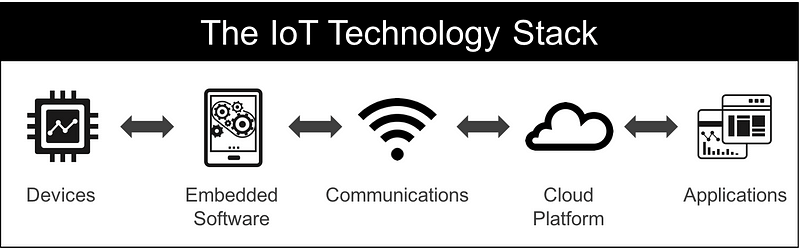
The first step to becoming an IoT Product Manager is to understand the 5 layers of the IoT technology stack.
1. Devices
Devices constitute the “things” in the Internet of Things. They act as the interface between the real and digital worlds.
2. Embedded software
Embedded software is the part that turns a device into a “smart device”. This part of the IoT technology stack enables the concept of “software-defined hardware”, meaning that a particular hardware device can serve multiple applications depending on the embedded software it is running.
Embedded Operating System
The complexity of your IoT solution will determine the type of embedded Operating System (OS) you need. Some of the key considerations include whether your application needs a real-time OS, the type of I/O support you need, and whether you need support for the full TCP/IP stack.
Common examples of embedded OS include Linux, Brillo (scaled-down Android), Windows Embedded, and VxWorks, to name a few.
Embedded Applications
This is the application(s) that run on top of the embedded OS and provide the functionality that’s specific to your IoT solution.
3. Communications
Communications refers to all the different ways your device will exchange information with the rest of the world. This includes both physical networks and the protocols you will use.
4. Cloud Platform
The cloud platform is the backbone of your IoT solution. If you are familiar with managing SaaS offerings, then you are well aware of everything that is entailed here. Your infrastructure will serve as the platform for these key areas:
Data Collection and Management
Your smart devices will stream information to the cloud. As you define the requirements of your solution, you need to have a good idea of the type and amount of data you’ll be collecting on a daily, monthly, and yearly basis.
Analytics
Analytics are one of they key components of any IoT solution. By analytics, I’m referring to the ability to crunch data, find patterns, perform forecasts, integrate machine learning, etc. It is the ability to find insights from your data and not the data alone that makes your solution valuable.
Cloud APIs
The Internet of Things is all about connecting devices and sharing data. This is usually done by exposing APIs at either the Cloud level or the device level. Cloud APIs allow your customers and partners to either interact with your devices or to exchange data. Remember that opening an API is not a technical decision, it’s a business decision.
This is the part of the stack that is most easily understood by Product teams and Executives. Your end-user applications are the part of the system that your customer will see and interact with. These applications will most likely be Web-based, and depending on your user needs, you might need separate apps for desktop, mobile, and even wearables.
The Bottom Line
As the Internet of Things continues to grow, the world will need an army of IoT-savvy Product Managers. And those Product Managers will need to understand each layer of the stack, and how they all fit together into a complete IoT solution.
As the cost of sensors and the connectivity necessary to support those sensors has decreased, this has given rise to a network of interconnected devices. This network is often described as the Internet of Things and it is providing a variety of information management challenges. For the library and publishing communities, the internet of things presents opportunities and challenges around data gathering, organization and processing of the tremendous amounts of data which the internet of things is generating. How will these data be incorporated into traditional publication, archiving and resource management systems? Additionally, how will the internet of things impact resource management within our community? In what ways will interconnected resources provide a better user experience for patrons and readers? This session will introduce concepts and potential implications of the internet of things on the information management community. It will also explore applications related to managing resources in a library environment that are being developed and implemented.
Education in the Internet of Things Bryan Alexander, Consultant;
How will the Internet of Things shape education? We can explore this question by assessing current developments, looking for future trends in the first initial projects. In this talk I point to new concepts for classroom and campus spaces, examining attendant rises in data gathering and analysis. We address student life possibilities and curricular and professional niches. We conclude with notes on campus strategy, including privacy, network support, and futures-facing organizations.
