“They were taking both sides of the argument this past weekend and pushing them out from their troll farms as much as they could to just raise the noise level in America and make a big issue seem like an even bigger issue as they’re trying to push divisiveness in the country,” as Sen. James Lankford, R-Okla., said in the fall.
Tools such as the German Marshall Fund’s “Hamilton 68” dashboard track Russian-linked accounts in real time to show what links, phrases and hashtags are circulating.
The Trump administration detailed the threat — without any specific mention of the 2016 interference — in the new National Security Strategy it released at the end of December.
The Republicans might have been tarnished by the St Petersburg troll factory, but Democratic fantasies about social media were rubbished in the process
The ads in question were memes, manufactured and posted to a number of bluntly named, pseudo-American Facebook accounts in 2016 by workers at a troll farm in St Petersburg, Russia. There were thousands of these ads, it seems, plus parallel efforts on Instagram and Twitter. Between them, they reached over 100 million people.
The memes were big news for a while because they showed what Russian interference in the 2016 election actually looked like, in vivid color. Eventually the story faded, though, in part because it was superseded by other stories, but also, I think, because the Russian ad story was deeply distasteful to both sides of our atrophied political debate.
The ads were clumsily written. They were rife with spelling errors and poor grammar. Their grasp of American history was awful. And over them all hovered a paranoid fear that the powerful were scheming to flip the world upside-down in the most outlandish ways: to turn our country over to the undocumented … to punish the hardworking … to crack down on patriots and Christians … to enact Sharia law right here at home.
The social media platforms aren’t neutral arbiters, selflessly serving the needs of society. As is all too obvious now, they are monopolies that manipulate us in a hundred different ways, selecting our news, steering us towards what we need to buy. The corporate entities behind them wield enormous power in Washington, too, filling Democratic campaign coffers and keeping the revolving door turning for trusted servants. Those who don’t comply get disciplined.
++++++++++++++
Russia calls for answers after Chechen leader’s Instagram is blocked
Internet watchdog demands explanation after Ramzan Kadyrov claimed Facebook also suspended him without explanation
Kadyrov has accused the US government of pressuring the social networks to disable his accounts, which he said were blocked on Saturday without explanation. The US imposed travel and financial sanctions on Kadyrov last week over numerous allegations of human rights abuses.
The former rebel fighter, who is now loyal to the Russian president, Vladimir Putin, is a fan of social media, particularly Instagram, which he has used in recent years to make barely veiled death threats against Kremlin critics.
Leonid Levin, the head of the Russian parliament’s information technologies and communications committee, suggested the move by Facebook and Instagram was an attack on freedom of speech.
Dzhambulat Umarov, the Chechen press and information minister, described the blocking of Kadyrov’s accounts as a “vile” cyber-attack by the US.
Neither Instagram nor Facebook had commented at the time of publication.
In 2015, Kadyrov urged Chechen men not to let their wives use the WhatsApp messaging service after an online outcry over the forced marriage of a 17-year-old Chechen to a 47-year-old police chief. “Do not write such things. Men, take your women out of WhatsApp,” he said.
this why metadata was entered in the post-processed MP4 file using the VLC player
export
H.264 . / iPAD 480p 29.9 fps
Shortcuts:
If you are using Premiere CC: 1. File/New/Sequence. 2. Ctrl M is the shortcut to export (M is for media)
Issues
the two Apple/Macs will deliver error messages with both the export to the MP4 format and for burning the CDs and DVDs.
e.g.
other issues
regular restart required for new capture
error messages e.g.
other issues:
audio. Audio synchronization during the digitization is off. Solution: possible solution is the last of this thread : https://forums.adobe.com/thread/2217377
open in in QT Pro copy an segment then past it into a new QT file and save. It then plays normally in Adobe products.
old Apple desktops. needed to be rebuild and reformatted.
Apple burner issues. issues with Premiere license (bigger organization, bigger bureaucracy – keep the licenses within the library, not with IT or the business department)
old VCRs – one of the VCRs was recording bad audio signal
old VHS tapes: the signal jump makes the digital recording stop, thus requiring a constant attendance of the digitization, instead of letting it be digitized and working on something else
the person who is uploading the digitized VHS movies can “Add Collaborator”
The collaborator can be “co-editor” and / or “co-publisher”
Thus, at the moment, Tom Hegert has been designated to a digitized VHS video as Co-:Publisher and Rhonda Huisman as “Co-Editor.”
Please DO log in into MediaSpace with your STAR ID and confirm that you can locate the video and you can, respectively edit its metadata.
If you can edit the video, this means that the proposed system will work, since the Library can follow the same pattern to “distribute” the videos to the instructors, who these videos are used by; and, respectively these instructors can further control the distribution of the videos in their classes.
issues:
sharing the videos from the generic Library account for MediaSpace to the MediaSPace account of the faculty who had requested the digitization either through sending the link to the video or publish in channel (we called our channel “digitized VHS”)
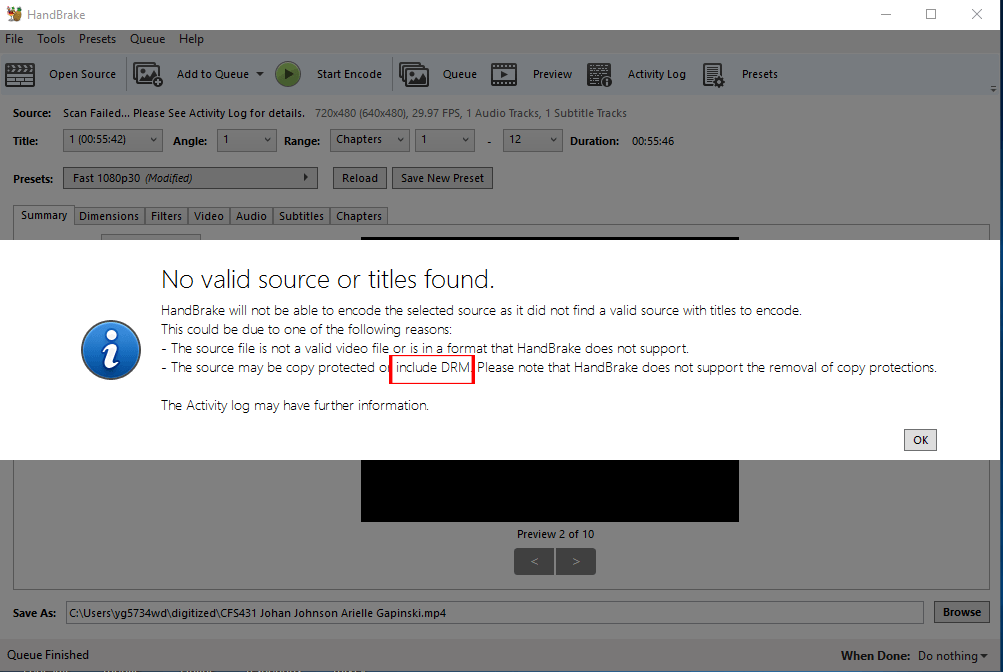
issue: ripping off content from DVD.
Faculty (mostly teaching online / hybrid courses) want to place teaching material from DVD to MediaSpace. Most DVDs are DRM protected.
Handbreak (https://handbrake.fr/) does not allow ripping DRM-ed DVDs. to bypass this Handbreak issue, we use DVD Decrypter before we run the file through Handbreak
Solutions:
From: “Lanska, Jeremiah K” <Jeremiah.Lanska@ridgewater.edu> Date: Tuesday, September 11, 2018 at 10:03 AM
I use a software on a MAC called MacX DVD Video Converter Pro. https://www.macxdvd.com/
I convert videos to MP4 with this and it just works for just about any DVD. Then upload them to MediaSpace.
