People who behaved in accordance with them—for example, by staying away from the overgrown pond bank where someone said there was a viper—were more likely to survive than those who did not.
Compounding the problem is the proliferation of online information. Viewing and producing blogs, videos, tweets and other units of information called memes has become so cheap and easy that the information marketplace is inundated. My note: folksonomy in its worst.
At the University of Warwick in England and at Indiana University Bloomington’s Observatory on Social Media (OSoMe, pronounced “awesome”), our teams are using cognitive experiments, simulations, data mining and artificial intelligence to comprehend the cognitive vulnerabilities of social media users. developing analytical and machine-learning aids to fight social media manipulation.
As Nobel Prize–winning economist and psychologist Herbert A. Simon noted, “What information consumes is rather obvious: it consumes the attention of its recipients.”
attention economy
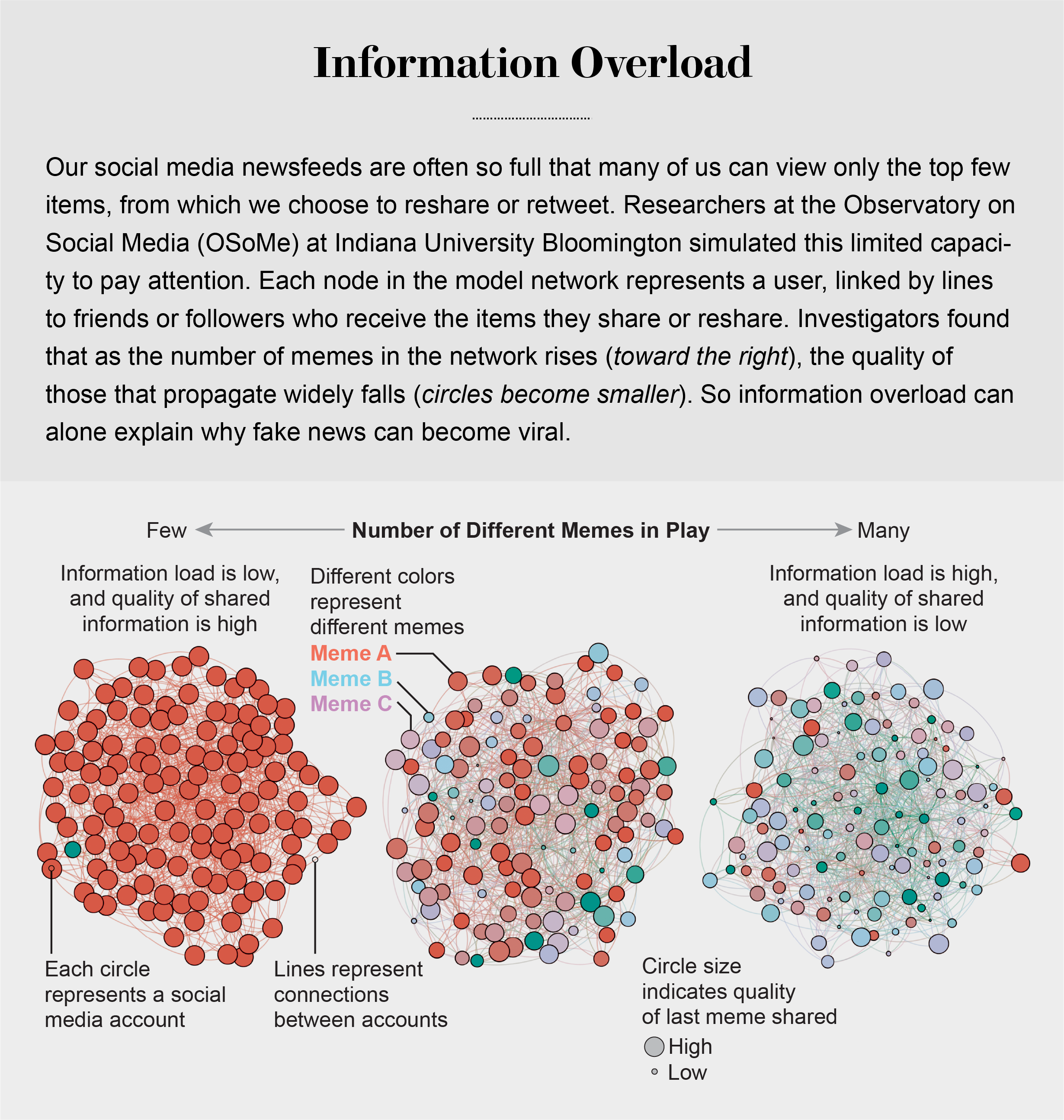
Our models revealed that even when we want to see and share high-quality information, our inability to view everything in our news feeds inevitably leads us to share things that are partly or completely untrue.
