Bibliographical data analysis with Zotero and nVivo
Bibliographic Analysis for Graduate Students, EDAD 518, Fri/Sat, May 15/16, 2020
This session will not be about qualitative research (QR) only, but rather about a modern 21st century approach toward the analysis of your literature review in Chapter 2.
However, the computational approach toward qualitative research is not much different than computational approach for your quantitative research; you need to be versed in each of them, thus familiarity with nVivo for qualitative research and with SPSS for quantitative research should be pursued by any doctoral student.
Qualitative Research
Here a short presentation on the basics:
https://blog.stcloudstate.edu/ims/2019/03/25/qualitative-analysis-basics/
Further, if you wish to expand your knowledge, on qualitative research (QR) in this IMS blog:
https://blog.stcloudstate.edu/ims?s=qualitative+research
Workshop on computational practices for QR:
https://blog.stcloudstate.edu/ims/2017/04/01/qualitative-method-research/
Here is a library instruction session for your course
https://blog.stcloudstate.edu/ims/2020/01/24/digital-literacy-edad-828/
Once you complete the overview of the resources above, please make sure you have Zotero working on your computer; we will be reviewing the Zotero features before we move to nVivo.
Here materials on Zotero collected in the IMS blog:
https://blog.stcloudstate.edu/ims?s=zotero
Of those materials, you might want to cover at least:
https://youtu.be/ktLPpGeP9ic
Familiarity with Zotero is a prerequisite for successful work with nVivo, so please if you are already working with Zotero, try to expand your knowledge using the materials above.
nVivo
https://blog.stcloudstate.edu/ims/2017/01/11/nvivo-shareware/
Please use this link to install nVivo on your computer. Even if we were not in a quarantine and you would have been able to use the licensed nVivo software on campus, for convenience (working on your dissertation from home), most probably, you would have used the shareware. Shareware is fully functional on your computer for 14 days, so calculate the time you will be using it and mind the date of installation and your consequent work.
For the purpose of this workshop, please install nVivo on your computer early morning on Saturday, May 16, so we can work together on nVivo during the day and you can continue using the software for the next two weeks.
Please familiarize yourself with the two articles assigned in the EDAD 815 D2L course content “Practice Research Articles“ :
Brosky, D. (2011). Micropolitics in the School: Teacher Leaders’ Use of Political Skill and Influence Tactics. International Journal of Educational Leadership Preparation, 6(1). https://eric.ed.gov/?id=EJ972880
Tooms, A. K., Kretovics, M. A., & Smialek, C. A. (2007). Principals’ perceptions of politics. International Journal of Leadership in Education, 10(1), 89–100. https://doi.org/10.1080/13603120600950901
It is very important to be familiar with the articles when we start working with nVivo.
++++++++++++++++
How to use Zotero
https://blog.stcloudstate.edu/ims/2020/01/27/zotero-workshop/
++++++++++++++++
How to use nVivo for bibliographic analysis
The following guideline is based on this document:
https://www.projectguru.in/bibliographical-data-nvivo/
whereas the snapshots are replaced with snapshots from nVivol, version 12, which we will be using in our course and for our dissertations.
Concept of bibliographic data
Bibliographic Data is an organized collection of references to publish in literature that includes journals, magazine articles, newspaper articles, conference proceedings, reports, government and legal publications. The bibliographical data is important for writing the literature review of a research. This data is usually saved and organized in databases like Mendeley or Endnote. Nvivo provides the option to import bibliographical data from these databases directly. One can import End Note library or Mendeley library into Nvivo. Similar to interview transcripts, one can represent and analyze bibliographical data using Nvivo. To start with bibliographical data representation, this article previews the processing of literature review in Nvivo.
