We can build robot teachers, or even robot teaching assistants. But should we?
the Chinese government has declared a national goal of surpassing the U.S. in AI technology by the year 2030, so there is almost a Sputnik-like push for the tech going on right now in China. At the same time, China is also facing a shortage of qualified teachers in many rural areas, and there’s a huge demand for high-quality language teachers and tutors throughout the country.
Both jazz and classical art forms require not only music literacy, but for the musician to be at the top of their game in technical proficiency, tonal quality and creativity in the case of the jazz idiom. Jazz masters like John Coltrane would practice six to nine hours a day, often cutting his practice only because his inner lower lip would be bleeding from the friction caused by his mouth piece against his gums and teeth. His ability to compose and create new styles and directions for jazz was legendary. With few exceptions such as Wes Montgomery or Chet Baker, if you couldn’t read music, you couldn’t play jazz.
Besides the decline of music literacy and participation, there has also been a decline in the quality of music which has been proven scientifically by Joan Serra, a postdoctoral scholar at the Artificial Intelligence Research Institute of the Spanish National Research Council in Barcelona. Joan and his colleagues looked at 500,000 pieces of music between 1955-2010, running songs through a complex set of algorithms examining three aspects of those songs:
1. Timbre- sound color, texture and tone quality
2. Pitch- harmonic content of the piece, including its chords, melody, and tonal arrangements
3. Loudness- volume variance adding richness and depth
In an interview, Billy Joel was asked what has made him a standout. He responded his ability to read and compose music made him unique in the music industry, which as he explained, was troubling for the industry when being musically literate makes you stand out. An astonishing amount of today’s popular music is written by two people: Lukasz Gottwald of the United States and Max Martin from Sweden, who are both responsible for dozens of songs in the top 100 charts. You can credit Max and Dr. Luke for most the hits of these stars:
Katy Perry, Britney Spears, Kelly Clarkson, Taylor Swift, Jessie J., KE$HA, Miley Cyrus, Avril Lavigne, Maroon 5, Taio Cruz, Ellie Goulding, NSYNC, Backstreet Boys, Ariana Grande, Justin Timberlake, Nick Minaj, Celine Dion, Bon Jovi, Usher, Adam Lambert, Justin Bieber, Domino, Pink, Pitbull, One Direction, Flo Rida, Paris Hilton, The Veronicas, R. Kelly, Zebrahead
Artificial intelligence could erase many practical advantages of democracy, and erode the ideals of liberty and equality. It will further concentrate power among a small elite if we don’t take steps to stop it.
Ordinary people may not understand artificial intelligence and biotechnology in any detail, but they can sense that the future is passing them by. In 1938 the common man’s condition in the Soviet Union, Germany, or the United States may have been grim, but he was constantly told that he was the most important thing in the world, and that he was the future (provided, of course, that he was an “ordinary man,” rather than, say, a Jew or a woman).
n 2018 the common person feels increasingly irrelevant. Lots of mysterious terms are bandied about excitedly in ted Talks, at government think tanks, and at high-tech conferences—globalization, blockchain, genetic engineering, AI, machine learning—and common people, both men and women, may well suspect that none of these terms is about them.
Fears of machines pushing people out of the job market are, of course, nothing new, and in the past such fears proved to be unfounded. But artificial intelligence is different from the old machines. In the past, machines competed with humans mainly in manual skills. Now they are beginning to compete with us in cognitive skills.
Israel is a leader in the field of surveillance technology, and has created in the occupied West Bank a working prototype for a total-surveillance regime. Already today whenever Palestinians make a phone call, post something on Facebook, or travel from one city to another, they are likely to be monitored by Israeli microphones, cameras, drones, or spy software. Algorithms analyze the gathered data, helping the Israeli security forces pinpoint and neutralize what they consider to be potential threats.
The conflict between democracy and dictatorship is actually a conflict between two different data-processing systems. AI may swing the advantage toward the latter.
As we rely more on Google for answers, our ability to locate information independently diminishes. Already today, “truth” is defined by the top results of a Google search. This process has likewise affected our physical abilities, such as navigating space.
So what should we do?
For starters, we need to place a much higher priority on understanding how the human mind works—particularly how our own wisdom and compassion can be cultivated.