What Does The Internet of Things Mean to a Museum? Robert Weisberg, Senior Project Manager, Publications and Editorial Department; Metropolitan Museum of Art;
What does the Internet of Things mean to a museum? Museums have slowly been digitizing their collections for years, and have been replacing index cards with large (and costly, and labor-intensive) CMS’s long before that, but several factors have worked against adopting smart and scalable practices which could unleash data for the benefit of the institution, its collection, and its audiences. Challenges go beyond non-profit budgets in a very for-profit world and into the siloed behaviors learned from academia, practices borne of the uniqueness of museum collections, and the multi-faceted nature of modern museums which include not only curator, but conservators, educators, librarians, publishers, and increasing numbers of digital specialists. What have museums already done, what are they doing, and what are they preparing for, as big data becomes bigger and ever more-networked? The Role of the Research Library in Unpacking The Internet of Things Lauren di Monte, NCSU Libraries Fellow, Cyma Rubin Fellow, North Carolina State University
The Internet of Things (IoT) is a deceptively simple umbrella term for a range of socio-technical tools and processes that are shaping our social and economic worlds. Indeed, IoT represents a new infrastructural layer that has the power to impact decision-making processes, resources distribution plans, information access, and much more. Understanding what IoT is, how “things” get networked, as well as how IoT devices and tools are constructed and deployed, are important and emerging facets of information literacy. Research libraries are uniquely positioned to help students, researchers, and other information professionals unpack IoT and understand its place within our knowledge infrastructures and digital cultures. By developing and modeling the use of IoT devices for space and program assessment, by teaching patrons how to work with IoT hardware and software, and by developing methods and infrastructures to collect IoT devices and data, we can help our patrons unlock the potential of IoT and harness the power of networked knowledge.
Lauren Di Monte is a Libraries Fellow at NC State. In this role she develops programs that facilitate critical and creative engagements with technologies and develops projects to bring physical and traditional computing into scholarship across the disciplines. Her current research explores the histories and futures of STEM knowledge practices.
I’m not sure if the IoT will hit academic with the wave force of the Web in the 1990s, or become a minor tangent. What do schools have to do with Twittering refrigerators?
Here are a few possible intersections.
Changing up the campus technology space. IT departments will face supporting more technology strata in a more complex ecosystem. Help desks and CIOs alike will have to consider supporting sensors, embedded chips, and new devices. Standards, storage, privacy, and other policy issues will ramify.
Mutating the campus. We’ve already adjusted campus spaces by adding wireless coverage, enabling users and visitors to connect from nearly everywhere. What happens when benches are chipped, skateboards sport sensors, books carry RFID, and all sorts of new, mobile devices dot the quad? One British school offers an early example.
New forms of teaching and learning. Some of these take preexisting forms and amplify them, like tagging animals in the wild or collecting data about urban centers. The IoT lets us gather more information more easily and perform more work upon it. Then we could also see really new ways of learning, like having students explore an environment (built or natural) by using embedded sensors, QR codes, and live datastreams from items and locations. Instructors can build treasure hunts through campuses, nature preserves, museums, or cities. Or even more creative enterprises.
New forms of research. As with #3, but at a higher level. Researchers can gather and process data using networked swarms of devices. Plus academics studying and developing the IoT in computer science and other disciplines.
An environmental transformation. People will increasingly come to campus with experiences of a truly interactive, data-rich world. They will expect a growing proportion of objects to be at least addressable, if not communicative. This population will become students, instructors, and support staff. They will have a different sense of the boundaries between physical and digital than we now have in 2014. Will this transformed community alter a school’s educational mission or operations?
Society for Information Technology and Teacher Education site.aace.org
March 5 – 9, 2017 Austin, Texas, USA
Proposals Due: October 21, 2016
SITE 2017 is the 28th annual conference of the Society for Information Technology and Teacher Education. This society represents individual teacher educators and affiliated organizations of teacher educators in all disciplines, who are interested in the creation and dissemination of knowledge about the use of information technology in teacher education and faculty/staff development.
SITE is unique as the only organization which has as its sole focus the integration of instructional technologies into teacher education programs. SITE promotes the development and dissemination of theoretical knowledge, conceptual research, and professional practice knowledge through conferences, books, projects, and the Journal of Technology and Teacher Education (JTATE).
You are invited to attend and participate in this annual international forum which offer numerous opportunities to share your ideas, explore the research, development, and applications, and to network with the leaders in this important field of teacher education and technology.
The Conference Review Policy requires that each proposal will be peer- reviewed by three reviewers for inclusion in the conference program, and conference proceedings.
Enquiries: conf@aace.org
Hosted By: AACE.org – The Association for the Advancement of Computing in Education
Sponsored by: LearnTechLib.org – The Learning and Technology Library
In scholarly and scientific publishing, altmetrics are non-traditional metrics[2] proposed as an alternative[3] to more traditional citation impact metrics, such as impact factor and h-index.[4] The term altmetrics was proposed in 2010,[1] as a generalization of article level metrics,[5] and has its roots in the #altmetrics hashtag. Although altmetrics are often thought of as metrics about articles, they can be applied to people, journals, books, data sets, presentations, videos, source code repositories, web pages, etc. They are related to Webometrics, which had similar goals but evolved before the social web. Altmetrics did not originally cover citation counts.[6] It also covers other aspects of the impact of a work, such as how many data and knowledge bases refer to it, article views, downloads, or mentions in social media and news media.[7][8]
++++++++++++++++
more on analytics and metrics in education in this IMS blog
The data shared in June by the Office for Civil Rights, which compiled it from a 2013-2014 survey completed by nearly every school district and school in the United States. new is a report from Attendance Works and the Everyone Graduates Center that encourages schools and districts to use their own data to pinpoint ways to take on the challenge of chronic absenteeism.