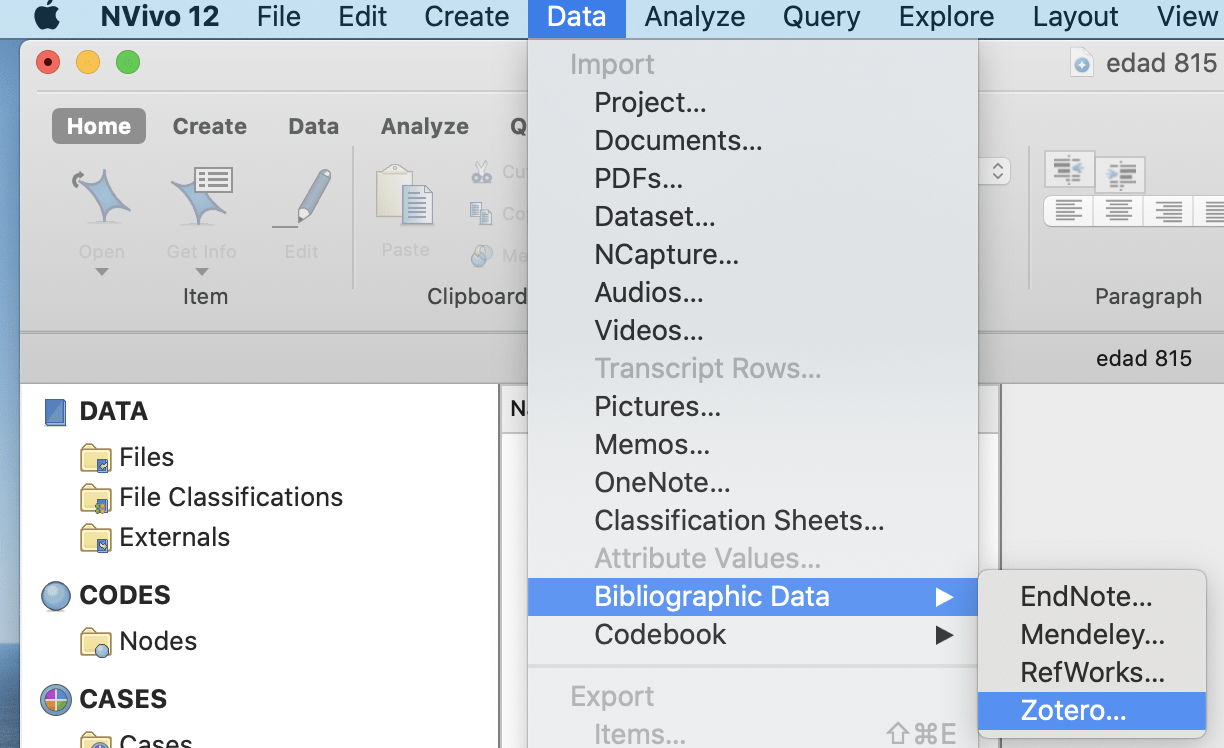
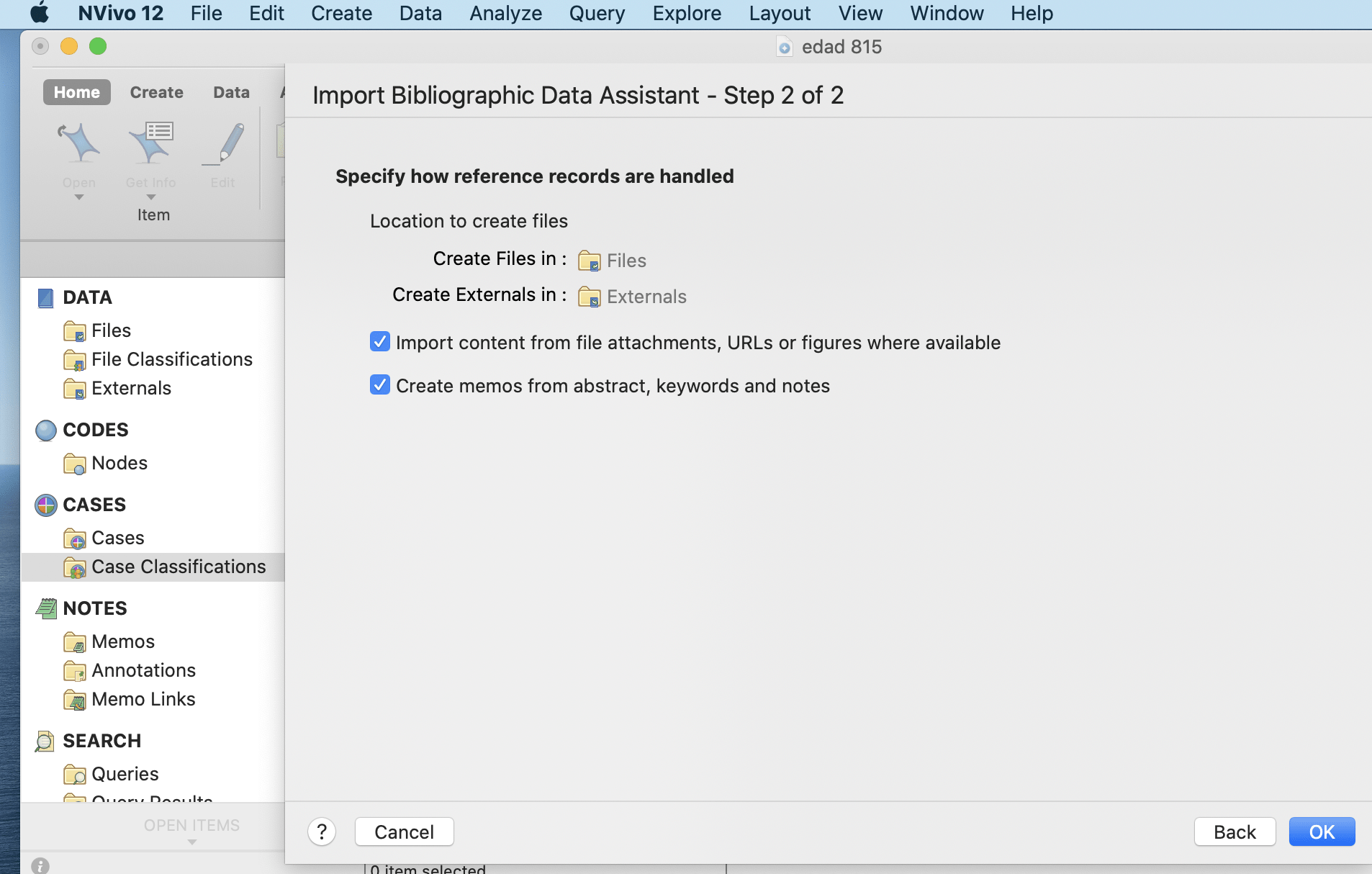
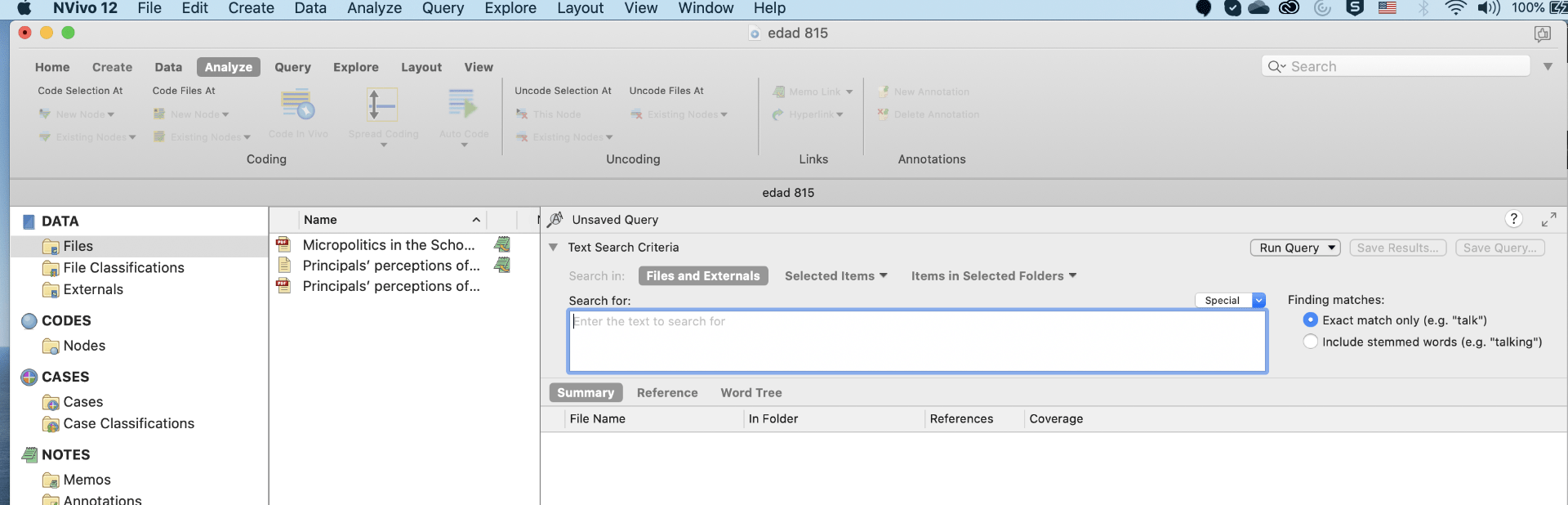
Importing bibliographical data
Bibliographic Data is imported using Mendeley, Endnote and other such databases or applications that are supported with Nvivo. Bibliographical data here refers to material in the form of articles, journals or conference proceedings. Common factors among all of these data are the author’s name and year of publication. Therefore, Nvivo helps to import and arrange these data with their titles as author’s name and year of publication. The process of importing bibliographical data is presented in the figures below.