From: “Docken, Marti L” <Marti.Docken@saintpaul.edu> Date: Tuesday, September 11, 2018 at 8:17 AM
Good morning Plamen. Here at Saint Paul College, we are asked to get permission from owner when we are looking at making any alterations to a video, tape, etc. This is true of adding closed captioning as well. The attached are forms given by Minnesota State which they may have an updated form.
Thank you and have a wonderful day.
Marti Docken Instructional Technology Specialist 651.846.1339 marti.docken@saintpaul.edu
From: Geri Wilson Sent: Friday, September 14, 2018 3:23 PM
What I do with DVDs is give a warning to the faculty that the MediaSpace link with the captions I’ve created should not be widely shared and should be treated as if it were still a DVD that can be shown in the classroom, but not posted on D2L. Because even if we use those forms, I don’t believe it gives us the right to use the video in a broader way. However, a safer approach might be to burn a new DVD with captions, so that it’s still in the same format that can’t be misused as easily.
Just my 2 cents. Geri
From: “Hunter, Gary B” <Gary.Hunter@minnstate.edu> Date: Friday, September 14, 2018 at 2:55 PM To: Plamen Miltenoff_old <pmiltenoff@stcloudstate.edu> Subject: RE: Process of ripping DVD video to mount it on MediaSpace
I’ll assume the contents of the DVDs are movies/films unless I hear otherwise from you. There’s a lot we need to consider from a copyright perspective. Let me know a day and time that we can touch base via a phone call. Next week my schedule is flexible, so let me know what day and time work for you. Until we speak, here’s some of the information related to making copies of copyrighted works for nonprofit teaching purposes.
There are two sections of the Copyright Act that authorize “copying” of copyrighted works for nonprofit educational purposes. It doesn’t matter if the copyrighted works are being copied from DVDs, CDs, flash drives, a computer’s hard drive, etc., the same sections of the Copyright Act apply.
Section 110(2), also known as the TEACH Act, allows nonprofit educational institutions to make a digital copy of a nondramatic copyrighted work and save it to a server for online and hybrid teaching. I have a TEACH Act checklist on the IP Tools & Forms webpage at http://www.minnstate.edu/system/asa/academicaffairs/policy/copyright/forms.html. The checklist identifies the few things that may not be copied under this section of the Copyright Act. If an instructor meets the various requirements on the checklist, than you can make a digital copy of the entire nondramatic copyrighted work and save it to MediaSpace. For nondramatic works, all MinnState instructors should be able to complete the TEACH Act checklist successfully, so I wouldn’t request a completed checklist from them.
Under the TEACH Act, nonprofit educational institutions are only permitted to make a digital copy of reasonable and limited portions of dramatic copyrighted works. Movies and films are usually dramatic works. Most people in higher education interpret “reasonable and limited portions” to mean something less than the whole and not the entire movie/film. There are several guidance documents on the TEACH Act on the IP Tools & Forms webpage that go into greater detail as to what is reasonable and limited portions. Unfortunately, this section only authorizes the copying of part of the movie/film and not the entire thing.
Section 107 Fair Use of the Copyright Act is the second section that permits copying of copyrighted works for nonprofit educational purposes. Fair Use is used more than any other section to make copies of copyrighted works for nonprofit educational purposes. An instructor needs to complete a fair Use Checklist showing the proposed copying is authorized by fair use. An instructor who completes a Fair Use Checklist that ends up being 50/50 or more in support of fair use for their proposed copying of a copyrighted work, should be able to make the digital copy. Fair Use has some nuances in it for unique situations. Let’s set up a phone call to further discuss them. There is also a flow chart that may helpful at http://www.minnstate.edu/system/asa/academicaffairs/policy/copyright/docs/Flow%20Chart-Using%20video%20in%20Online%20-%20D2L%20Courses.pdf.
We also have to consider whether or not the movies/films were purchased with “personal use” rights or “public performance” rights. Or if an educational license or some similar type of license gives us permission to make copies or publicly perform the movie/film. More layers of the onion that need peeled back to address the copyright concerns.
++++++++++++++
Issue: confidentiality
All digitized material is backedup on DVDs, whether faculty wants a DVD or not.
Some video content is confidential (e.g. interviews with patients) and faculty does not want any extra copies, but the DVD submitted to them. How do we archive / do we archive the content then?
Burning (Archiving)
where to store the burned DVDs? their shelf life is 12 years.
DVD’s must be labeled with soft tip perm marker, not labels. labels glue ages quickly.
all our desktops are outdated (5+ years and older). We used two Apple/Macs. OS El Captain, Version 10.11.6, 2.5 Gxz Intel Core i5. 8GB memory, 1333 MHz DDR3, Graphic Card AMD Radeon HD 6750 MD 512 MB
Question about the process of archiving the CDs and DVDs after burning. What is the best way to archive the digitized material? Store the CD and DVDs? Keep them in the “cloud?”
Question about the management of working files: 1. Premiere digitizes the original hi-quality file in .mov format and it is in GB. The export is in .mp4 format and it is in MB. Is it worth to store the GB-size .mov format and for how long, considering that the working station has a limited HDD of 200GB
we decided to export two types of files using Adobe Premiere: a) a low end .MP4 file about several hundred megabites, which respectively is uploaded in SCSU Media Space (AKA Kaltura) and b) one high-end (better quality) one the realm of several GBs, which was the archived copy
We placed a request for two 2TB HDD with the library dean and 10TB file space with the SCSU IT department. Idea being to have the files for MediaSpace readily available on the hardrives, if we have to make them available to faculty and the high-end files being stored on the SCSU file server.
++++++++++++++++++
Nov. 2019: transfer of accounts. The generic SCSULibraryVideo account is discontinued because of the August 2019 transition to the minnstate.edu. Agreed to host the accumulated digitized videos under the private account of one of the team members, who will be assigning the other members and the requesting faculty as co-editors.
++++++++++++++++++
2. correspondence among Greg J, Tom H and Plamen
email correspondence Greg, Tom, Plamen regarding Kaltura account:
From: Greg <gsjorgensen@stcloudstate.edu> Date: Friday, November 17, 2017 at 11:32 AM To: Plamen Miltenoff <pmiltenoff@stcloudstate.edu> Subject: RE: Question Kaltura
Plamen,
Channels are not required using this workflow. Just the collaboration change.
–g–
From: Miltenoff, Plamen Sent: Friday, November 17, 2017 11:31 AM To: Jorgensen, Greg S. <gsjorgensen@stcloudstate.edu>; Hergert, Thomas R. <trhergert@stcloudstate.edu> Subject: Question Kaltura
Greg,
About the channel:
Do I create one channel (videos)?
It seems to be a better idea to create separate channels for each of faculty, who’s videotapes are digitized.
******* any user you wish to collaborate with, will need to first sign in to mediaspace in order to provision their account.**** After they have signed in, you will be able to add them as collaborator.
Once they’ve been added, they will have access to the video in their MedisSpace account.
Like so:
From the My Media area:
Click ‘Filters’:
Then choose either media I can publish, or media I can edit:
If you want to simply change ownership to the requestor (for video available only to a single person), just choose change media owner on the collaboration tab.
The process above will allow for any number of collaborators, in a fashion similar to ‘on reserve’.
–g–
From: Miltenoff, Plamen Sent: Friday, November 17, 2017 11:19 AM To: Jorgensen, Greg S. <gsjorgensen@stcloudstate.edu>; Hergert, Thomas R. <trhergert@stcloudstate.edu> Subject: FW: Supplemental Account Request Status
Tom,
I submitted the request to Greg with the “SCSULibraryVideo” name
Greg, I submitted, Tom, Rachel W and Rhonda H (and you) as “owners.”
Pls, if possible, do not assigned to Tom ownership rights yet and add him later on.
