Vicky Steeves (@VickySteeves) is the first Research Data Management and Reproducibility Librarian
Reproducibility is made so much more challenging because of computers, and the dominance of closed-source operating systems and analysis software researchers use. Ben Marwick wrote a great piece called ‘How computers broke science – and what we can do to fix it’ which details a bit of the problem. Basically, computational environments affect the outcome of analyses (Gronenschild et. al (2012) showed the same data and analyses gave different results between two versions of macOS), and are exceptionally hard to reproduce, especially when the license terms don’t allow it. Additionally, programs encode data incorrectly and studies make erroneous conclusions, e.g. Microsoft Excel encodes genes as dates, which affects 1/5 of published data in leading genome journals.
technology to capture computational environments, workflow, provenance, data, and code are hugely impactful for reproducibility. It’s been the focus of my work, in supporting an open source tool called ReproZip, which packages all computational dependencies, data, and applications in a single distributable package that other can reproduce across different systems. There are other tools that fix parts of this problem: Kepler and VisTrails for workflow/provenance, Packrat for saving specific R packages at the time a script is run so updates to dependencies won’t break, Pex for generating executable Python environments, and o2r for executable papers (including data, text, and code in one).
a plugin for Jupyter notebooks), and added a user interface to make it friendlier to folks not comfortable on the command line.
Ercegovac, Z., & Richardson, J. J. (2004). Academic Dishonesty, Plagiarism Included, in the Digital Age: A Literature Review. College & Research Libraries, 65(4), 301-318.
what constitutes plagiarism, how prevalent plagiarism is in our schools, colleges, and society, what is done to prevent and reduce plagiarism, the attitudes of faculty toward academic dishonesty in general, and individual differences as predictors of academic dishonesty
the interdisciplinary nature of the topic and the ethical challenges of accessing and using information technology, especially in the age of the Internet. Writings have been reported in the literatures of education, psychology, and library and information studies, each looking at academic dishonesty from different perspectives. The literature has been aimed at instructors and scholars in education and developmental psychology, as well as college librarians and school media specialists.
Although the literature appears to be scattered across many fields, standard dictionaries and encyclopedias agree on the meaning of plagiarism.
According to Webster’s, plagiarism is equated with kidnapping and defined as “the unauthorized use of the language and thoughts of another author and the representation of them as one’s own.”(FN10) The Oxford English Dictionary defines plagiarism as the “wrongful appropriation or purloining, and publication as one’s own, of the ideas, or the expression of the ideas (literary, artistic, musical, mechanical, etc.).”(
plagiarism is an elusive concept and has been treated differently in different contexts.
different types of plagiarism: direct plagiarism; truncation (where strings are deleted in the beginning or ending); excision (strings are deleted from the middle of sentences); insertions; inversions; substitutions; change of tense, person, number, or voice; undocumented factual information; inappropriate use of quotation marks; or paraphrasing.
defined plagiarism as a deliberate use of “someone else’s language, ideas, or other original (not common-knowledge) material without acknowledging its source.”(FN30) This definition is extended to printed and digital materials, manuscripts, and other works. Plagiarism is interrelated to intellectual property, copyright, and authorship, and is discussed from the perspective of multiculturalism.(FN31)
Jeffrey Klausman made three distinctions among direct plagiarism, paraphrase plagiarism, and patchwork plagiarism
+++++++++++++++
Cosgrove, J., Norelli, B., & Putnam, E. (2005). Setting the Record Straight: How Online Database Providers Are Handling Plagiarism and Fabrication Issues. College & Research Libraries, 66(2), 136-148.
None of the database providers used links for corrections. Although it is true that the structure of a particular database (LexisNexis, for instance) may make static links more difficult to create than appending corrections, it is a shame that the most elemental characteristic of online resources–the ability to link–is so underutilized within the databases themselves.
Finding reliable materials using online databases is difficult enough for students, especially undergraduates, without having to navigate easily fixed pitfalls. The articles in this study are those most obviously in need of a correction or a link to a correction–articles identified by the publications themselves as being flawed by error, plagiarism, or fabrication. Academic librarians instruct students to carefully evaluate the literature in their campuses’ database resources. Unfortunately, it is not practical to expect undergraduate students to routinely search at the level necessary to uncover corrections and retractions nor do librarians commonly have the time to teach those skills.