Frederic Bartlett
Cognitive biases greatly worsen the problem.
We now know that our minds do this all the time: they adjust our understanding of new information so that it fits in with what we already know. One consequence of this so-called confirmation bias is that people often seek out, recall and understand information that best confirms what they already believe.
This tendency is extremely difficult to correct.
Making matters worse, search engines and social media platforms provide personalized recommendations based on the vast amounts of data they have about users’ past preferences.
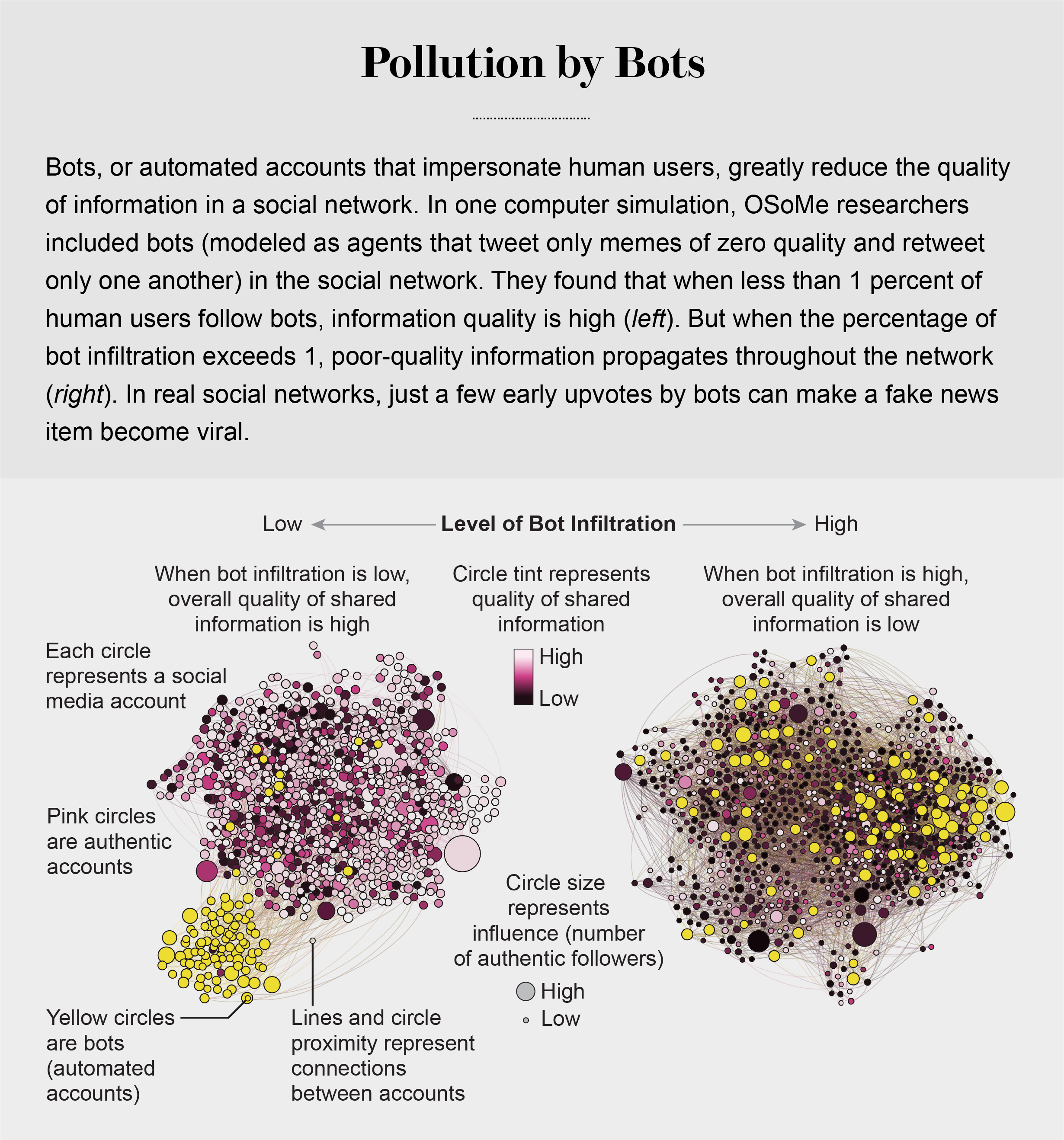
pollution by bots
Social Herding
social groups create a pressure toward conformity so powerful that it can overcome individual preferences, and by amplifying random early differences, it can cause segregated groups to diverge to extremes.