Sejnowski, T. J. (2018). The Deep Learning Revolution. Cambridge, MA: The MIT Press.
How deep learning―from Google Translate to driverless cars to personal cognitive assistants―is changing our lives and transforming every sector of the economy.
The deep learning revolution has brought us driverless cars, the greatly improved Google Translate, fluent conversations with Siri and Alexa, and enormous profits from automated trading on the New York Stock Exchange. Deep learning networks can play poker better than professional poker players and defeat a world champion at Go. In this book, Terry Sejnowski explains how deep learning went from being an arcane academic field to a disruptive technology in the information economy.
Sejnowski played an important role in the founding of deep learning, as one of a small group of researchers in the 1980s who challenged the prevailing logic-and-symbol based version of AI. The new version of AI Sejnowski and others developed, which became deep learning, is fueled instead by data. Deep networks learn from data in the same way that babies experience the world, starting with fresh eyes and gradually acquiring the skills needed to navigate novel environments. Learning algorithms extract information from raw data; information can be used to create knowledge; knowledge underlies understanding; understanding leads to wisdom. Someday a driverless car will know the road better than you do and drive with more skill; a deep learning network will diagnose your illness; a personal cognitive assistant will augment your puny human brain. It took nature many millions of years to evolve human intelligence; AI is on a trajectory measured in decades. Sejnowski prepares us for a deep learning future.
Buzzwords like “deep learning” and “neural networks” are everywhere, but so much of the popular understanding is misguided, says Terrence Sejnowski, a computational neuroscientist at the Salk Institute for Biological Studies.
Sejnowski, a pioneer in the study of learning algorithms, is the author of The Deep Learning Revolution(out next week from MIT Press). He argues that the hype about killer AI or robots making us obsolete ignores exciting possibilities happening in the fields of computer science and neuroscience, and what can happen when artificial intelligence meets human intelligence.
Machine learning is a very large field and goes way back. Originally, people were calling it “pattern recognition,” but the algorithms became much broader and much more sophisticated mathematically. Within machine learning are neural networks inspired by the brain, and then deep learning. Deep learning algorithms have a particular architecture with many layers that flow through the network. So basically, deep learning is one part of machine learning and machine learning is one part of AI.
December 2012 at the NIPS meeting, which is the biggest AI conference. There, [computer scientist] Geoff Hinton and two of his graduate students showed you could take a very large dataset called ImageNet, with 10,000 categories and 10 million images, and reduce the classification error by 20 percent using deep learning.Traditionally on that dataset, error decreases by less than 1 percent in one year. In one year, 20 years of research was bypassed. That really opened the floodgates.
The inspiration for deep learning really comes from neuroscience.
AlphaGo, the program that beat the Go champion included not just a model of the cortex, but also a model of a part of the brain called the basal ganglia, which is important for making a sequence of decisions to meet a goal. There’s an algorithm there called temporal differences, developed back in the ‘80s by Richard Sutton, that, when coupled with deep learning, is capable of very sophisticated plays that no human has ever seen before.
there’s a convergence occurring between AI and human intelligence. As we learn more and more about how the brain works, that’s going to reflect back in AI. But at the same time, they’re actually creating a whole theory of learning that can be applied to understanding the brain and allowing us to analyze the thousands of neurons and how their activities are coming out. So there’s this feedback loop between neuroscience and AI
United States digital literacy frameworks tend to focus on educational policy details and personal empowerment, the latter encouraging learners to become more effective students, better creators, smarter information consumers, and more influential members of their community.
National policies are vitally important in European digital literacy work, unsurprising for a continent well populated with nation-states and struggling to redefine itself, while still trying to grow economies in the wake of the 2008 financial crisis and subsequent financial pressures
African digital literacy is more business-oriented.