Ms. Joanne Lipman
October 20, 2017
Editor-in-Chief of USA Today
7950 Jones Branch Drive
McLean, VA 22108
Dear Ms. Lipman,
In our roles as the Board of Directors of the Association for Library and Information Science Education (ALISE), we are writing to express our profound disappointment with the USA Today career advice feature on October 13, 2017 entitled “Careers: 8 jobs that won’t exist in 2030,” which declared that “librarian” is the number one career among the eight jobs that inaccurate statement on two fronts: first, that the profession is declining, and second, that this alleged will disappear in 2030. This is a false and decline is a result of libraries as warehouses of printed books.
The author of this article may not realize that a professional librarian position in the U.S. and many other countries requires a Master’s degree. According to a recent article in Library Journal, 86% of recent graduates from American Library Association (ALA) accredited schools have found jobs. Another recent report (released on September 28, 2017) by Pearson, Nesta, and Oxford University predicts growth in the information professions, including librarians, curators, and archivists. They are among the top ten jobs likely to experience increased demand in 2030. The report is summarized by Library Journal in its article entitled “The Job Outlook: In 2030, Librarians Will Be in Demand.” Furthermore, your own job posting section for librarian positions does not show the decline of our profession. A close reading of the job titles should have indicated to the author that librarians do more than simply check out books.
This article demonstrates a lack of understanding of librarians’ work as information professionals. My note: but so do lack understanding a lot of librarians, paraprofessionals and administrators in libraries. They are the one, who leave the impressions reflected in the article of US Today. Information professionals IS the keyword and, as during the hype around year 2000 with Barnes & Nobles, a great number of people working in libraries continue to behave as it is the Middle Ages and care of paper-based materials the one and only responsibility a “librarian” may have. The lack of understanding regarding the wide scope of “information professionals” is profound.
Libraries provide access to print and special collections of media, and subscription-based or free electronic resources. All of these must be curated, cataloged, or organized by professional librarians to make them accessible to their users. My note: beating your own drum is good, but when failing to recognize the existence of folksonomy and its impact, do not get upset when US Today reflects the impact
College and university librarians carry out research consultations and instruct student and faculty in finding, evaluating, and using information. My note: when faculty let them do it. And administration recognizes it. It is a shaky position, which does not exclude the 2030 scenario.
Public librarians connect patrons to community resources, lead programming for children and adults, and engage in community outreach and advocacy. Special librarians work for corporations, federal and state institutions, focusing on gathering competitive intelligence and making sure their organizations have access to the information they need to make sound business or strategic decisions.
The article also inaccurately presents libraries as dedicated solely to books:
More and more people are clearing out those paperbacks and downloading e-books on their Tablets and Kindles instead. The same goes for borrowing — as books fall out of favor, libraries are not as popular as they once were. That means you’ll have a tough time finding a job if you decide to become a librarian. Many schools and universities are already moving their libraries off the shelves and onto the Internet.
In addition to providing access to books, journals, newspapers, and other media, both electronically and in print, libraries provide access to technology, from computers, laptops, and iPads to 3D printers, My note: are we? are we doing this at our library? Are the reference librarians allowing such blasphemous thoughts penetrate this library? And if they do, do they allow other professionals to collaborate with them, or “keep it for themselves?”
multimedia software, and recording studios. My note: whaaat?
Many libraries have expanded their non-print collections and are circulating a wide variety of objects including tools, musical instruments, toys, wifi hotspots, and artwork. Libraries are highly valued as community centers and safe spaces that allow people to connect with information and with each other. Research shows that libraries are one of the most trusted and valued public institutions in the country.
The article further argues that librarians and libraries are not needed because printed books are falling out of favor. However, there is considerable counter-evidence that printed books are still in demand, including the articles cited below.