Social media follows a similar dynamic. We confuse popularity with quality and end up copying the behavior we observe.
information is transmitted via “complex contagion”: when we are repeatedly exposed to an idea, typically from many sources, we are more likely to adopt and reshare it.
In addition to showing us items that conform with our views, social media platforms such as Facebook, Twitter, YouTube and Instagram place popular content at the top of our screens and show us how many people have liked and shared something.Few of us realize that these cues do not provide independent assessments of quality.
programmers who design the algorithms for ranking memes on social media assume that the “wisdom of crowds” will quickly identify high-quality items; they use popularity as a proxy for quality. My note: again, ill-conceived folksonomy.
Echo Chambers
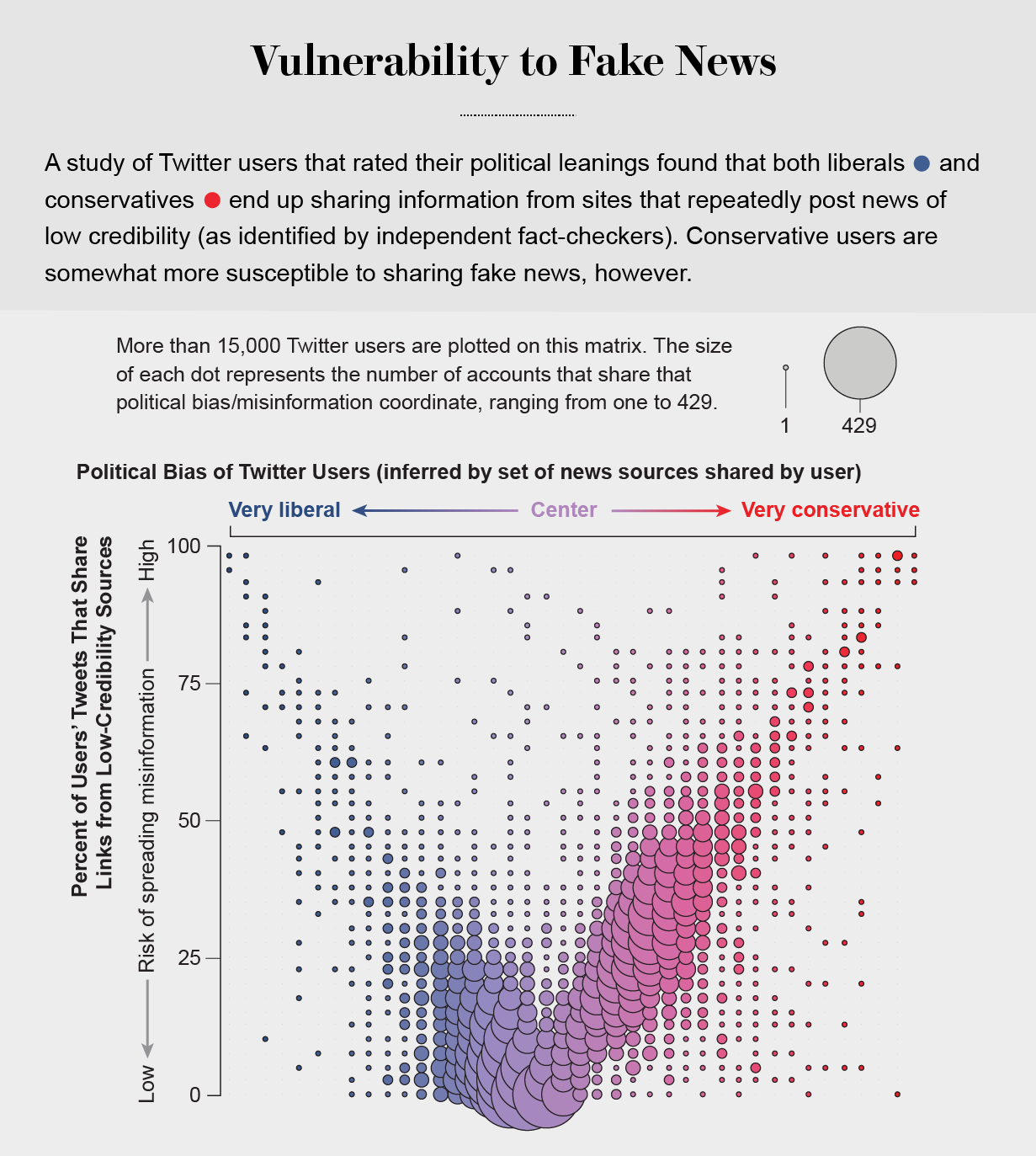
the political echo chambers on Twitter are so extreme that individual users’ political leanings can be predicted with high accuracy: you have the same opinions as the majority of your connections. This chambered structure efficiently spreads information within a community while insulating that community from other groups.