Middle Eastern nations offer yet another variation, with a strong focus on media literacy. As with other regions, this can be a response to countries with strong state influence or control over local media. It can also represent a drive to produce more locally-sourced content, as opposed to consuming material from abroad, which may elicit criticism of neocolonialism or religious challenges.
p. 14 Digital literacy for Humanities: What does it mean to be digitally literate in history, literature, or philosophy? Creativity in these disciplines often involves textuality, given the large role writing plays in them, as, for example, in the Folger Shakespeare Library’s instructor’s guide. In the digital realm, this can include web-based writing through social media, along with the creation of multimedia projects through posters, presentations, and video. Information literacy remains a key part of digital literacy in the humanities. The digital humanities movement has not seen much connection with digital literacy, unfortunately, but their alignment seems likely, given the turn toward using digital technologies to explore humanities questions. That development could then foster a spread of other technologies and approaches to the rest of the humanities, including mapping, data visualization, text mining, web-based digital archives, and “distant reading” (working with very large bodies of texts). The digital humanities’ emphasis on making projects may also increase
Digital Literacy for Business: Digital literacy in this world is focused on manipulation of data, from spreadsheets to more advanced modeling software, leading up to degrees in management information systems. Management classes unsurprisingly focus on how to organize people working on and with digital tools.
Digital Literacy for Computer Science: Naturally, coding appears as a central competency within this discipline. Other aspects of the digital world feature prominently, including hardware and network architecture. Some courses housed within the computer science discipline offer a deeper examination of the impact of computing on society and politics, along with how to use digital tools. Media production plays a minor role here, beyond publications (posters, videos), as many institutions assign multimedia to other departments. Looking forward to a future when automation has become both more widespread and powerful, developing artificial intelligence projects will potentially play a role in computer science literacy.
In traditional instruction, students’ first contact with new ideas happens in class, usually through direct instruction from the professor; after exposure to the basics, students are turned out of the classroom to tackle the most difficult tasks in learning — those that involve application, analysis, synthesis, and creativity — in their individual spaces. Flipped learning reverses this, by moving first contact with new concepts to the individual space and using the newly-expanded time in class for students to pursue difficult, higher-level tasks together, with the instructor as a guide.
Let’s take a look at some of the myths about flipped learning and try to find the facts.
Myth: Flipped learning is predicated on recording videos for students to watch before class.
Fact: Flipped learning does not require video. Although many real-life implementations of flipped learning use video, there’s nothing that says video must be used. In fact, one of the earliest instances of flipped learning — Eric Mazur’s peer instruction concept, used in Harvard physics classes — uses no video but rather an online text outfitted with social annotation software. And one of the most successful public instances of flipped learning, an edX course on numerical methods designed by Lorena Barba of George Washington University, uses precisely one video. Video is simply not necessary for flipped learning, and many alternatives to video can lead to effective flipped learning environments [http://rtalbert.org/flipped-learning-without-video/].
Fact: Flipped learning optimizes face-to-face teaching. Flipped learning may (but does not always) replace lectures in class, but this is not to say that it replaces teaching. Teaching and “telling” are not the same thing.
Myth: Flipped learning has no evidence to back up its effectiveness.
Fact: Flipped learning research is growing at an exponential pace and has been since at least 2014. That research — 131 peer-reviewed articles in the first half of 2017 alone — includes results from primary, secondary, and postsecondary education in nearly every discipline, most showing significant improvements in student learning, motivation, and critical thinking skills.
Myth: Flipped learning is a fad.
Fact: Flipped learning has been with us in the form defined here for nearly 20 years.
Myth: People have been doing flipped learning for centuries.
Fact: Flipped learning is not just a rebranding of old techniques. The basic concept of students doing individually active work to encounter new ideas that are then built upon in class is almost as old as the university itself. So flipped learning is, in a real sense, a modern means of returning higher education to its roots. Even so, flipped learning is different from these time-honored techniques.
Myth: Students and professors prefer lecture over flipped learning.
Fact: Students and professors embrace flipped learning once they understand the benefits. It’s true that professors often enjoy their lectures, and students often enjoy being lectured to. But the question is not who “enjoys” what, but rather what helps students learn the best.They know what the research says about the effectiveness of active learning
Assertion: Flipped learning provides a platform for implementing active learning in a way that works powerfully for students.
The Exposure Approach: we don’t provide a way for participants to determine if they learned anything new or now have the confidence or competence to apply what they learned.
The Exemplar Approach: from ‘show and tell’ for adults to show, tell, do and learn.