Cain, S. (2017, March 14). Ebook sales continue to fall as younger generations drive appetite for print. The Guardian. Retrieved from:
Milliot, J. (2017, January 20). The Bad News About E-books: Nielsen reports units fell 16% in 2016 compared to 2015. Publishers Weekly. Retrieved from:
We respectfully request an open response from you or from the author of the article. Sincerely,
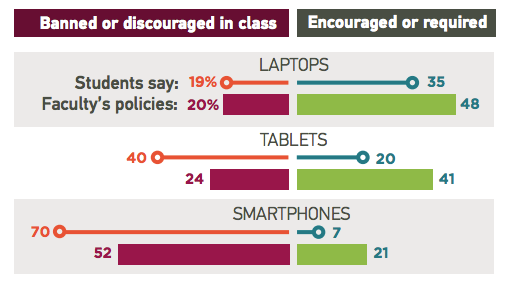
Students match their preference for hybrid learning with a belief that it is the most effective learning environment for them.
Despite the fact that faculty prefer teaching in a hybrid environment, they remain skeptical of online learning. Nearly half do not agree online 45% learning is effective.
Students asked what technologies they wish their instructors used more, and we asked faculty what technologies they think could make them more effective instructors. Both agree that content and resource-focused technologies should be incorporated more and social media and tablets should be incorporated less.
Web search engines such as Google, Bing, and Yahoo are integral to making information more discoverable on the open web. How can you expose data about your organization, its services, people, collections, and other information in a way that is meaningful to these search engines?
In this 90 minute session, learn how to leverage Schema.org and semantic markup to achieve enhanced discovery of information on the open web. The session will provide an introduction to both Schema.org and the JSON-LD data format. Topics include an in-depth look at the Schema.org vocabulary, a brief overview of semantic markup with a focus on JSON-LD, and use-cases of these technologies. By the end of the session, you will have an opportunity to apply these technologies through a structured exercise. The session will conclude with resources and guidance for next steps.
Learning Outcomes
Participants will leave this webinar with tools for increasing the discoverability of information on the open web.
This program will include presentation slides, bibliographic references to resources referenced to in the slides, and hands-on exercise material. The exercise material will include instructions, template records for attendees to practice applying Schema.org and JSON-LD, and example records as reference material.
Who Should Attend
Librarians and other professionals interested in increasing discovery of their organization’s information and collections on the open web. General knowledge of metadata concepts and standards is encouraged. Familiarity with the concept of data formats (XML, JSON, MARC, etc.) would be helpful.
Jacob Shelby is the Metadata Technologies Librarian at North Carolina State University (NCSU) Libraries, where he performs metadata activities that support library information services and collections. He has collaborated on endeavors to enhance the discovery of library services and collections on the open web, including exposing NCSU Libraries digital special collections data as Schema.org data. In addition to these endeavors, Jacob has taught workshops at NCSU Libraries on Schema.org and semantic markup.
10. The Virtualized Library: A Librarian’s Introduction to Docker and Virtual Machines
This session will introduce two major types of virtualization, virtual machines using tools like VirtualBox and Vagrant, and containers using Docker. The relative strengths and drawbacks of the two approaches will be discussed along with plenty of hands-on time. Though geared towards integrating these tools into a development workflow, the workshop should be useful for anyone interested in creating stable and reproducible computing environments, and examples will focus on library-specific tools like Archivematica and EZPaarse. With virtualization taking a lot of the pain out of installing and distributing software, alleviating many cross-platform issues, and becoming increasingly common in library and industry practices, now is a great time to get your feet wet.
(One three-hour session)
11. Digital Empathy: Creating Safe Spaces Online
User research is often focused on measures of the usability of online spaces. We look at search traffic, run card sorting and usability testing activities, and track how users navigate our spaces. Those results inform design decisions through the lens of information architecture. This is important, but doesn’t encompass everything a user needs in a space.
This workshop will focus on the other component of user experience design and user research: how to create spaces where users feel safe. Users bring their anxieties and stressors with them to our online spaces, but informed design choices can help to ameliorate that stress. This will ultimately lead to a more positive interaction between your institution and your users.
The presenters will discuss the theory behind empathetic design, delve deeply into using ethnographic research methods – including an opportunity for attendees to practice those ethnographic skills with student participants – and finish with the practical application of these results to ongoing and future projects.