I also received your approval, so I am starting to work on it
This message confirms your request for a new Supplemental Account with the requested username of SCSULibraryVideo. Please allow 2-3 business days for processing. You will be notified by email when your request is approved or denied. You may also check the status of your request by returning to the Supplemental Accounts Maintenance site.
Thank you for your request and please contact us with questions or concerns.
Once you’ve done that, just let me know the name of the account. (LibraryVideoDrop, SCSULibraryVideo, etc….)
I’ll then add it to the Mediaspace access list.
If there’s already an account to which you have access, we can use that, too. Remember, though, credentials will be shared at least between the two of you.
Well, that is a good question. Do we need a “STAR ID” type of account for the library?
If so, who will be the person to talk to. After Diane Schmitt, I do not know who to ask
Tom, can you ask the library dean’s office for any “generic” account?
Greg, for the time being, is it possible to have me as the “owner” of that account? Would that conflict with my current Kaltura account/content?
Can I participate for this project with my student account (as you helpled me several weeks ago restore it for D2L usage)?
Yes, except that there may be needs for multiple faculty to access the files. Think of it as analogous to DVDs on reserve or even in the general collection.
I think we’re hoping for an account from which we can share Library resources such as the digitized versions of VHS tapes that Plamen and I are creating. As I understand it, a closed channel is probably not the best answer. We need a common repository that can have open access to SCSU Kaltura users.
A single account can’t really be shared in the way you’re asking, but we can easily add a dept. supplemental account to Mediaspace. I just need the name of the account.
Depending on what you intend, maybe a closed channel? Create a closed channel and add individuals as needed?
Can you help me create a MediaSpace account for the library use.
How can it be tight up to the STAR ID login specifications?
Is it possible, let’s say Tom and I to use our STAR ID to login into such account?
Any info is welcome…
Plamen
++++++++++++
3. correspondence on the LITA listserv regarding “best practices for in house digital conversion”
From: <lita-l-request@lists.ala.org> on behalf of Sharona Ginsberg <lita-l@lists.ala.org> Reply-To: “lita-l@lists.ala.org” <lita-l@lists.ala.org> Date: Tuesday, November 21, 2017 at 10:07 AM To: “lita-l@lists.ala.org” <lita-l@lists.ala.org> Subject: Re: [lita-l] best practices for in house digital conversion
I’m at an academic rather than public library, but you can see what we offer for digital conversion here: https://www.oswego.edu/library/digital-conversion. We’ve been generally happy with our equipment, and I especially think the Elgato Video Capture device (VHS to digital) is a good tool.
– Sharona
From: <lita-l-request@lists.ala.org> on behalf of Molly Schwartz <mschwartz@metro.org> Reply-To: “lita-l@lists.ala.org” <lita-l@lists.ala.org> Date: Tuesday, November 21, 2017 at 10:03 AM To: “lita-l@lists.ala.org” <lita-l@lists.ala.org> Subject: Re: [lita-l] best practices for in house digital conversion
I would also definitely recommend DCPL’s Memory Lab and the project to build a Memory Lab Network, which is more applicable to public libraries.
best,
Molly
On Tue, Nov 21, 2017 at 10:49 AM, Stewart Wilson <SWilson@onlib.org> wrote:
Hi all,
I know there is a lot of information already out here, but is anyone up for a conversation about media conversion technologies for public library patrons?
I’m interested in best practices and recommended technologies or guides that you use in your system.
Anything that converts projector slides, 35mm, VHS, photographs, cassette, etc.
We are building a new PC for this and 3D rendering, so any recommendations for things like soundcards or video capture cards are also useful.
Thanks for your help; this group is the best.
Stew Wilson
Paralibrarian for Network Administration and Technology
“The challenge is to make data discoverable, usable, assessable, intelligible, and interpretable, and do so for extended periods of time…To restate the premise of this book, the value of data lies in their use. Unless stakeholders can agree on what to keep and why, and invest in the invisible work necessary to sustain knowledge infrastructures, big data and little data alike will become no data.”
he premise that data are not natural objects with their own essence, Borgman rather explores the different values assigned to them, as well as their many variations according to place, time, and the context in which they are collected. It is specifically through six “provocations” that she offers a deep engagement with different aspects of the knowledge industry. These include the reproducibility, sharing, and reuse of data; the transmission and publication of knowledge; the stability of scholarly knowledge, despite its increasing proliferation of forms and modes; the very porosity of the borders between different areas of knowledge; the costs, benefits, risks, and responsibilities related to knowledge infrastructure; and finally, investment in the sustainable acquisition and exploitation of data for scientific research.
beyond the six provocations, there is a larger question concerning the legitimacy, continuity, and durability of all scientific research—hence the urgent need for further reflection, initiated eloquently by Borgman, on the fact that “despite the media hyperbole, having the right data is usually better than having more data”
o Data management (Pages xviii-xix)
o Data definition (4-5 and 18-29)
p. 5 big data and little data are only awkwardly analogous to big science and little science. Modern science, or big science inDerek J. de Solla Price (https://en.wikipedia.org/wiki/Big_Science) is characterized by international, collaborative efforts and by the invisible colleges of researchers who know each other and who exchange information on a formal and informal basis. Little science is the three hundred years of independent, smaller-scale work to develop theory and method for understanding research problems. Little science is typified by heterogeneous methods, heterogeneous data and by local control and analysis.
p. 8 The Long Tail
a popular way of characterizing the availability and use of data in research areas or in economic sectors. https://en.wikipedia.org/wiki/Long_tail
o Provocations (13-15)
o Digital data collections (21-26)
o Knowledge infrastructures (32-35)
o Open access to research (39-42)
o Open technologies (45-47)
o Metadata (65-70 and 79-80)
o Common resources in astronomy (71-76)
o Ethics (77-79)
o Research Methods and data practices, and, Sensor-networked science and technology (84-85 and 106-113)
o Knowledge infrastructures (94-100)
o COMPLETE survey (102-106)
o Internet surveys (128-143)
o Internet survey (128-143)
o Twitter (130-133, 138-141, and 157-158(
o Pisa Clark/CLAROS project (179-185)
o Collecting Data, Analyzing Data, and Publishing Findings (181-184)
o Buddhist studies 186-200)
o Data citation (241-268)
o Negotiating authorship credit (253-256)
o Personal names (258-261)
o Citation metrics (266-209)
o Access to data (279-283)
Applications for the 2018 Institute will be accepted between December 1, 2017 and January 27, 2018. Scholars accepted to the program will be notified in early March 2018.
Title:
Learning to Harness Big Data in an Academic Library
Abstract (200)
Research on Big Data per se, as well as on the importance and organization of the process of Big Data collection and analysis, is well underway. The complexity of the process comprising “Big Data,” however, deprives organizations of ubiquitous “blue print.” The planning, structuring, administration and execution of the process of adopting Big Data in an organization, being that a corporate one or an educational one, remains an elusive one. No less elusive is the adoption of the Big Data practices among libraries themselves. Seeking the commonalities and differences in the adoption of Big Data practices among libraries may be a suitable start to help libraries transition to the adoption of Big Data and restructuring organizational and daily activities based on Big Data decisions. Introduction to the problem. Limitations
The redefinition of humanities scholarship has received major attention in higher education. The advent of digital humanities challenges aspects of academic librarianship. Data literacy is a critical need for digital humanities in academia. The March 2016 Library Juice Academy Webinar led by John Russel exemplifies the efforts to help librarians become versed in obtaining programming skills, and respectively, handling data. Those are first steps on a rather long path of building a robust infrastructure to collect, analyze, and interpret data intelligently, so it can be utilized to restructure daily and strategic activities. Since the phenomenon of Big Data is young, there is a lack of blueprints on the organization of such infrastructure. A collection and sharing of best practices is an efficient approach to establishing a feasible plan for setting a library infrastructure for collection, analysis, and implementation of Big Data.