The Tutorial Approach: Getting a group that can meet at the same time and place can be challenging. That is why many faculty report a preference for self-paced professional development.build in simple self-assessment checks. We can add prompts that invite people to engage in some sort of follow up activity with a colleague. We can also add an elective option for faculty in a tutorial to actually create or do something with what they learned and then submit it for direct or narrative feedback.
The Course Approach: a non-credit format, these have the benefits of a more structured and lengthy learning experience, even if they are just three to five-week short courses that meet online or in-person once every week or two.involve badges, portfolios, peer assessment, self-assessment, or one-on-one feedback from a facilitator
The Academy Approach: like the course approach, is one that tends to be a deeper and more extended experience. People might gather in a cohort over a year or longer.Assessment through coaching and mentoring, the use of portfolios, peer feedback and much more can be easily incorporated to add a rich assessment element to such longer-term professional development programs.
The Mentoring Approach: The mentors often don’t set specific learning goals with the mentee. Instead, it is often a set of structured meetings, but also someone to whom mentees can turn with questions and tips along the way.
The Coaching Approach: A mentor tends to be a broader type of relationship with a person.A coaching relationship tends to be more focused upon specific goals, tasks or outcomes.
The Peer Approach:This can be done on a 1:1 basis or in small groups, where those who are teaching the same courses are able to compare notes on curricula and teaching models. They might give each other feedback on how to teach certain concepts, how to write syllabi, how to handle certain teaching and learning challenges, and much more. Faculty might sit in on each other’s courses, observe, and give feedback afterward.
The Self-Directed Approach:a self-assessment strategy such as setting goals and creating simple checklists and rubrics to monitor our progress. Or, we invite feedback from colleagues, often in a narrative and/or informal format. We might also create a portfolio of our work, or engage in some sort of learning journal that documents our thoughts, experiments, experiences, and learning along the way.
In 2014, administrators at Central Piedmont Community College (CPCC) in Charlotte, North Carolina, began talks with members of the North Carolina State Board of Community Colleges and North Carolina Community College System (NCCCS) leadership about starting a CBE program.
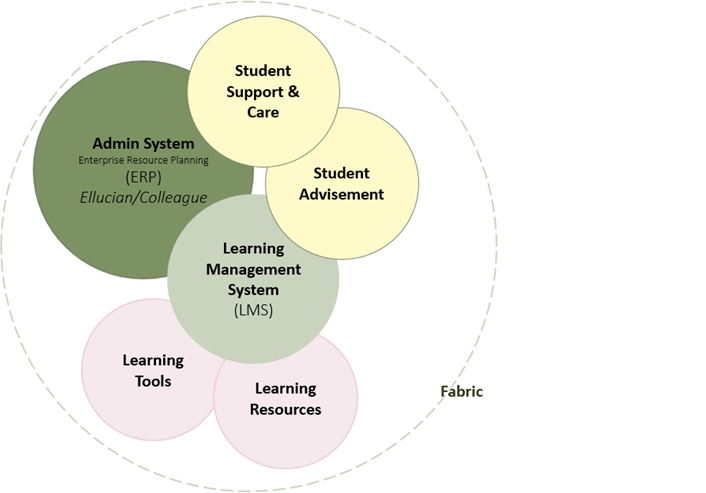
Building on an existing project at CPCC for identifying the elements of a digital learning environment (DLE), which was itself influenced by the EDUCAUSE publication The Next Generation Digital Learning Environment: A Report on Research,1 the committee reached consensus on a DLE concept and a shared lexicon: the “Digital Learning Environment Operational Definitions,
Artificial intelligence (AI) and machine learning are no longer fantastical prospects seen only in science fiction. Products like Amazon Echo and Siri have brought AI into many homes,
Kelly Calhoun Williams, an education analyst for the technology research firm Gartner Inc., cautions there is a clear gap between the promise of AI and the reality of AI.
Artificial intelligence is a broad term used to describe any technology that emulates human intelligence, such as by understanding complex information, drawing its own conclusions and engaging in natural dialog with people.
Machine learning is a subset of AI in which the software can learn or adapt like a human can. Essentially, it analyzes huge amounts of data and looks for patterns in order to classify information or make predictions. The addition of a feedback loop allows the software to “learn” as it goes by modifying its approach based on whether the conclusions it draws are right or wrong.
