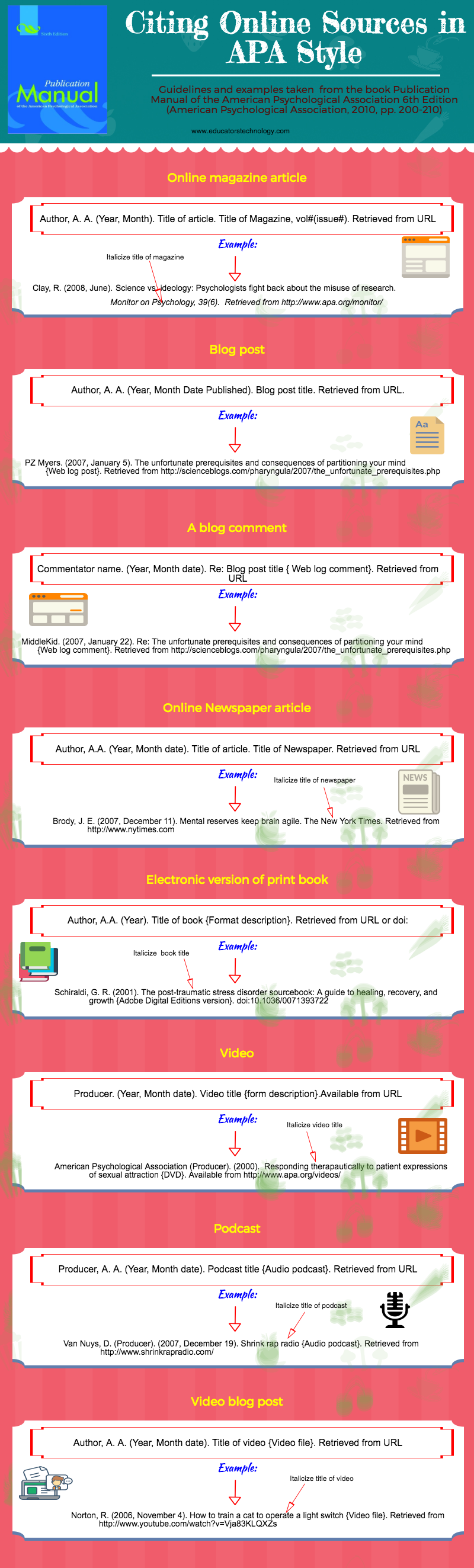
Allport’s diary (as cited in Nicholson, 2003).
+++++++++++++++
more on proofreading in this IMS blog
https://blog.stcloudstate.edu/ims?s=proofreading
Found on Pinterest: http://pin.it/

++++++++++++++++++++
more on proofreading in this IMS blog
https://blog.stcloudstate.edu/ims?s=proofreading
Consider more on this PInterest board:
https://www.pinterest.
+++++++++++++++++++++
by Justin McLachlan http://www.justinmclachlan.com/1670/25-things-writing/
also in: http://pin.it/HwXSc4n
++++++++++++++++++++
more on proofreading in this IMS blog
https://blog.stcloudstate.edu/ims?s=proofreading
more proofreading techniques for the EDAD doctoral cohort on Pinterest
https://www.pinterest.com/aidedza/doctoral-cohort/
https://www.pinterest.com/pin/389139224038620034

++++++++++++++++++++
more on proofreading in this IMS blog
https://blog.stcloudstate.edu/ims?s=proofreading
more proofreading techniques for the EDAD doctoral cohort on Pinterest
https://www.pinterest.com/aidedza/doctoral-cohort/

++++++++++++++
more on proofreading in this IMS blog
https://blog.stcloudstate.edu/ims?s=proofreading
more proofreading techniques for the EDAD doctoral cohort on Pinterest
https://www.pinterest.com/aidedza/doctoral-cohort/