Limitations. This research can only organize the results from the responses of librarians and research into how libraries present themselves to the world in this arena. It may be able to make some rudimentary recommendations. However, based on each library’s specific goals and tasks, further research and work will be needed.
Big Data is becoming an omnipresent term. It is widespread among different disciplines in academia (De Mauro, Greco, & Grimaldi, 2016). This leads to “inconsistency in meanings and necessity for formal definitions” (De Mauro et al, 2016, p. 122). Similarly, to De Mauro et al (2016), Hashem, Yaqoob, Anuar, Mokhtar, Gani and Ullah Khan (2015) seek standardization of definitions. The main connected “themes” of this phenomenon must be identified and the connections to Library Science must be sought. A prerequisite for a comprehensive definition is the identification of Big Data methods. Bughin, Chui, Manyika (2011), Chen et al. (2012) and De Mauro et al (2015) single out the methods to complete the process of building a comprehensive definition.
In conjunction with identifying the methods, volume, velocity, and variety, as defined by Laney (2001), are the three properties of Big Data accepted across the literature. Daniel (2015) defines three stages in big data: collection, analysis, and visualization. According to Daniel, (2015), Big Data in higher education “connotes the interpretation of a wide range of administrative and operational data” (p. 910) and according to Hilbert (2013), as cited in Daniel (2015), Big Data “delivers a cost-effective prospect to improve decision making” (p. 911).
The importance of understanding the process of Big Data analytics is well understood in academic libraries. An example of such “administrative and operational” use for cost-effective improvement of decision making are the Finch & Flenner (2016) and Eaton (2017) case studies of the use of data visualization to assess an academic library collection and restructure the acquisition process. Sugimoto, Ding & Thelwall (2012) call for the discussion of Big Data for libraries. According to the 2017 NMC Horizon Report “Big Data has become a major focus of academic and research libraries due to the rapid evolution of data mining technologies and the proliferation of data sources like mobile devices and social media” (Adams, Becker, et al., 2017, p. 38).
Power (2014) elaborates on the complexity of Big Data in regard to decision-making and offers ideas for organizations on building a system to deal with Big Data. As explained by Boyd and Crawford (2012) and cited in De Mauro et al (2016), there is a danger of a new digital divide among organizations with different access and ability to process data. Moreover, Big Data impacts current organizational entities in their ability to reconsider their structure and organization. The complexity of institutions’ performance under the impact of Big Data is further complicated by the change of human behavior, because, arguably, Big Data affects human behavior itself (Schroeder, 2014).
De Mauro et al (2015) touch on the impact of Dig Data on libraries. The reorganization of academic libraries considering Big Data and the handling of Big Data by libraries is in a close conjunction with the reorganization of the entire campus and the handling of Big Data by the educational institution. In additional to the disruption posed by the Big Data phenomenon, higher education is facing global changes of economic, technological, social, and educational character. Daniel (2015) uses a chart to illustrate the complexity of these global trends. Parallel to the Big Data developments in America and Asia, the European Union is offering access to an EU open data portal (https://data.europa.eu/euodp/home ). Moreover, the Association of European Research Libraries expects under the H2020 program to increase “the digitization of cultural heritage, digital preservation, research data sharing, open access policies and the interoperability of research infrastructures” (Reilly, 2013).
The challenges posed by Big Data to human and social behavior (Schroeder, 2014) are no less significant to the impact of Big Data on learning. Cohen, Dolan, Dunlap, Hellerstein, & Welton (2009) propose a road map for “more conservative organizations” (p. 1492) to overcome their reservations and/or inability to handle Big Data and adopt a practical approach to the complexity of Big Data. Two Chinese researchers assert deep learning as the “set of machine learning techniques that learn multiple levels of representation in deep architectures (Chen & Lin, 2014, p. 515). Deep learning requires “new ways of thinking and transformative solutions (Chen & Lin, 2014, p. 523). Another pair of researchers from China present a broad overview of the various societal, business and administrative applications of Big Data, including a detailed account and definitions of the processes and tools accompanying Big Data analytics. The American counterparts of these Chinese researchers are of the same opinion when it comes to “think about the core principles and concepts that underline the techniques, and also the systematic thinking” (Provost and Fawcett, 2013, p. 58). De Mauro, Greco, and Grimaldi (2016), similarly to Provost and Fawcett (2013) draw attention to the urgent necessity to train new types of specialists to work with such data. As early as 2012, Davenport and Patil (2012), as cited in Mauro et al (2016), envisioned hybrid specialists able to manage both technological knowledge and academic research. Similarly, Provost and Fawcett (2013) mention the efforts of “academic institutions scrambling to put together programs to train data scientists” (p. 51). Further, Asomoah, Sharda, Zadeh & Kalgotra (2017) share a specific plan on the design and delivery of a big data analytics course. At the same time, librarians working with data acknowledge the shortcomings in the profession, since librarians “are practitioners first and generally do not view usability as a primary job responsibility, usually lack the depth of research skills needed to carry out a fully valid” data-based research (Emanuel, 2013, p. 207).
Borgman (2015) devotes an entire book to data and scholarly research and goes beyond the already well-established facts regarding the importance of Big Data, the implications of Big Data and the technical, societal, and educational impact and complications posed by Big Data. Borgman elucidates the importance of knowledge infrastructure and the necessity to understand the importance and complexity of building such infrastructure, in order to be able to take advantage of Big Data. In a similar fashion, a team of Chinese scholars draws attention to the complexity of data mining and Big Data and the necessity to approach the issue in an organized fashion (Wu, Xhu, Wu, Ding, 2014).
Bruns (2013) shifts the conversation from the “macro” architecture of Big Data, as focused by Borgman (2015) and Wu et al (2014) and ponders over the influx and unprecedented opportunities for humanities in academia with the advent of Big Data. Does the seemingly ubiquitous omnipresence of Big Data mean for humanities a “railroading” into “scientificity”? How will research and publishing change with the advent of Big Data across academic disciplines?
Reyes (2015) shares her “skinny” approach to Big Data in education. She presents a comprehensive structure for educational institutions to shift “traditional” analytics to “learner-centered” analytics (p. 75) and identifies the participants in the Big Data process in the organization. The model is applicable for library use.
Being a new and unchartered territory, Big Data and Big Data analytics can pose ethical issues. Willis (2013) focusses on Big Data application in education, namely the ethical questions for higher education administrators and the expectations of Big Data analytics to predict students’ success. Daries, Reich, Waldo, Young, and Whittinghill (2014) discuss rather similar issues regarding the balance between data and student privacy regulations. The privacy issues accompanying data are also discussed by Tene and Polonetsky, (2013).
Privacy issues are habitually connected to security and surveillance issues. Andrejevic and Gates (2014) point out in a decision making “generated by data mining, the focus is not on particular individuals but on aggregate outcomes” (p. 195). Van Dijck (2014) goes into further details regarding the perils posed by metadata and data to the society, in particular to the privacy of citizens. Bail (2014) addresses the same issue regarding the impact of Big Data on societal issues, but underlines the leading roles of cultural sociologists and their theories for the correct application of Big Data.
Library organizations have been traditional proponents of core democratic values such as protection of privacy and elucidation of related ethical questions (Miltenoff & Hauptman, 2005). In recent books about Big Data and libraries, ethical issues are important part of the discussion (Weiss, 2018). Library blogs also discuss these issues (Harper & Oltmann, 2017). An academic library’s role is to educate its patrons about those values. Sugimoto et al (2012) reflect on the need for discussion about Big Data in Library and Information Science. They clearly draw attention to the library “tradition of organizing, managing, retrieving, collecting, describing, and preserving information” (p.1) as well as library and information science being “a historically interdisciplinary and collaborative field, absorbing the knowledge of multiple domains and bringing the tools, techniques, and theories” (p. 1). Sugimoto et al (2012) sought a wide discussion among the library profession regarding the implications of Big Data on the profession, no differently from the activities in other fields (e.g., Wixom, Ariyachandra, Douglas, Goul, Gupta, Iyer, Kulkami, Mooney, Phillips-Wren, Turetken, 2014). A current Andrew Mellon Foundation grant for Visualizing Digital Scholarship in Libraries seeks an opportunity to view “both macro and micro perspectives, multi-user collaboration and real-time data interaction, and a limitless number of visualization possibilities – critical capabilities for rapidly understanding today’s large data sets (Hwangbo, 2014).