(One three-hour session)
14. ARIA Basics: Making Your Web Content Sing Accessibility
https://dequeuniversity.com/assets/html/jquery-summit/html5/slides/landmarks.html
Are you a web developer or create web content? Do you add dynamic elements to your pages? If so, you should be concerned with making those dynamic elements accessible and usable to as many as possible. One of the most powerful tools currently available for making web pages accessible is ARIA, the Accessible Rich Internet Applications specification. This workshop will teach you the basics for leveraging the full power of ARIA to make great accessible web pages. Through several hands-on exercises, participants will come to understand the purpose and power of ARIA and how to apply it for a variety of different dynamic web elements. Topics will include semantic HTML, ARIA landmarks and roles, expanding/collapsing content, and modal dialog. Participants will also be taught some basic use of the screen reader NVDA for use in accessibility testing. Finally, the lessons will also emphasize learning how to keep on learning as HTML, JavaScript, and ARIA continue to evolve and expand.
Participants will need a basic background in HTML, CSS, and some JavaScript.
(One three-hour session)
18. Learning and Teaching Tech
Tech workshops pose two unique problems: finding skilled instructors for that content, and instructing that content well. Library hosted workshops are often a primary educational resource for solo learners, and many librarians utilize these workshops as a primary outreach platform. Tackling these two issues together often makes the most sense for our limited resources. Whether a programming language or software tool, learning tech to teach tech can be one of the best motivations for learning that tech skill or tool, but equally important is to learn how to teach and present tech well.
This hands-on workshop will guide participants through developing their own learning plan, reviewing essential pedagogy for teaching tech, and crafting a workshop of their choice. Each participant will leave with an actionable learning schedule, a prioritized list of resources to investigate, and an outline of a workshop they would like to teach.
(Two three-hour sessions)
23. Introduction to Omeka S
Omeka S represents a complete rewrite of Omeka Classic (aka the Omeka 2.x series), adhering to our fundamental principles of encouraging use of metadata standards, easy web publishing, and sharing cultural history. New objectives in Omeka S include multisite functionality and increased interaction with other systems. This workshop will compare and contrast Omeka S with Omeka Classic to highlight our emphasis on 1) modern metadata standards, 2) interoperability with other systems including Linked Open Data, 3) use of modern web standards, and 4) web publishing to meet the goals medium- to large-sized institutions.
In this workshop we will walk through Omeka S Item creation, with emphasis on LoD principles. We will also look at the features of Omeka S that ease metadata input and facilitate project-defined usage and workflows. In accordance with our commitment to interoperability, we will describe how the API for Omeka S can be deployed for data exchange and sharing between many systems. We will also describe how Omeka S promotes multiple site creation from one installation, in the interest of easy publishing with many objects in many contexts, and simplifying the work of IT departments.
(One three-hour session)
24. Getting started with static website generators
Have you been curious about static website generators? Have you been wondering who Jekyll and Hugo are? Then this workshop is for you
But this article isn’t about setting up a domain name and hosting for your website. It’s for the step after that, the actual making of that site. The typical choice for a lot of people would be to use something like WordPress. It’s a one-click install on most hosting providers, and there’s a gigantic market of plugins and themes available to choose from, depending on the type of site you’re trying to build. But not only is WordPress a bit overkill for most websites, it also gives you a dynamically generated site with a lot of moving parts. If you don’t keep all of those pieces up to date, they can pose a significant security risk and your site could get hijacked.
The alternative would be to have a static website, with nothing dynamically generated on the server side. Just good old HTML and CSS (and perhaps a bit of Javascript for flair). The downside to that option has been that you’ve been relegated to coding the whole thing by hand yourself. It’s doable, but you just want a place to share your work. You shouldn’t have to know all the idiosyncrasies of low-level web design (and the monumental headache of cross-browser compatibility) to do that.
Static website generators are tools used to build a website made up only of HTML, CSS, and JavaScript. Static websites, unlike dynamic sites built with tools like Drupal or WordPress, do not use databases or server-side scripting languages. Static websites have a number of benefits over dynamic sites, including reduced security vulnerabilities, simpler long-term maintenance, and easier preservation.
In this hands-on workshop, we’ll start by exploring static website generators, their components, some of the different options available, and their benefits and disadvantages. Then, we’ll work on making our own sites, and for those that would like to, get them online with GitHub pages. Familiarity with HTML, git, and command line basics will be helpful but are not required.