The first is research that shows that missing that much school is correlated with “lower academic performance and dropping out.” Second, it also helps in identifying students earlier in the semester in order to get a jump on possible interventions.
The report offers a six-step process for using data tied to chronic absence in order to reduce the problem.
The first step is investing in “consistent and accurate data.” That’s where the definition comes in — to make sure people have a “clear understanding” and so that it can be used “across states and districts” with school years that vary in length. The same step also requires “clarifying what counts as a day of attendance or absence.”
The second step is to use the data to understand what the need is and who needs support in getting to school. This phase could involve defining multiple tiers of chronic absenteeism (at-risk, moderate or severe), and then analyzing the data to see if there are differences by student sub-population — grade, ethnicity, special education, gender, free and reduced price lunch, neighborhood or other criteria that require special kinds of intervention.
Step three asks schools and districts to use the data to identify places getting good results. By comparing chronic absence rates across the district or against schools with similar demographics, the “positive outliers” may surface, showing people that the problem isn’t unstoppable but something that can be addressed for the better.
Steps five and six call on schools and districts to help people understand why the absences are happening, develop ways to address the problem.
AT&T, Comcast, Verizon, and Time Warner have a “natural monopoly” since they’ve simply been at it the longest. While the Telecommunications Act of 1996 attempted to incentivize competition to upset these established businesses, it didn’t take into account the near impossibility of doing so. As Howard Zinn wrote in A People’s History of the United States, the Telecommunications Act of 1996 simply “enabled the handful of corporations dominating the airwaves to expand their power further.”
Chattanooga has somewhat famously installed its own. Santa Monica also has its own fiber network. The reason these communities have been successful is because they don’t look at these networks as a luxury, but as a mode of self sustainability.
The 19th century’s ghost towns exist because the gold ran out. The 21st century’s ghost towns might materialize because the Internet never showed up.
W3Schools – Fantastic set of interactive tutorials for learning different languages. Their SQL tutorial is second to none. You’ll learn how to manipulate data in MySQL, SQL Server, Access, Oracle, Sybase, DB2 and other database systems.
Treasure Data – The best way to learn is to work towards a goal. That’s what this helpful blog series is all about. You’ll learn SQL from scratch by following along with a simple, but common, data analysis scenario.
10 Queries – This course is recommended for the intermediate SQL-er who wants to brush up on his/her skills. It’s a series of 10 challenges coupled with forums and external videos to help you improve your SQL knowledge and understanding of the underlying principles.
TryR – Created by Code School, this interactive online tutorial system is designed to step you through R for statistics and data modeling. As you work through their seven modules, you’ll earn badges to track your progress helping you to stay on track.
Leada – If you’re a complete R novice, try Lead’s introduction to R. In their 1 hour 30 min course, they’ll cover installation, basic usage, common functions, data structures, and data types. They’ll even set you up with your own development environment in RStudio.
Advanced R – Once you’ve mastered the basics of R, bookmark this page. It’s a fantastically comprehensive style guide to using R. We should all strive to write beautiful code, and this resource (based on Google’s R style guide) is your key to that ideal.
Swirl – Learn R in R – a radical idea certainly. But that’s exactly what Swirl does. They’ll interactively teach you how to program in R and do some basic data science at your own pace. Right in the R console.
Python for beginners – The Python website actually has a pretty comprehensive and easy-to-follow set of tutorials. You can learn everything from installation to complex analyzes. It also gives you access to the Python community, who will be happy to answer your questions.
PythonSpot – A complete list of Python tutorials to take you from zero to Python hero. There are tutorials for beginners, intermediate and advanced learners.
Read all about it: data mining books
Data Jujitsu: The Art of Turning Data into Product – This free book by DJ Patil gives you a brief introduction to the complexity of data problems and how to approach them. He gives nice, understandable examples that cover the most important thought processes of data mining. It’s a great book for beginners but still interesting to the data mining expert. Plus, it’s free!
Data Mining: Concepts and Techniques – The third (and most recent) edition will give you an understanding of the theory and practice of discovering patterns in large data sets. Each chapter is a stand-alone guide to a particular topic, making it a good resource if you’re not into reading in sequence or you want to know about a particular topic.
Mining of Massive Datasets – Based on the Stanford Computer Science course, this book is often sighted by data scientists as one of the most helpful resources around. It’s designed at the undergraduate level with no formal prerequisites. It’s the next best thing to actually going to Stanford!