The importance of the library with its traditional roles, as described by Sugimoto et al (2012) may continue, considering the Big Data platform proposed by Wu, Wu, Khabsa, Williams, Chen, Huang, Tuarob, Choudhury, Ororbia, Mitra, & Giles (2014). Such platforms will continue to emerge and be improved, with librarians as the ultimate drivers of such platforms and as the mediators between the patrons and the data generated by such platforms.
Every library needs to find its place in the large organization and in society in regard to this very new and very powerful phenomenon called Big Data. Libraries might not have the trained staff to become a leader in the process of organizing and building the complex mechanism of this new knowledge architecture, but librarians must educate and train themselves to be worthy participants in this new establishment.
Method
The study will be cleared by the SCSU IRB.
The survey will collect responses from library population and it readiness to use and use of Big Data. Send survey URL to (academic?) libraries around the world.
Data will be processed through SPSS. Open ended results will be processed manually. The preliminary research design presupposes a mixed method approach.
The study will include the use of closed-ended survey response questions and open-ended questions. The first part of the study (close ended, quantitative questions) will be completed online through online survey. Participants will be asked to complete the survey using a link they receive through e-mail.
Mixed methods research was defined by Johnson and Onwuegbuzie (2004) as “the class of research where the researcher mixes or combines quantitative and qualitative research techniques, methods, approaches, concepts, or language into a single study” (Johnson & Onwuegbuzie, 2004 , p. 17). Quantitative and qualitative methods can be combined, if used to complement each other because the methods can measure different aspects of the research questions (Sale, Lohfeld, & Brazil, 2002).
Sampling design
Online survey of 10-15 question, with 3-5 demographic and the rest regarding the use of tools.
1-2 open-ended questions at the end of the survey to probe for follow-up mixed method approach (an opportunity for qualitative study)
data analysis techniques: survey results will be exported to SPSS and analyzed accordingly. The final survey design will determine the appropriate statistical approach.
Project Schedule
Complete literature review and identify areas of interest – two months
Prepare and test instrument (survey) – month
IRB and other details – month
Generate a list of potential libraries to distribute survey – month
Contact libraries. Follow up and contact again, if necessary (low turnaround) – month
Collect, analyze data – two months
Write out data findings – month
Complete manuscript – month
Proofreading and other details – month
Significance of the work
While it has been widely acknowledged that Big Data (and its handling) is changing higher education (https://blog.stcloudstate.edu/ims?s=big+data) as well as academic libraries (https://blog.stcloudstate.edu/ims/2016/03/29/analytics-in-education/), it remains nebulous how Big Data is handled in the academic library and, respectively, how it is related to the handling of Big Data on campus. Moreover, the visualization of Big Data between units on campus remains in progress, along with any policymaking based on the analysis of such data (hence the need for comprehensive visualization).
This research will aim to gain an understanding on: a. how librarians are handling Big Data; b. how are they relating their Big Data output to the campus output of Big Data and c. how librarians in particular and campus administration in general are tuning their practices based on the analysis.
Based on the survey returns (if there is a statistically significant return), this research might consider juxtaposing the practices from academic libraries, to practices from special libraries (especially corporate libraries), public and school libraries.
References:
Adams Becker, S., Cummins M, Davis, A., Freeman, A., Giesinger Hall, C., Ananthanarayanan, V., … Wolfson, N. (2017). NMC Horizon Report: 2017 Library Edition.
Andrejevic, M., & Gates, K. (2014). Big Data Surveillance: Introduction. Surveillance & Society, 12(2), 185–196.
Asamoah, D. A., Sharda, R., Hassan Zadeh, A., & Kalgotra, P. (2017). Preparing a Data Scientist: A Pedagogic Experience in Designing a Big Data Analytics Course. Decision Sciences Journal of Innovative Education, 15(2), 161–190. https://doi.org/10.1111/dsji.12125
Bughin, J., Chui, M., & Manyika, J. (2010). Clouds, big data, and smart assets: Ten tech-enabled business trends to watch. McKinsey Quarterly, 56(1), 75–86.
Cohen, J., Dolan, B., Dunlap, M., Hellerstein, J. M., & Welton, C. (2009). MAD Skills: New Analysis Practices for Big Data. Proc. VLDB Endow., 2(2), 1481–1492. https://doi.org/10.14778/1687553.1687576
Daniel, B. (2015). Big Data and analytics in higher education: Opportunities and challenges. British Journal of Educational Technology, 46(5), 904–920. https://doi.org/10.1111/bjet.12230
Daries, J. P., Reich, J., Waldo, J., Young, E. M., Whittinghill, J., Ho, A. D., … Chuang, I. (2014). Privacy, Anonymity, and Big Data in the Social Sciences. Commun. ACM, 57(9), 56–63. https://doi.org/10.1145/2643132
De Mauro, A. D., Greco, M., & Grimaldi, M. (2016). A formal definition of Big Data based on its essential features. Library Review, 65(3), 122–135. https://doi.org/10.1108/LR-06-2015-0061
De Mauro, A., Greco, M., & Grimaldi, M. (2015). What is big data? A consensual definition and a review of key research topics. AIP Conference Proceedings, 1644(1), 97–104. https://doi.org/10.1063/1.4907823
Eaton, M. (2017). Seeing Library Data: A Prototype Data Visualization Application for Librarians. Publications and Research. Retrieved from http://academicworks.cuny.edu/kb_pubs/115
Emanuel, J. (2013). Usability testing in libraries: methods, limitations, and implications. OCLC Systems & Services: International Digital Library Perspectives, 29(4), 204–217. https://doi.org/10.1108/OCLC-02-2013-0009
Graham, M., & Shelton, T. (2013). Geography and the future of big data, big data and the future of geography. Dialogues in Human Geography, 3(3), 255–261. https://doi.org/10.1177/2043820613513121
Hashem, I. A. T., Yaqoob, I., Anuar, N. B., Mokhtar, S., Gani, A., & Ullah Khan, S. (2015). The rise of “big data” on cloud computing: Review and open research issues. Information Systems, 47(Supplement C), 98–115. https://doi.org/10.1016/j.is.2014.07.006
Laney, D. (2001, February 6). 3D Data Management: Controlling Data Volume, Velocity, and Variety.
Miltenoff, P., & Hauptman, R. (2005). Ethical dilemmas in libraries: an international perspective. The Electronic Library, 23(6), 664–670. https://doi.org/10.1108/02640470510635746
Philip Chen, C. L., & Zhang, C.-Y. (2014). Data-intensive applications, challenges, techniques and technologies: A survey on Big Data. Information Sciences, 275(Supplement C), 314–347. https://doi.org/10.1016/j.ins.2014.01.015
Provost, F., & Fawcett, T. (2013). Data Science and its Relationship to Big Data and Data-Driven Decision Making. Big Data, 1(1), 51–59. https://doi.org/10.1089/big.2013.1508
Reyes, J. (2015). The skinny on big data in education: Learning analytics simplified. TechTrends: Linking Research & Practice to Improve Learning, 59(2), 75–80. https://doi.org/10.1007/s11528-015-0842-1
Schroeder, R. (2014). Big Data and the brave new world of social media research. Big Data & Society, 1(2), 2053951714563194. https://doi.org/10.1177/2053951714563194
Sugimoto, C. R., Ding, Y., & Thelwall, M. (2012). Library and information science in the big data era: Funding, projects, and future [a panel proposal]. Proceedings of the American Society for Information Science and Technology, 49(1), 1–3. https://doi.org/10.1002/meet.14504901187
Tene, O., & Polonetsky, J. (2012). Big Data for All: Privacy and User Control in the Age of Analytics. Northwestern Journal of Technology and Intellectual Property, 11, [xxvii]-274.
van Dijck, J. (2014). Datafication, dataism and dataveillance: Big Data between scientific paradigm and ideology. Surveillance & Society; Newcastle upon Tyne, 12(2), 197–208.