(One three-hour session)
26. Using Digital Media for Research and Instruction
To use digital media effectively in both research and instruction, you need to go beyond just the playback of media files. You need to be able to stream the media, divide that stream into different segments, provide descriptive analysis of each segment, order, re-order and compare different segments from the same or different streams and create web sites that can show the result of your analysis. In this workshop, we will use Omeka and several plugins for working with digital media, to show the potential of video streaming, segmentation and descriptive analysis for research and instruction.
(One three-hour session)
28. Spark in the Dark 101 https://zeppelin.apache.org/
This is an introductory session on Apache Spark, a framework for large-scale data processing (https://spark.apache.org/). We will introduce high level concepts around Spark, including how Spark execution works and it’s relationship to the other technologies for working with Big Data. Following this introduction to the theory and background, we will walk workshop participants through hands-on usage of spark-shell, Zeppelin notebooks, and Spark SQL for processing library data. The workshop will wrap up with use cases and demos for leveraging Spark within cultural heritage institutions and information organizations, connecting the building blocks learned to current projects in the real world.
(One three-hour session)
29. Introduction to Spotlight https://github.com/projectblacklight/spotlight http://www.spotlighttechnology.com/4-OpenSource.htm
Spotlight is an open source application that extends the digital library ecosystem by providing a means for institutions to reuse digital content in easy-to-produce, attractive, and scholarly-oriented websites. Librarians, curators, and other content experts can build Spotlight exhibits to showcase digital collections using a self-service workflow for selection, arrangement, curation, and presentation.
This workshop will introduce the main features of Spotlight and present examples of Spotlight-built exhibits from the community of adopters. We’ll also describe the technical requirements for adopting Spotlight and highlight the potential to customize and extend Spotlight’s capabilities for their own needs while contributing to its growth as an open source project.
(One three-hour session)
31. Getting Started Visualizing your IoT Data in Tableau https://www.tableau.com/
The Internet of Things is a rising trend in library research. IoT sensors can be used for space assessment, service design, and environmental monitoring. IoT tools create lots of data that can be overwhelming and hard to interpret. Tableau Public (https://public.tableau.com/en-us/s/) is a data visualization tool that allows you to explore this information quickly and intuitively to find new insights.
This full-day workshop will teach you the basics of building your own own IoT sensor using a Raspberry Pi (https://www.raspberrypi.org/) in order to gather, manipulate, and visualize your data.
All are welcome, but some familiarity with Python is recommended.
(Two three-hour sessions)
32. Enabling Social Media Research and Archiving
Social media data represents a tremendous opportunity for memory institutions of all kinds, be they large academic research libraries, or small community archives. Researchers from a broad swath of disciplines have a great deal of interest in working with social media content, but they often lack access to datasets or the technical skills needed to create them. Further, it is clear that social media is already a crucial part of the historical record in areas ranging from events your local community to national elections. But attempts to build archives of social media data are largely nascent. This workshop will be both an introduction to collecting data from the APIs of social media platforms, as well as a discussion of the roles of libraries and archives in that collecting.
Assuming no prior experience, the workshop will begin with an explanation of how APIs operate. We will then focus specifically on the Twitter API, as Twitter is of significant interest to researchers and hosts an important segment of discourse. Through a combination of hands-on and demos, we will gain experience with a number of tools that support collecting social media data (e.g., Twarc, Social Feed Manager, DocNow, Twurl, and TAGS), as well as tools that enable sharing social media datasets (e.g., Hydrator, TweetSets, and the Tweet ID Catalog).
The workshop will then turn to a discussion of how to build a successful program enabling social media collecting at your institution. This might cover a variety of topics including outreach to campus researchers, collection development strategies, the relationship between social media archiving and web archiving, and how to get involved with the social media archiving community. This discussion will be framed by a focus on ethical considerations of social media data, including privacy and responsible data sharing.
Time permitting, we will provide a sampling of some approaches to social media data analysis, including Twarc Utils and Jupyter Notebooks.