socially shared information not only bolsters our biases but also becomes more resilient to correction.
machine-learning algorithms to detect social bots. One of these, Botometer, is a public tool that extracts 1,200 features from a given Twitter account to characterize its profile, friends, social network structure, temporal activity patterns, language and other features. The program compares these characteristics with those of tens of thousands of previously identified bots to give the Twitter account a score for its likely use of automation.
Some manipulators play both sides of a divide through separate fake news sites and bots, driving political polarization or monetization by ads.
recently uncovered a network of inauthentic accounts on Twitter that were all coordinated by the same entity. Some pretended to be pro-Trump supporters of the Make America Great Again campaign, whereas others posed as Trump “resisters”; all asked for political donations.
a mobile app called Fakey that helps users learn how to spot misinformation. The game simulates a social media news feed, showing actual articles from low- and high-credibility sources. Users must decide what they can or should not share and what to fact-check. Analysis of data from Fakey confirms the prevalence of online social herding: users are more likely to share low-credibility articles when they believe that many other people have shared them.
Hoaxy, shows how any extant meme spreads through Twitter. In this visualization, nodes represent actual Twitter accounts, and links depict how retweets, quotes, mentions and replies propagate the meme from account to account.
Free communication is not free. By decreasing the cost of information, we have decreased its value and invited its adulteration.
large data is inherently noisy. \In general, the more “democratic” the production channel, the dirtier the data – which means that more effort has to be spent on its cleaning. For example, data from social media will require a longer cleaning pipeline. Among others, you will need to deal with extravagancies of self-expression like smileys and irregular punctuation, which are normally absent in more formal settings such as scientific papers or legal contracts.
The other major challenge is the labeled data bottleneck
crowd-sourcing and Training Data as a Service (TDaaS). On the other hand, a range of automatic workarounds for the creation of annotated datasets have also been suggested in the machine learning community.
Algorithms: a chain of disruptions in Deep Learning
Neural Networks are the workhorse of Deep Learning (cf. Goldberg and Hirst (2017) for an introduction of the basic architectures in the NLP context). Convolutional Neural Networks have seen an increase in the past years, whereas the popularity of the traditional Recurrent Neural Network (RNN) is dropping. This is due, on the one hand, to the availability of more efficient RNN-based architectures such as LSTM and GRU. On the other hand, a new and pretty disruptive mechanism for sequential processing – attention – has been introduced in the sequence-to-sequence (seq2seq) model by Sutskever et al. (2014).
Consolidating various NLP tasks
the three “global” NLP development curves – syntax, semantics and context awareness
the third curve – the awareness of a larger context – has already become one of the main drivers behind new Deep Learning algorithms.
A note on multilingual research
Think of different languages as different lenses through which we view the same world – they share many properties, a fact that is fully accommodated by modern learning algorithms with their increasing power for abstraction and generalization.
Spurred by the global AI hype, the NLP field is exploding with new approaches and disruptive improvements. There is a shift towards modeling meaning and context dependence, probably the most universal and challenging fact of human language. The generalisation power of modern algorithms allows for efficient scaling across different tasks, languages and datasets, thus significantly speeding up the ROI cycle of NLP developments and allowing for a flexible and efficient integration of NLP into individual business scenarios.
