Media literacy. Differentiated instruction. Media literacy guide.
Fake news as part of media literacy. Visual literacy as part of media literacy. Media literacy as part of digital citizenship.
Web design / web development
the roles of HTML5, CSS, Java Script, PHP, Bootstrap, JQuery, React and other scripting languages and libraries. Heat maps and other usability issues; website content strategy. THE MODEL-VIEW-CONTROLLER (MVC) design pattern
Social media for institutional use. Digital Curation. Social Media algorithms. Etiquette Ethics. Mastodon
I hosted a LITA webinar in the fall of 2016 (four weeks); I can accommodate any information from that webinar for the use of the IM students
OER and instructional designer’s assistance to book creators.
I can cover both the “library part” (“free” OER, copyright issues etc) and the support / creative part of an OER book / textbook
“Big Data.” Data visualization. Large scale visualization. Text encoding. Analytics, Data mining. Unizin. Python, R in academia.
I can introduce the students to the large idea of Big Data and its importance in lieu of the upcoming IoT, but also departmentalize its importance for academia, business, etc. From infographics to heavy duty visualization (Primo X-Services API. JSON, Flask).
NetNeutrality, Digital Darwinism, Internet economy and the role of your professional in such environment
I can introduce students to the issues, if not familiar and / or lead a discussion on a rather controversial topic
Digital assessment. Digital Assessment literacy.
I can introduce students to tools, how to evaluate and select tools and their pedagogical implications
Wikipedia
a hands-on exercise on working with Wikipedia. After the session, students will be able to create Wikipedia entries thus knowing intimately the process of Wikipedia and its information.
Effective presentations. Tools, methods, concepts and theories (cognitive load). Presentations in the era of VR, AR and mixed reality. Unity.
I can facilitate a discussion among experts (your students) on selection of tools and their didactically sound use to convey information. I can supplement the discussion with my own findings and conclusions.
eConferencing. Tools and methods
I can facilitate a discussion among your students on selection of tools and comparison. Discussion about the their future and their place in an increasing online learning environment
Digital Storytelling. Immersive Storytelling. The Moth. Twine. Transmedia Storytelling
I am teaching a LIB 490/590 Digital Storytelling class. I can adapt any information from that class to the use of IM students
VR, AR, Mixed Reality.
besides Mark Gill, I can facilitate a discussion, which goes beyond hardware and brands, but expand on the implications for academia and corporate education / world
Instructional design. ID2ID
I can facilitate a discussion based on the Educause suggestions about the profession’s development
Microcredentialing in academia and corporate world. Blockchain
IT in K12. How to evaluate; prioritize; select. obsolete trends in 21 century schools. K12 mobile learning
Podcasting: past, present, future. Beautiful Audio Editor.
a definition of podcasting and delineation of similar activities; advantages and disadvantages.
Gender, race and age in education. Digital divide. Xennials, Millennials and Gen Z. generational approach to teaching and learning. Young vs old Millennials. Millennial employees.
Please have also materials, which might help you organize our thoughts and expedite your Chapter 2 writing….
Do you agree with (did you use) the following observations:
The purpose of the review of the literature is to prove that no one has studied the gap in the knowledge outlined in Chapter 1. The subjects in the Review of Literature should have been introduced in the Background of the Problem in Chapter 1. Chapter 2 is not a textbook of subject matter loosely related to the subject of the study. Every research study that is mentioned should in some way bear upon the gap in the knowledge, and each study that is mentioned should end with the comment that the study did not collect data about the specific gap in the knowledge of the study as outlined in Chapter 1.
The review should be laid out in major sections introduced by organizational generalizations. An organizational generalization can be a subheading so long as the last sentence of the previous section introduces the reader to what the next section will contain. The purpose of this chapter is to cite major conclusions, findings, and methodological issues related to the gap in the knowledge from Chapter 1. It is written for knowledgeable peers from easily retrievable sources of the most recent issue possible.
Empirical literature published within the previous 5 years or less is reviewed to prove no mention of the specific gap in the knowledge that is the subject of the dissertation is in the body of knowledge. Common sense should prevail. Often, to provide a history of the research, it is necessary to cite studies older than 5 years. The object is to acquaint the reader with existing studies relative to the gap in the knowledge and describe who has done the work, when and where the research was completed, and what approaches were used for the methodology, instrumentation, statistical analyses, or all of these subjects.
If very little literature exists, the wise student will write, in effect, a several-paragraph book report by citing the purpose of the study, the methodology, the findings, and the conclusions. If there is an abundance of studies, cite only the most recent studies. Firmly establish the need for the study. Defend the methods and procedures by pointing out other relevant studies that implemented similar methodologies. It should be frequently pointed out to the reader why a particular study did not match the exact purpose of the dissertation.
The Review of Literature ends with a Conclusion that clearly states that, based on the review of the literature, the gap in the knowledge that is the subject of the study has not been studied. Remember that a “summary” is different from a “conclusion.” A Summary, the final main section, introduces the next chapter.
When conducting qualitative data, how many people should be interviewed? Is there a minimum or a max
Here is my take on it:
Simple question, not so simple answer.
It depends.