Mobile computing, cloud computing, and data-rich repositories have altered ideas about where and how learning takes place.
designers can find themselves filling a variety of roles. They might design large, complex systems or work with faculty and departments to develop courses and curricula. They might migrate traditional resources to mobile or adaptive platforms. They might help administrators understand the value and potential of new learning strategies and tools. Today’s instructional designer might work with subject-matter experts, coders, graphic designers, and others. Moreover, the work of an instructional designer increasingly continues throughout the duration of a course rather than taking place upfront
Given the expanding role and landscape of technology—as well as the growing body of knowledge about learning and about educational activities and assessments—dedicated instructional designers are increasingly common and often take a stronger role.
Competency based learning allows students to progress at their own pace and finish assignments, courses, and degree plans as time and skills permit. Data provided by analytics systems can help instructional designers predict which pedagogical approaches might be most effective and tailor learning experiences accordingly. The use of mobile learning continues to grow, enabling new kinds of learning experiences.
In some contexts, instructional designers might work more directly with students, teaching them lifelong learning skills. Students might begin coursework by choosing from a menu of options, creating their own path through content, making choices about learning options, being more hands-on, and selecting best approaches for demonstrating mastery. Educational models that feature adaptive and personalized learning will increasingly be a focus of instructional design.
Instructional designers bring a cross-disciplinary approach to their work, showing faculty how learning activities used in particular subject areas might be effective in others. In this way, instructional designers can cultivate a measure of consistency across courses and disciplines in how educational strategies and techniques are incorporated.
Augmented reality can be described as experiencing the real world with an overlay of additional computer generated content. In contrast, virtual reality immerses a user in an entirely simulated environment, while mixed or merged reality blends real and virtual worlds in ways through which the physical and the digital can interact. AR, VR, and MR offer new opportunities to create a psychological sense of immersive presence in an environment that feels real enough to be viewed, experienced, explored, and manipulated. These technologies have the potential to democratize learning by giving everyone access to immersive experiences that were once restricted to relatively few learners.
In Grinnell College’s Immersive Experiences Lab http://gciel.sites.grinnell.edu/, teams of faculty, staff, and students collaborate on research projects, then use 3D, VR, and MR technologies as a platform to synthesize and present their findings.
In terms of equity, AR, VR, and MR have the potential to democratize learning by giving all learners access to immersive experiences
downsides :
relatively little research about the most effective ways to use these technologies as instructional tools. Combined, these factors can be disincentives for institutions to invest in the equipment, facilities, and staffing that can be required to support these systems. AR, VR, and MR technologies raise concerns about personal privacy and data security. Further, at least some of these tools and applications currently fail to meet accessibility standards. The user experience in some AR, VR, and MR applications can be intensely emotional and even disturbing (my note: but can be also used for empathy literacy),
immersing users in recreated, remote, or even hypothetical environments as small as a molecule or as large as a universe, allowing learners to experience “reality” from multiple perspectives.
Discuss ways to incorporate library services through the learning management system level.
Examine bibliographic instruction in the virtual classroom through team teaching, guest lecturing.
Identify librarian roles during the design and development of online courses.
Assessing embedded librarianship efforts.
Mimi O’Malley is the learning technology translation strategist at Spalding University. She helps faculty prepare course content for hybrid and fully online courses in addition to incorporating open education resources into courses. She previously wrote and facilitated professional development courses and workshops at the Learning House, Inc. Mimi has presented workshops on online learning topics including assessment, plagiarism, copyright, and curriculum trends at the Learning House, Inc. CONNECT Users Conference, SLOAN-C ALN, Pencils and Pixels and New Horizons Teaching & Learning Conference. Interview with Mimi O’Malley
metadata: counts of papers by yer, researcher, institution, province, region and country. scientific fields subfields
metadata in one-credit course as a topic:
publisher – suppliers =- Elsevier processes – Scopus Data
h-index: The h-index is an author-level metric that attempts to measure both the productivity and citation impact of the publications of a scientist or scholar. The index is based on the set of the scientist’s most cited papers and the number of citations that they have received in other publications.
The era of e-science demands new skill sets and competencies of researchers to ensure their work is accessible, discoverable and reusable. Librarians are naturally positioned to assist in this education as part of their liaison and information literacy services.
Research data literacy and the library
Christian Lauersen, University of Copenhagen; Sarah Wright, Cornell University; Anita de Waard, Elsevier
Data Literacy: access, assess, manipulate, summarize and present data
Statistical Literacy: think critically about basic stats in everyday media
Information Literacy: think critically about concepts; read, interpret, evaluate information
data information literacy: the ability to use, understand and manage data. the skills needed through the whole data life cycle.