Big Data, Data Mining, and Machine Learning: Value Creation for Business Leaders and Practitioners – This book is a must read for anyone who needs to do applied data mining in a business setting (ie practically everyone). It’s a complete resource for anyone looking to cut through the Big Data hype and understand the real value of data mining. Pay particular attention to the section on how modeling can be applied to business decision making.
Hadoop: The Definitive Guide – As a data scientist, you will undoubtedly be asked about Hadoop. So you’d better know how it works. This comprehensive guide will teach you how to build and maintain reliable, scalable, distributed systems with Apache Hadoop. Make sure you get the most recent addition to keep up with this fast-changing service.
Online learning: data mining webinars and courses
DataCamp – Learn data mining from the comfort of your home with DataCamp’s online courses. They have free courses on R, Statistics, Data Manipulation, Dynamic Reporting, Large Data Sets and much more.
Coursera – Coursera brings you all the best University courses straight to your computer. Their online classes will teach you the fundamentals of interpreting data, performing analyzes and communicating insights. They have topics for beginners and advanced learners in Data Analysis, Machine Learning, Probability and Statistics and more.
Udemy – With a range of free and pay for data mining courses, you’re sure to find something you like on Udemy no matter your level. There are 395 in the area of data mining! All their courses are uploaded by other Udemy users meaning quality can fluctuate so make sure you read the reviews.
CodeSchool – These courses are handily organized into “Paths” based on the technology you want to learn. You can do everything from build a foundation in Git to take control of a data layer in SQL. Their engaging online videos will take you step-by-step through each lesson and their challenges will let you practice what you’ve learned in a controlled environment.
Udacity – Master a new skill or programming language with Udacity’s unique series of online courses and projects. Each class is developed by a Silicon Valley tech giant, so you know what your learning will be directly applicable to the real world.
Treehouse – Learn from experts in web design, coding, business and more. The video tutorials from Treehouse will teach you the basics and their quizzes and coding challenges will ensure the information sticks. And their UI is pretty easy on the eyes.
Learn from the best: top data miners to follow
John Foreman – Chief Data Scientist at MailChimp and author of Data Smart, John is worth a follow for his witty yet poignant tweets on data science.
DJ Patil – Author and Chief Data Scientist at The White House OSTP, DJ tweets everything you’ve ever wanted to know about data in politics.
Nate Silver – He’s Editor-in-Chief of FiveThirtyEight, a blog that uses data to analyze news stories in Politics, Sports, and Current Events.
Andrew Ng – As the Chief Data Scientist at Baidu, Andrew is responsible for some of the most groundbreaking developments in Machine Learning and Data Science.
Bernard Marr – He might know pretty much everything there is to know about Big Data.
Gregory Piatetsky – He’s the author of popular data science blog KDNuggets, the leading newsletter on data mining and knowledge discovery.
Christian Rudder – As the Co-founder of OKCupid, Christian has access to one of the most unique datasets on the planet and he uses it to give fascinating insight into human nature, love, and relationships
Dean Abbott – He’s contributed to a number of data blogs and authored his own book on Applied Predictive Analytics. At the moment, Dean is Chief Data Scientist at SmarterHQ.
Practice what you’ve learned: data mining competitions
Kaggle – This is the ultimate data mining competition. The world’s biggest corporations offer big prizes for solving their toughest data problems.
Stack Overflow – The best way to learn is to teach. Stackoverflow offers the perfect forum for you to prove your data mining know-how by answering fellow enthusiast’s questions.
TunedIT – With a live leaderboard and interactive participation, TunedIT offers a great platform to flex your data mining muscles.
DrivenData – You can find a number of nonprofit data mining challenges on DataDriven. All of your mining efforts will go towards a good cause.
Quora – Another great site to answer questions on just about everything. There are plenty of curious data lovers on there asking for help with data mining and data science.
Meet your fellow data miner: social networks, groups and meetups
Facebook – As with many social media platforms, Facebook is a great place to meet and interact with people who have similar interests. There are a number of very active data mining groups you can join.
LinkedIn – If you’re looking for data mining experts in a particular field, look no further than LinkedIn. There are hundreds of data mining groups ranging from the generic to the hyper-specific. In short, there’s sure to be something for everyone.
Meetup – Want to meet your fellow data miners in person? Attend a meetup! Just search for data mining in your city and you’re sure to find an awesome group near you.
Data storytelling is the realization of great data visualization. We’re seeing data that’s been analyzed well and presented in a way that someone who’s never even heard of data science can get it.
Google’s Cole Nussbaumer provides a friendly reminder of what data storytelling actually is, it’s straightforward, strategic, elegant, and simple.