select the appropriate data from external folder


Coding strategies for literature review
Coding is a process of identifying important parts or patterns in the sources and organizing them in theme node. Sources in case of literature review include material in the form of PDF. That means literature review in Nvivo requires grouping of information from PDF files in the forms of theme nodes. Nodes directly do not create content for literature review, they present ideas simply to help in framing a literature review. Nodes can be created on the basis of theme of the study, results of the study, major findings of the study or any other important information of the study. After creating nodes, code the information of each of the articles into its respective codes.
Nvivo allows coding the articles for preparing a literature review. Articles have tremendous amount of text and information in the forms of graphs, more importantly, articles are in the format of PDF. Since Nvivo does not allow editing PDF files, apply manual coding in case of literature review. There are two strategies of coding articles in Nvivo.
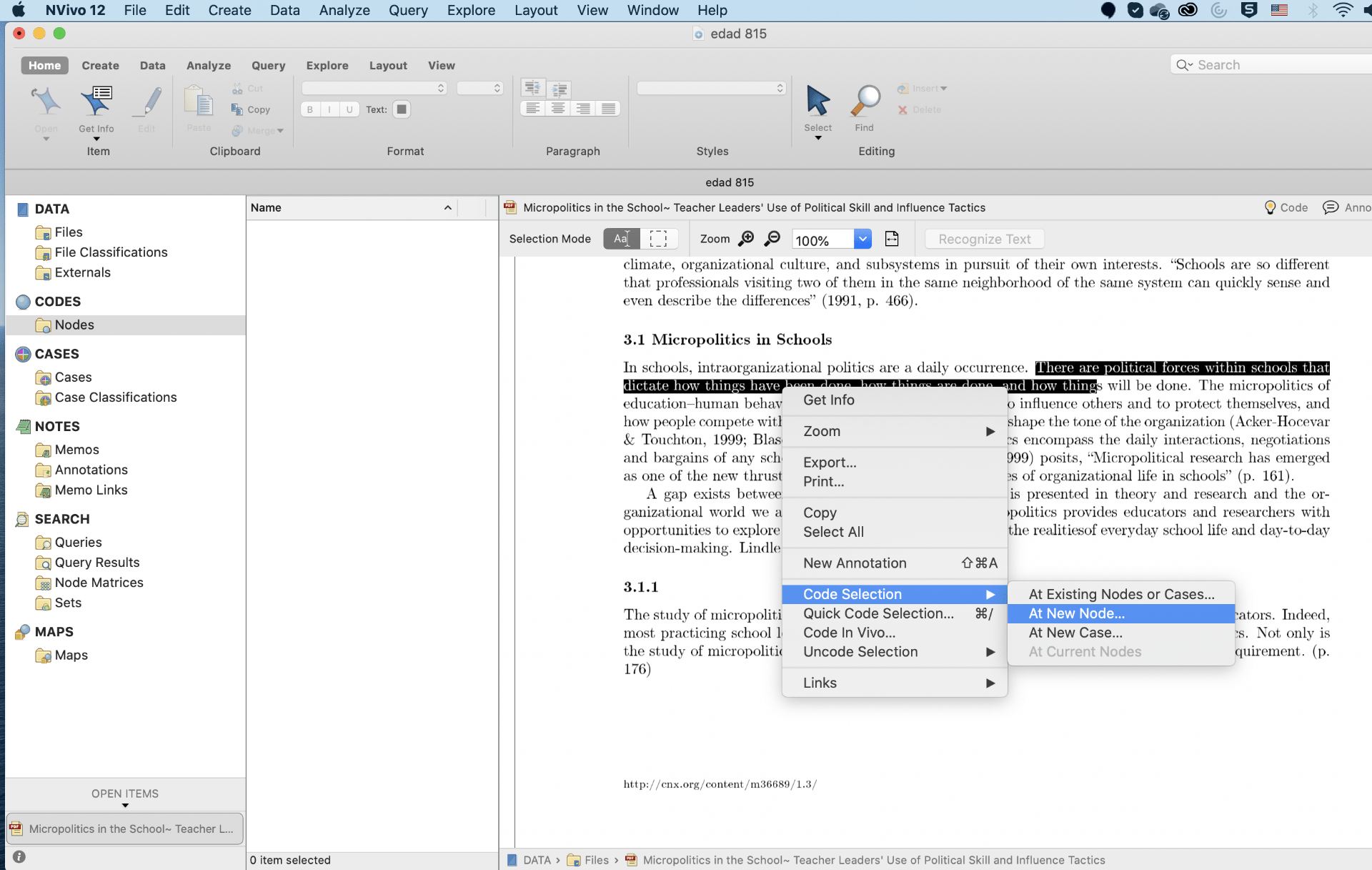
- Code the text of PDF files into a new Node.
- Code the text of PDF file into an existing Node. The procedure of manual coding in literature review is similar to interview transcripts.

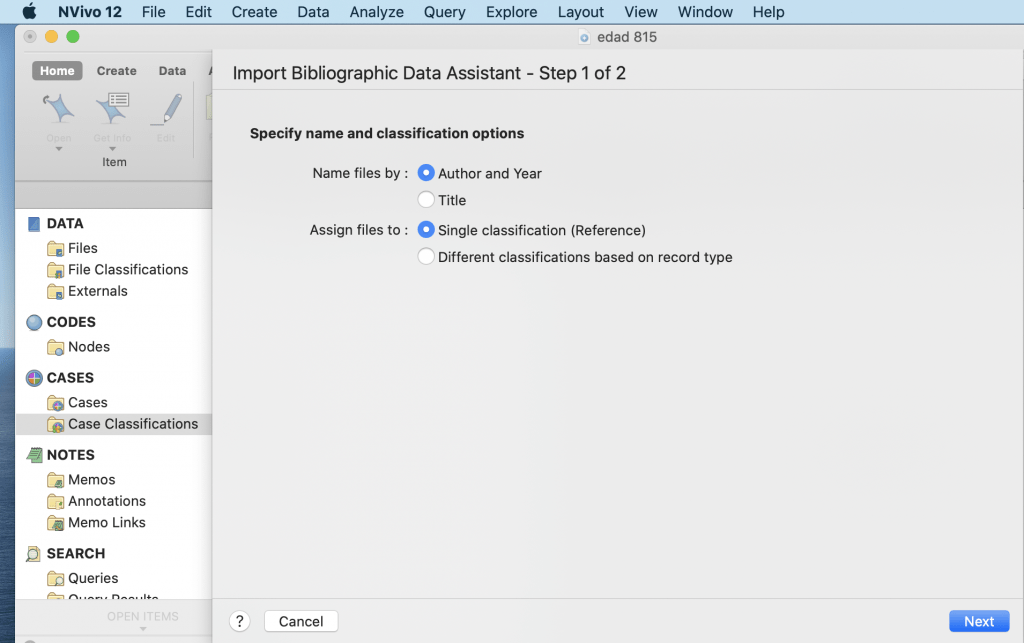
The Case Nodes of articles are created as per the author name or year of the publication.
For example: Create a case node with the name of that author and attach all articles in case of multiple articles of same Author in a row with different information. For instance in figure below, five articles of same author’s name, i.e., Mr. Toppings have been selected together to group in a case Node. Prepare case nodes like this then effortlessly search information based on different author’s opinion for writing empirical review in the literature.