AI can process far more information than a human can, and it can perform tasks much faster and with more accuracy. Some curriculum software developers have begun harnessing these capabilities to create programs that can adapt to each student’s unique circumstances.
For instance, a Seattle-based nonprofit company calledEnlearn has developed an adaptive learning platform that uses machine learning technology to create highly individualized learning paths that can accelerate learning for every student. (My note: about learning and technology, Alfie Kohn in https://blog.stcloudstate.edu/ims/2018/09/11/educational-technology/)
GoGuardian, a Los Angeles company, uses machine learning technology to improve the accuracy of its cloud-based Internet filtering and monitoring software for Chromebooks. (My note: that smells Big Brother).Instead of blocking students’ access to questionable material based on a website’s address or domain name, GoGuardian’s software uses AI to analyze the actual content of a page in real time to determine whether it’s appropriate for students. (my note: privacy)
serious privacy concerns. It requires an increased focus not only on data quality and accuracy, but also on the responsible stewardship of this information. “School leaders need to get ready for AI from a policy standpoint,” Calhoun Williams said. For instance: What steps will administrators take to secure student data and ensure the privacy of this information?
Künstliche Intelligenzen und Roboter werden in unserem Leben immer selbstverständlicher. Was erwarten wir von den intelligenten Maschinen, wie verändert ihre Präsenz in unserem Alltag und die Interaktion mit ihnen unser Selbstverständnis und unseren Umgang mit anderen Menschen? Müssen wir Roboter als eine Art menschliches Gegenüber anerkennen? Und welche Freiheiten wollen wir den Maschinen einräumen? Es ist dringend an der Zeit, die ethischen und rechtlichen Fragen zu klären.
1954 wurdeUnimate, der erste Industrieroboter , von George Devol entwickelt [1]. Insbesondere in den 1970er Jahren haben viele produzierende Gewerbe eine Roboterisierung ihrer Arbeit erfahren (beispielsweise die Automobil- und Druckindustrie).
Definition eines Industrieroboters in der ISO 8373 (2012) vergegenwärtigt: »Ein Roboter ist ein frei und wieder programmierbarer, multifunktionaler Manipulator mit mindestens drei unabhängigen Achsen, um Materialien, Teile, Werkzeuge oder spezielle Geräte auf programmierten, variablen Bahnen zu bewegen zur Erfüllung der verschiedensten Aufgaben«.
Ethische Überlegungen zu Robotik und Künstlicher Intelligenz
Versucht man sich einen Überblick über die verschiedenen ethischen Probleme zu verschaffen, die mit dem Aufkommen von ›intelligenten‹ und in jeder Hinsicht (Präzision, Geschwindigkeit, Kraft, Kombinatorik und Vernetzung) immer mächtigeren Robotern verbunden sind, so ist es hilfreich, diese Probleme danach zu unterscheiden, ob sie
1. das Vorfeld der Ethik,
2. das bisherige Selbstverständnis menschlicher Subjekte (Anthropologie) oder
3. normative Fragen im Sinne von: »Was sollen wir tun?« betreffen.
Die folgenden Überlegungen geben einen kurzen Aufriss, mit welchen Fragen wir uns jeweils beschäftigen sollten, wie die verschiedenen Fragenkreise zusammenhängen, und woran wir uns in unseren Antworten orientieren können.
Aufgabe der Ethik ist es, solche moralischen Meinungen auf ihre Begründung und Geltung hin zu befragen und so zu einem geschärften ethischen Urteil zu kommen, das idealiter vor der Allgemeinheit moralischer Subjekte verantwortet werden kann und in seiner Umsetzung ein »gelungenes Leben mit und für die Anderen, in gerechten Institutionen« [8] ermöglicht. Das ist eine erste vage Richtungsangabe.
Normative Fragen lassen sich am Ende nur ganz konkret anhand einer bestimmten Situation bearbeiten. Entsprechend liefert die Ethik hier keine pauschalen Urteile wie: »Roboter sind gut/schlecht«, »Künstliche Intelligenz dient dem guten Leben/ist dem guten Leben abträglich«.