Researchers at the Fraunhofer Institute for Microelectronic Circuits and Systems IMS have developed AIfES, an artificial intelligence (AI) concept for microcontrollers and sensors that contains a completely configurable artificial neural network. AIfES is a platform-independent machine learning library which can be used to realize self-learning microelectronics requiring no connection to a cloud or to high-performance computers. The sensor-related AI system recognizes handwriting and gestures, enabling for example gesture control of input when the library is running on a wearable.
a machine learning library programmed in C that can run on microcontrollers, but also on other platforms such as PCs, Raspberry PI and Android.
Many educational institutions maintain their own data centers. “We need to minimize the amount of work we do to keep systems up and running, and spend more energy innovating on things that matter to people.”
what’s the difference between machine learning (ML) and artificial intelligence (AI)?
Jeff Olson: That’s actually the setup for a joke going around the data science community. The punchline? If it’s written in Python or R, it’s machine learning. If it’s written in PowerPoint, it’s AI.
machine learning is in practical use in a lot of places, whereas AI conjures up all these fantastic thoughts in people.
What is serverless architecture, and why are you excited about it?
Instead of having a machine running all the time, you just run the code necessary to do what you want—there is no persisting server or container. There is only this fleeting moment when the code is being executed. It’s called Function as a Service, and AWS pioneered it with a service called AWS Lambda. It allows an organization to scale up without planning ahead.
How do you think machine learning and Function as a Service will impact higher education in general?
The radical nature of this innovation will make a lot of systems that were built five or 10 years ago obsolete. Once an organization comes to grips with Function as a Service (FaaS) as a concept, it’s a pretty simple step for that institution to stop doing its own plumbing. FaaS will help accelerate innovation in education because of the API economy.
If the campus IT department will no longer be taking care of the plumbing, what will its role be?
I think IT will be curating the inter-operation of services, some developed locally but most purchased from the API economy.
As a result, you write far less code and have fewer security risks, so you can innovate faster. A succinct machine-learning algorithm with fewer than 500 lines of code can now replace an application that might have required millions of lines of code. Second, it scales. If you happen to have a gigantic spike in traffic, it deals with it effortlessly. If you have very little traffic, you incur a negligible cost.
350 researchers, 200 graduate students, and 150 professionals in the AI sector. “We need AI, we need machine learning, we need the development of new technology to get people more efficient
Eureka: machine learning tool, brainstorming engine. give it an initial idea and it returns similar ideas. Like Google: refine the idea, so the machine can understand it better. create a collection of ideas to translate into course design or others.
Netlix:
influencers and microinfluencers, pre- and doing the execution
a machine can construct a book with the help of a person. bionic book. machine and person working hand in hand. provide keywords and phrases from lecture notes, presentation materials. from there recommendations and suggestions based on own experience; then identify included and excluded content. then instructor can construct.
Design may be the least interesting part of the book for the faculty.
multiple choice quiz may be the least interesting part, and faculty might want to do much deeper assessment.
use these machine learning techniques to build assessment. how to more effectively. inquizitive is the machine learning
students engagements and similar prompts
presence in the classroom: pre-service teachers class. how to immerse them and practice classroom management skills
First class: marriage btw VR and use of AI – an environment headset: an algorithm reacts how teachers are interacting with the virtual kids. series of variables, oppty to interact with present behavior. classroom management skills. simulations and environments otherwise impossible to create. apps for these type of interactions
facilitation, reflection and research
AI for more human experience, allow more time for the faculty to be more human, more free time to contemplate.
Jason: Won’t the use of AI still reduce the amount of faculty needed?
Christina Dumeng: @Jason–I think it will most likely increase the amount of students per instructor.
Andrew Cole (UW-Whitewater): I wonder if instead of reducing faculty, these types of platforms (e.g., analytic capabilities) might require instructors to also become experts in the various technology platforms.
Dirk Morrison: Also wonder what the implications of AI for informal, self-directed learning?
Kate Borowske: The context that you’re presenting this in, as “your own jazz band,” is brilliant. These tools presented as a “partner” in the “band” seems as though it might be less threatening to faculty. Sort of gamifies parts of course design…?
Dirk Morrison: Move from teacher-centric to student-centric? Recommender systems, AI-based tutoring?
Andrew Cole (UW-Whitewater): The course with the bot TA must have been 100-level right? It would be interesting to see if those results replicate in 300, 400 level courses