Waller, M. A., & Fawcett, S. E. (2013). Data Science, Predictive Analytics, and Big Data: A Revolution That Will Transform Supply Chain Design and Management. Journal of Business Logistics, 34(2), 77–84. https://doi.org/10.1111/jbl.12010
West, D. M. (2012). Big data for education: Data mining, data analytics, and web dashboards. Governance Studies at Brookings, 4, 1–0.
Willis, J. (2013). Ethics, Big Data, and Analytics: A Model for Application. Educause Review Online. Retrieved from https://docs.lib.purdue.edu/idcpubs/1
Wixom, B., Ariyachandra, T., Douglas, D. E., Goul, M., Gupta, B., Iyer, L. S., … Turetken, O. (2014). The current state of business intelligence in academia: The arrival of big data. CAIS, 34, 1.
Wu, X., Zhu, X., Wu, G. Q., & Ding, W. (2014). Data mining with big data. IEEE Transactions on Knowledge and Data Engineering, 26(1), 97–107. https://doi.org/10.1109/TKDE.2013.109
Wu, Z., Wu, J., Khabsa, M., Williams, K., Chen, H. H., Huang, W., … Giles, C. L. (2014). Towards building a scholarly big data platform: Challenges, lessons and opportunities. In IEEE/ACM Joint Conference on Digital Libraries (pp. 117–126). https://doi.org/10.1109/JCDL.2014.6970157
Web search engines such as Google, Bing, and Yahoo are integral to making information more discoverable on the open web. How can you expose data about your organization, its services, people, collections, and other information in a way that is meaningful to these search engines?
In this 90 minute session, learn how to leverage Schema.org and semantic markup to achieve enhanced discovery of information on the open web. The session will provide an introduction to both Schema.org and the JSON-LD data format. Topics include an in-depth look at the Schema.org vocabulary, a brief overview of semantic markup with a focus on JSON-LD, and use-cases of these technologies. By the end of the session, you will have an opportunity to apply these technologies through a structured exercise. The session will conclude with resources and guidance for next steps.
Learning Outcomes
Participants will leave this webinar with tools for increasing the discoverability of information on the open web.
This program will include presentation slides, bibliographic references to resources referenced to in the slides, and hands-on exercise material. The exercise material will include instructions, template records for attendees to practice applying Schema.org and JSON-LD, and example records as reference material.
Who Should Attend
Librarians and other professionals interested in increasing discovery of their organization’s information and collections on the open web. General knowledge of metadata concepts and standards is encouraged. Familiarity with the concept of data formats (XML, JSON, MARC, etc.) would be helpful.
Jacob Shelby is the Metadata Technologies Librarian at North Carolina State University (NCSU) Libraries, where he performs metadata activities that support library information services and collections. He has collaborated on endeavors to enhance the discovery of library services and collections on the open web, including exposing NCSU Libraries digital special collections data as Schema.org data. In addition to these endeavors, Jacob has taught workshops at NCSU Libraries on Schema.org and semantic markup.
10. The Virtualized Library: A Librarian’s Introduction to Docker and Virtual Machines
This session will introduce two major types of virtualization, virtual machines using tools like VirtualBox and Vagrant, and containers using Docker. The relative strengths and drawbacks of the two approaches will be discussed along with plenty of hands-on time. Though geared towards integrating these tools into a development workflow, the workshop should be useful for anyone interested in creating stable and reproducible computing environments, and examples will focus on library-specific tools like Archivematica and EZPaarse. With virtualization taking a lot of the pain out of installing and distributing software, alleviating many cross-platform issues, and becoming increasingly common in library and industry practices, now is a great time to get your feet wet.
(One three-hour session)
11. Digital Empathy: Creating Safe Spaces Online
User research is often focused on measures of the usability of online spaces. We look at search traffic, run card sorting and usability testing activities, and track how users navigate our spaces. Those results inform design decisions through the lens of information architecture. This is important, but doesn’t encompass everything a user needs in a space.
This workshop will focus on the other component of user experience design and user research: how to create spaces where users feel safe. Users bring their anxieties and stressors with them to our online spaces, but informed design choices can help to ameliorate that stress. This will ultimately lead to a more positive interaction between your institution and your users.
The presenters will discuss the theory behind empathetic design, delve deeply into using ethnographic research methods – including an opportunity for attendees to practice those ethnographic skills with student participants – and finish with the practical application of these results to ongoing and future projects.
(One three-hour session)
14. ARIA Basics: Making Your Web Content Sing Accessibility
https://dequeuniversity.com/assets/html/jquery-summit/html5/slides/landmarks.html
Are you a web developer or create web content? Do you add dynamic elements to your pages? If so, you should be concerned with making those dynamic elements accessible and usable to as many as possible. One of the most powerful tools currently available for making web pages accessible is ARIA, the Accessible Rich Internet Applications specification. This workshop will teach you the basics for leveraging the full power of ARIA to make great accessible web pages. Through several hands-on exercises, participants will come to understand the purpose and power of ARIA and how to apply it for a variety of different dynamic web elements. Topics will include semantic HTML, ARIA landmarks and roles, expanding/collapsing content, and modal dialog. Participants will also be taught some basic use of the screen reader NVDA for use in accessibility testing. Finally, the lessons will also emphasize learning how to keep on learning as HTML, JavaScript, and ARIA continue to evolve and expand.
Participants will need a basic background in HTML, CSS, and some JavaScript.
(One three-hour session)
18. Learning and Teaching Tech
Tech workshops pose two unique problems: finding skilled instructors for that content, and instructing that content well. Library hosted workshops are often a primary educational resource for solo learners, and many librarians utilize these workshops as a primary outreach platform. Tackling these two issues together often makes the most sense for our limited resources. Whether a programming language or software tool, learning tech to teach tech can be one of the best motivations for learning that tech skill or tool, but equally important is to learn how to teach and present tech well.
This hands-on workshop will guide participants through developing their own learning plan, reviewing essential pedagogy for teaching tech, and crafting a workshop of their choice. Each participant will leave with an actionable learning schedule, a prioritized list of resources to investigate, and an outline of a workshop they would like to teach.
(Two three-hour sessions)
23. Introduction to Omeka S
Omeka S represents a complete rewrite of Omeka Classic (aka the Omeka 2.x series), adhering to our fundamental principles of encouraging use of metadata standards, easy web publishing, and sharing cultural history. New objectives in Omeka S include multisite functionality and increased interaction with other systems. This workshop will compare and contrast Omeka S with Omeka Classic to highlight our emphasis on 1) modern metadata standards, 2) interoperability with other systems including Linked Open Data, 3) use of modern web standards, and 4) web publishing to meet the goals medium- to large-sized institutions.
In this workshop we will walk through Omeka S Item creation, with emphasis on LoD principles. We will also look at the features of Omeka S that ease metadata input and facilitate project-defined usage and workflows. In accordance with our commitment to interoperability, we will describe how the API for Omeka S can be deployed for data exchange and sharing between many systems. We will also describe how Omeka S promotes multiple site creation from one installation, in the interest of easy publishing with many objects in many contexts, and simplifying the work of IT departments.