Nvivo questions for literature review
Apart from the coding on themes, evidences, authors or opinions in different articles, run different queries based on the aim of the study. Nvivo contains different types of search tools that helps to find information in and across different articles. With the purpose of literature review, this article presents a brief overview of word frequency search, text search, and coding query in Nvivo.
Word frequency
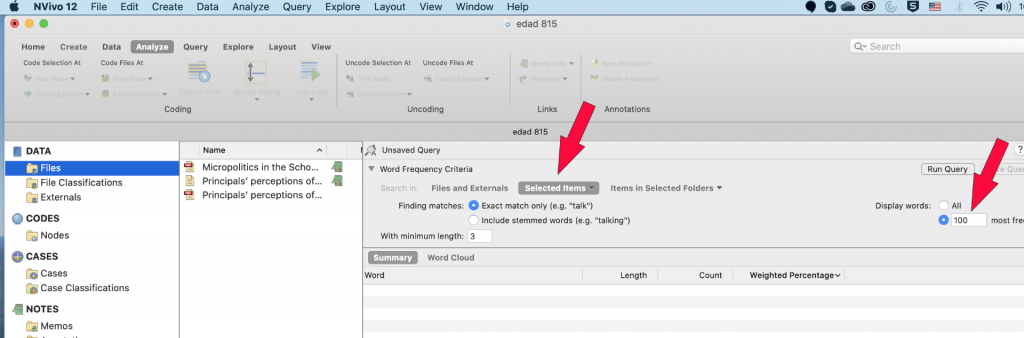
Word frequency in Nvivo allows searching for different words in the articles. In case of literature review, use word frequency to search for a word. This will help to find what different author has stated about the word in the article. Run word frequency on all types of sources and limit the number of words which are not useful to write the literature.
For example, run the command of word frequency with the limit of 100 most frequent words . This will help in assessing if any of these words remotely provide any new information for the literature (figure below).
and
and

Text search
Text search is more elaborative tool then word frequency search in Nvivo. It allows Nvivo to search for a particular phrase or expression in the articles. Also, Nvivo gives the opportunity to make a node out of text search if a particular word, phrase or expression is found useful for literature.
For example: conduct a text search query to find a word “Scaffolding” in the articles. In this case Nvivo will provide all the words, phrases and expression slightly related to this word across all the articles (Figure 8 & 9). The difference between test search and word frequency lies in generating texts, sentences and phrases in the latter related to the queried word.

Coding query
Apart from text search and word frequency search Nvivo also provides the option of coding query. Coding query helps in literature review to know the intersection between two Nodes. As mentioned previously, nodes contains the information from the articles. Furthermore it is also possible that two nodes contain similar set of information. Therefore, coding query helps to condense this information in the form of two way table which represents the intersection between selected nodes.
For example, in below figure, researcher have search the intersection between three nodes namely, academics, psychological and social on the basis of three attributes namely qantitative, qualitative and mixed research. This coding theory is performed to know which of the selected themes nodes have all types of attributes. Like, Coding Matrix in figure below shows that academic have all three types of attributes that is research (quantitative, qualitative and mixed). Where psychological has only two types of attributes research (quantitative and mixed).
In this way, Coding query helps researchers to generate intersection between two or more theme nodes. This also simplifies the pattern of qualitative data to write literature.
+++++++++++++++++++
Please do not hesitate to contact me with questions, suggestions before, during or after our workshop and about ANY questions and suggestions you may have about your Chapter 2 and, particularly about your literature review:
Plamen Miltenoff, Ph.D., MLIS
Professor | 320-308-3072 | pmiltenoff@stcloudstate.edu | http://web.stcloudstate.edu/pmiltenoff/faculty/ | schedule a meeting: https://doodle.com/digitalliteracy | Zoom, Google Hangouts, Skype, FaceTalk, Whatsapp, WeChat, Facebook Messenger are only some of the platforms I can desktopshare with you; if you have your preferable platform, I can meet you also at your preference.
++++++++++++++
more on nVIvo in this IMS blog
https://blog.stcloudstate.edu/ims?s=nvivo
more on Zotero in this IMS blog
https://blog.stcloudstate.edu/ims?s=zotero