Shield, Milo. “Information literacy, statistical literacy and data literacy.” I ASSIST Quarterly 28. 2/3 (2004): 6-11.
Carlson, J., Fosmire, M., Miller, C. C., & Nelson, M. S. (2011). Determining data information literacy needs: A study of students and research faculty. Portal: Libraries & the Academy, 11(2), 629-657.
embedded librarianship,
Courses developed: NTRESS 6600 research data management seminar. six sessions, one-credit mini course
NEW ROLESFOR LIbRARIANS: DATAMANAgEMENTAND CURATION
the capacity to manage and curate research data has not kept pace with the ability to produce them (Hey & Hey, 2006). In recognition of this gap, the NSF and other funding agencies are now mandating that every grant proposal must include a DMP (NSF, 2010). These mandates highlight the benefits of producing well-described data that can be shared, understood, and reused by oth-ers, but they generally offer little in the way of guidance or instruction on how to address the inherent issues and challenges researchers face in complying. Even with increasing expecta-tions from funding agencies and research com-munities, such as the announcement by the White House for all federal funding agencies to better share research data (Holdren, 2013), the lack of data curation services tailored for the “small sciences,” the single investigators or small labs that typically comprise science prac-tice at universities, has been identified as a bar-rier in making research data more widely avail-able (Cragin, Palmer, Carlson, & Witt, 2010).Academic libraries, which support the re-search and teaching activities of their home institutions, are recognizing the need to de-velop services and resources in support of the evolving demands of the information age. The curation of research data is an area that librar-ians are well suited to address, and a num-ber of academic libraries are taking action to build capacity in this area (Soehner, Steeves, & Ward, 2010)
REIMAgININg AN ExISTINg ROLEOF LIbRARIANS: TEAChINg INFORMATION LITERACY SkILLS
By combining the use-based standards of information literacy with skill development across the whole data life cycle, we sought to support the practices of science by develop-ing a DIL curriculum and providing training for higher education students and research-ers. We increased ca-pacity and enabled comparative work by involving several insti-tutions in developing instruction in DIL. Finally, we grounded the instruction in the real-world needs as articu-lated by active researchers and their students from a variety of fields
Chapter 1 The development of the 12 DIL competencies is explained, and a brief compari-son is performed between DIL and information literacy, as defined by the 2000 ACRL standards.
chapter 2 thinking and approaches toward engaging researchers and students with the 12 competencies, a re-view of the literature on a variety of educational approaches to teaching data management and curation to students, and an articulation of our key assumptions in forming the DIL project.
chapter 4 because these lon-gitudinal data cannot be reproduced, acquiring the skills necessary to work with databases and to handle data entry was described as essential. Interventions took place in a classroom set-ting through a spring 2013 semester one-credit course entitled Managing Data to Facilitate Your Research taught by this DIL team.
chapter 5 embedded librar-ian approach of working with the teaching as-sistants (TAs) to develop tools and resources to teach undergraduate students data management skills as a part of their EPICS experience.
Lack of organization and documentation presents a bar-rier to (a) successfully transferring code to new students who will continue its development, (b) delivering code and other project outputs to the community client, and (c) the center ad-ministration’s ability to understand and evalu-ate the impact on student learning.
skill sessions to deliver instruction to team lead-ers, crafted a rubric for measuring the quality of documenting code and other data, served as critics in student design reviews, and attended student lab sessions to observe and consult on student work
chapter 6 Although the faculty researcher had created formal policies on data management practices for his lab, this case study demonstrated that students’ adherence to these guidelines was limited at best. Similar patterns arose in discus-sions concerning the quality of metadata. This case study addressed a situation in which stu-dents are at least somewhat aware of the need to manage their data;
chapter 7 University of Minnesota team to design and implement a hybrid course to teach DIL com-petencies to graduate students in civil engi-neering.
stu-dents’ abilities to understand and track issues affecting the quality of the data, the transfer of data from their custody to the custody of the lab upon graduation, and the steps neces-sary to maintain the value and utility of the data over time.