(One three-hour session)
24. Getting started with static website generators
Have you been curious about static website generators? Have you been wondering who Jekyll and Hugo are? Then this workshop is for you
But this article isn’t about setting up a domain name and hosting for your website. It’s for the step after that, the actual making of that site. The typical choice for a lot of people would be to use something like WordPress. It’s a one-click install on most hosting providers, and there’s a gigantic market of plugins and themes available to choose from, depending on the type of site you’re trying to build. But not only is WordPress a bit overkill for most websites, it also gives you a dynamically generated site with a lot of moving parts. If you don’t keep all of those pieces up to date, they can pose a significant security risk and your site could get hijacked.
The alternative would be to have a static website, with nothing dynamically generated on the server side. Just good old HTML and CSS (and perhaps a bit of Javascript for flair). The downside to that option has been that you’ve been relegated to coding the whole thing by hand yourself. It’s doable, but you just want a place to share your work. You shouldn’t have to know all the idiosyncrasies of low-level web design (and the monumental headache of cross-browser compatibility) to do that.
Static website generators are tools used to build a website made up only of HTML, CSS, and JavaScript. Static websites, unlike dynamic sites built with tools like Drupal or WordPress, do not use databases or server-side scripting languages. Static websites have a number of benefits over dynamic sites, including reduced security vulnerabilities, simpler long-term maintenance, and easier preservation.
In this hands-on workshop, we’ll start by exploring static website generators, their components, some of the different options available, and their benefits and disadvantages. Then, we’ll work on making our own sites, and for those that would like to, get them online with GitHub pages. Familiarity with HTML, git, and command line basics will be helpful but are not required.
(One three-hour session)
26. Using Digital Media for Research and Instruction
To use digital media effectively in both research and instruction, you need to go beyond just the playback of media files. You need to be able to stream the media, divide that stream into different segments, provide descriptive analysis of each segment, order, re-order and compare different segments from the same or different streams and create web sites that can show the result of your analysis. In this workshop, we will use Omeka and several plugins for working with digital media, to show the potential of video streaming, segmentation and descriptive analysis for research and instruction.
(One three-hour session)
28. Spark in the Dark 101 https://zeppelin.apache.org/
This is an introductory session on Apache Spark, a framework for large-scale data processing (https://spark.apache.org/). We will introduce high level concepts around Spark, including how Spark execution works and it’s relationship to the other technologies for working with Big Data. Following this introduction to the theory and background, we will walk workshop participants through hands-on usage of spark-shell, Zeppelin notebooks, and Spark SQL for processing library data. The workshop will wrap up with use cases and demos for leveraging Spark within cultural heritage institutions and information organizations, connecting the building blocks learned to current projects in the real world.
(One three-hour session)
29. Introduction to Spotlight https://github.com/projectblacklight/spotlight http://www.spotlighttechnology.com/4-OpenSource.htm
Spotlight is an open source application that extends the digital library ecosystem by providing a means for institutions to reuse digital content in easy-to-produce, attractive, and scholarly-oriented websites. Librarians, curators, and other content experts can build Spotlight exhibits to showcase digital collections using a self-service workflow for selection, arrangement, curation, and presentation.
This workshop will introduce the main features of Spotlight and present examples of Spotlight-built exhibits from the community of adopters. We’ll also describe the technical requirements for adopting Spotlight and highlight the potential to customize and extend Spotlight’s capabilities for their own needs while contributing to its growth as an open source project.
(One three-hour session)
31. Getting Started Visualizing your IoT Data in Tableau https://www.tableau.com/
The Internet of Things is a rising trend in library research. IoT sensors can be used for space assessment, service design, and environmental monitoring. IoT tools create lots of data that can be overwhelming and hard to interpret. Tableau Public (https://public.tableau.com/en-us/s/) is a data visualization tool that allows you to explore this information quickly and intuitively to find new insights.
This full-day workshop will teach you the basics of building your own own IoT sensor using a Raspberry Pi (https://www.raspberrypi.org/) in order to gather, manipulate, and visualize your data.
All are welcome, but some familiarity with Python is recommended.
(Two three-hour sessions)
32. Enabling Social Media Research and Archiving
Social media data represents a tremendous opportunity for memory institutions of all kinds, be they large academic research libraries, or small community archives. Researchers from a broad swath of disciplines have a great deal of interest in working with social media content, but they often lack access to datasets or the technical skills needed to create them. Further, it is clear that social media is already a crucial part of the historical record in areas ranging from events your local community to national elections. But attempts to build archives of social media data are largely nascent. This workshop will be both an introduction to collecting data from the APIs of social media platforms, as well as a discussion of the roles of libraries and archives in that collecting.
Assuming no prior experience, the workshop will begin with an explanation of how APIs operate. We will then focus specifically on the Twitter API, as Twitter is of significant interest to researchers and hosts an important segment of discourse. Through a combination of hands-on and demos, we will gain experience with a number of tools that support collecting social media data (e.g., Twarc, Social Feed Manager, DocNow, Twurl, and TAGS), as well as tools that enable sharing social media datasets (e.g., Hydrator, TweetSets, and the Tweet ID Catalog).
The workshop will then turn to a discussion of how to build a successful program enabling social media collecting at your institution. This might cover a variety of topics including outreach to campus researchers, collection development strategies, the relationship between social media archiving and web archiving, and how to get involved with the social media archiving community. This discussion will be framed by a focus on ethical considerations of social media data, including privacy and responsible data sharing.
Time permitting, we will provide a sampling of some approaches to social media data analysis, including Twarc Utils and Jupyter Notebooks.
My note: Branding in social media times is a very specific act. Ingenuity is the keyword; even when repeating someone else. Copying someone else is copying someone’s brand and not contributing to your own.
According to the email below, library faculty are asked to provide their feedback regarding the qualifications for a possible faculty line at the library.
In the fall of 2013 during a faculty meeting attended by the back than library dean and during a discussion of an article provided by the dean, it was established that leading academic libraries in this country are seeking to break the mold of “library degree” and seek fresh ideas for the reinvention of the academic library by hiring faculty with more diverse (degree-wise) background.
Is this still the case at the SCSU library? The “democratic” search for the answer of this question does not yield productive results, considering that the majority of the library faculty are “reference” and they “democratically” overturn votes, who see this library to be put on 21st century standards and rather seek more “reference” bodies for duties, which were recognized even by the same reference librarians as obsolete.
It seems that the majority of the SCSU library are “purists” in the sense of seeking professionals with broader background (other than library, even “reference” skills).
In addition, most of the current SCSU librarians are opposed to a second degree, as in acquiring more qualification, versus seeking just another diploma. There is a certain attitude of stagnation / intellectual incest, where new ideas are not generated and old ideas are prepped in “new attire” to look as innovative and/or 21st
Last but not least, a consistent complain about workforce shortages (the attrition politics of the university’s reorganization contribute to the power of such complain) fuels the requests for reference librarians and, instead of looking for new ideas, new approaches and new work responsibilities, the library reorganization conversation deteriorates into squabbles for positions among different department.
Most importantly, the narrow sightedness of being stuck in traditional work description impairs most of the librarians to see potential allies and disruptors. E.g., the insistence on the supremacy of “information literacy” leads SCSU librarians to the erroneous conclusion of the exceptionality of information literacy and the disregard of multi[meta] literacies, thus depriving the entire campus of necessary 21st century skills such as visual literacy, media literacy, technology literacy, etc.
Simultaneously, as mentioned above about potential allies and disruptors, the SCSU librarians insist on their “domain” and if they are not capable of leading meta-literacies instructions, they would also not allow and/or support others to do so.
Considering the observations above, the following qualifications must be considered:
According to the information in this blog post: https://blog.stcloudstate.edu/ims/2016/06/14/technology-requirements-samples/
for the past year and ½, academic libraries are hiring specialists with the following qualifications and for the following positions (bolded and / or in red). Here are some highlights: Positions
digital humanities
Librarian and Instructional Technology Liaison
library Specialist: Data Visualization & Collections Analytics
Qualifications
Advanced degree required, preferably in education, educational technology, instructional design, or MLS with an emphasis in instruction and assessment.
Programming skills – Demonstrated experience with one or more metadata and scripting languages (e.g.Dublin Core, XSLT, Java, JavaScript, Python, or PHP)
Data visualization skills
multi [ meta] literacy skills
Data curation, helping students working with data
Experience with website creation and design in a CMS environment and accessibility and compliance issues
Demonstrated a high degree of facility with technologies and systems germane to the 21st century library, and be well versed in the issues surrounding scholarly communications and compliance issues (e.g. author identifiers, data sharing software, repositories, among others)
Bilingual
Provides and develops awareness and knowledge related to digital scholarship and research lifecycle for librarians and staff.
Experience developing for, and supporting, common open-source library applications such as Omeka, ArchiveSpace, Dspace,
Responsibilities Establishing best practices for digital humanities labs, networks, and services
Assessing, evaluating, and peer reviewing DH projects and librarians
Actively promote TIGER or GRIC related activities through social networks and other platforms as needed.
Coordinates the transmission of online workshops through Google HangoutsScript metadata transformations and digital object processing using BASH, Python, and XSLT
liaison consults with faculty and students in a wide range of disciplines on best practices for teaching and using data/statistical software tools such as R, SPSS, Stata, and MatLab.
In response to the form attached to the Friday, September 29, email regarding St. Cloud State University Library Position Request Form:
Title
Digital Initiatives Librarian
Responsibilities:
TBD, but generally:
– works with faculty across campus on promoting digital projects and other 21st century projects. Works with the English Department faculty on positioning the SCSU library as an equal participants in the digital humanities initiatives on campus
Works with the Visualization lab to establish the library as the leading unit on campus in interpretation of big data
Works with academic technology services on promoting library faculty as the leading force in the pedagogical use of academic technologies.
Quantitative data justification
this is a mute requirement for an innovative and useful library position. It can apply for a traditional request, such as another “reference” librarian. There cannot be a quantitative data justification for an innovative position, as explained to Keith Ewing in 2015. In order to accumulate such data, the position must be functioning at least for six months.
Qualitative justification: Please provide qualitative explanation that supports need for this position.
Numerous 21st century academic tendencies right now are scattered across campus and are a subject of political/power battles rather than a venue for campus collaboration and cooperation. Such position can seek the establishment of the library as the natural hub for “sandbox” activities across campus. It can seek a redirection of using digital initiatives on this campus for political gains by administrators and move the generation and accomplishment of such initiatives to the rightful owner and primary stakeholders: faculty and students.
Currently, there are no additional facilities and resources required. Existing facilities and resources, such as the visualization lab, open source and free application can be used to generate the momentum of faculty working together toward a common goal, such as, e.g. digital humanities.
metadata: counts of papers by yer, researcher, institution, province, region and country. scientific fields subfields
metadata in one-credit course as a topic:
publisher – suppliers =- Elsevier processes – Scopus Data
h-index: The h-index is an author-level metric that attempts to measure both the productivity and citation impact of the publications of a scientist or scholar. The index is based on the set of the scientist’s most cited papers and the number of citations that they have received in other publications.
The era of e-science demands new skill sets and competencies of researchers to ensure their work is accessible, discoverable and reusable. Librarians are naturally positioned to assist in this education as part of their liaison and information literacy services.
Research data literacy and the library
Christian Lauersen, University of Copenhagen; Sarah Wright, Cornell University; Anita de Waard, Elsevier
Data Literacy: access, assess, manipulate, summarize and present data
Statistical Literacy: think critically about basic stats in everyday media
Information Literacy: think critically about concepts; read, interpret, evaluate information
data information literacy: the ability to use, understand and manage data. the skills needed through the whole data life cycle.
Shield, Milo. “Information literacy, statistical literacy and data literacy.” I ASSIST Quarterly 28. 2/3 (2004): 6-11.
Carlson, J., Fosmire, M., Miller, C. C., & Nelson, M. S. (2011). Determining data information literacy needs: A study of students and research faculty. Portal: Libraries & the Academy, 11(2), 629-657.
embedded librarianship,
Courses developed: NTRESS 6600 research data management seminar. six sessions, one-credit mini course
NEW ROLESFOR LIbRARIANS: DATAMANAgEMENTAND CURATION
the capacity to manage and curate research data has not kept pace with the ability to produce them (Hey & Hey, 2006). In recognition of this gap, the NSF and other funding agencies are now mandating that every grant proposal must include a DMP (NSF, 2010). These mandates highlight the benefits of producing well-described data that can be shared, understood, and reused by oth-ers, but they generally offer little in the way of guidance or instruction on how to address the inherent issues and challenges researchers face in complying. Even with increasing expecta-tions from funding agencies and research com-munities, such as the announcement by the White House for all federal funding agencies to better share research data (Holdren, 2013), the lack of data curation services tailored for the “small sciences,” the single investigators or small labs that typically comprise science prac-tice at universities, has been identified as a bar-rier in making research data more widely avail-able (Cragin, Palmer, Carlson, & Witt, 2010).Academic libraries, which support the re-search and teaching activities of their home institutions, are recognizing the need to de-velop services and resources in support of the evolving demands of the information age. The curation of research data is an area that librar-ians are well suited to address, and a num-ber of academic libraries are taking action to build capacity in this area (Soehner, Steeves, & Ward, 2010)
REIMAgININg AN ExISTINg ROLEOF LIbRARIANS: TEAChINg INFORMATION LITERACY SkILLS
By combining the use-based standards of information literacy with skill development across the whole data life cycle, we sought to support the practices of science by develop-ing a DIL curriculum and providing training for higher education students and research-ers. We increased ca-pacity and enabled comparative work by involving several insti-tutions in developing instruction in DIL. Finally, we grounded the instruction in the real-world needs as articu-lated by active researchers and their students from a variety of fields
Chapter 1 The development of the 12 DIL competencies is explained, and a brief compari-son is performed between DIL and information literacy, as defined by the 2000 ACRL standards.
chapter 2 thinking and approaches toward engaging researchers and students with the 12 competencies, a re-view of the literature on a variety of educational approaches to teaching data management and curation to students, and an articulation of our key assumptions in forming the DIL project.
chapter 4 because these lon-gitudinal data cannot be reproduced, acquiring the skills necessary to work with databases and to handle data entry was described as essential. Interventions took place in a classroom set-ting through a spring 2013 semester one-credit course entitled Managing Data to Facilitate Your Research taught by this DIL team.
chapter 5 embedded librar-ian approach of working with the teaching as-sistants (TAs) to develop tools and resources to teach undergraduate students data management skills as a part of their EPICS experience.
Lack of organization and documentation presents a bar-rier to (a) successfully transferring code to new students who will continue its development, (b) delivering code and other project outputs to the community client, and (c) the center ad-ministration’s ability to understand and evalu-ate the impact on student learning.
skill sessions to deliver instruction to team lead-ers, crafted a rubric for measuring the quality of documenting code and other data, served as critics in student design reviews, and attended student lab sessions to observe and consult on student work
chapter 6 Although the faculty researcher had created formal policies on data management practices for his lab, this case study demonstrated that students’ adherence to these guidelines was limited at best. Similar patterns arose in discus-sions concerning the quality of metadata. This case study addressed a situation in which stu-dents are at least somewhat aware of the need to manage their data;
chapter 7 University of Minnesota team to design and implement a hybrid course to teach DIL com-petencies to graduate students in civil engi-neering.
stu-dents’ abilities to understand and track issues affecting the quality of the data, the transfer of data from their custody to the custody of the lab upon graduation, and the steps neces-sary to maintain the value and utility of the data over time.