Generally, the number of respondents depends on the type of qualitative inquiry: case study methodology, phenomenological study, ethnographic study, or ethnomethodology. However, a rule of thumb is for scholars to achieve saturation point–that is the point in which no fresh information is uncovered in response to an issue that is of interest to the researcher.
If your qualitative method is designed to meet rigor and trustworthiness, thick, rich data is important. To achieve these principles you would need at least 12 interviews, ensuring your participants are the holders of knowledge in the area you intend to investigate. In grounded theory you could start with 12 and interview more if your data is not rich enough.
In IPA the norm tends to be 6 interviews.
You may check the sample size in peer reviewed qualitative publications in your field to find out about popular practice. In all depends on the research problem, choice of specific qualitative approach and theoretical framework, so the answer to your question will vary from few to few dozens.
How many interviews are needed in a qualitative research?
There are different views in literature and no one agreed to the exact number. Here I reviewed some mostly cited references. Based Creswell (2014), it is estimated that 16 participants will provide rich and detailed data. There are a couple of researchers agreed on 10–15 in-depth interviews are sufficient (Guest, Bunce & Johnson 2006; Baker & Edwards 2012).
your methodological choices need to reflect your ontological position and understanding of knowledge production, and that’s also where you can argue a strong case for smaller qualitative studies, as you say. This is not only a problem for certain subjects, I think it’s a problem in certain departments or journals across the board of social science research, as it’s a question of academic culture.
here more serious literature and research (in case you need to cite in Chapter 3)
Sample Size and Saturation in PhD Studies Using Qualitative Interviews
Gaskell, George (2000). Individual and Group Interviewing. In Martin W. Bauer & George Gaskell (Eds.), Qualitative Researching With Text, Image and Sound. A Practical Handbook (pp. 38-56). London: SAGE Publications.
Savolainen, Jukka 1994: “The Rationality of Drawing Big Conclusions Based on Small Samples.” Social Forces 72:1217-24. (http://www.jstor.org/pss/2580299).
Small, M.(2009) ‘How many cases do I need ? On science and the logic of case selection in field-based research’ Ethnography 10(1) 5-38
Williams,M. (2000) ‘Interpretivism and generalisation ‘ Sociology 34(2) 209-224
where you have several documents from the Graduate school and myself to start building your understanding and vocabulary regarding your quantitative, qualitative or mixed method research.
It has been agreed that before you go to the Statistical Center (Randy Kolb), it is wise to be prepared and understand the terminology as well as the basics of the research methods.
Please have an additional list of materials available through the SCSU library and the Internet. They can help you further with building a robust foundation to lead your research:
Books on intro to stat modeling available at the library. I understand the major pain borrowing books from the SCSU library can constitute, but you can use the titles and the authors and see if you can borrow them from your local public library
I also sought and shared with you “visual” explanations of the basics terms and concepts. Once you start looking at those, you should be able to further research (e.g. YouTube) and find suitable sources for your learning style.
I (and the future cohorts) will deeply appreciate if you remember to share those “suitable sources for your learning style” either by sharing in this Google Group thread and/or sharing in the comments section of the blog entry: https://blog.stcloudstate.edu/ims/2017/07/10/intro-to-stat-modeling. Your Facebook group page is also a good place to discuss among ourselves best practices to learn and use research methods for your chapter 3.
Watching the video, you may remember the same #BooleanSearch techniques from our BI (bibliography instruction) session of last semester.
Considering the fact of preponderance of information in 2017: your Chapter 2 is NOT ONLY about finding information regrading your topic.
Your Chapter 2 is about proving your extensive research of the existing literature.
The techniques presented in the short video will arm you with methods to dig deeper and look further.
If you would like to do a decent job exploring all corners of the vast area called Internet, please consider other search engines similar to Google Scholar:
Applications for the 2018 Institute will be accepted between December 1, 2017 and January 27, 2018. Scholars accepted to the program will be notified in early March 2018.
Title:
Learning to Harness Big Data in an Academic Library
Abstract (200)
Research on Big Data per se, as well as on the importance and organization of the process of Big Data collection and analysis, is well underway. The complexity of the process comprising “Big Data,” however, deprives organizations of ubiquitous “blue print.” The planning, structuring, administration and execution of the process of adopting Big Data in an organization, being that a corporate one or an educational one, remains an elusive one. No less elusive is the adoption of the Big Data practices among libraries themselves. Seeking the commonalities and differences in the adoption of Big Data practices among libraries may be a suitable start to help libraries transition to the adoption of Big Data and restructuring organizational and daily activities based on Big Data decisions. Introduction to the problem. Limitations
The redefinition of humanities scholarship has received major attention in higher education. The advent of digital humanities challenges aspects of academic librarianship. Data literacy is a critical need for digital humanities in academia. The March 2016 Library Juice Academy Webinar led by John Russel exemplifies the efforts to help librarians become versed in obtaining programming skills, and respectively, handling data. Those are first steps on a rather long path of building a robust infrastructure to collect, analyze, and interpret data intelligently, so it can be utilized to restructure daily and strategic activities. Since the phenomenon of Big Data is young, there is a lack of blueprints on the organization of such infrastructure. A collection and sharing of best practices is an efficient approach to establishing a feasible plan for setting a library infrastructure for collection, analysis, and implementation of Big Data.
Limitations. This research can only organize the results from the responses of librarians and research into how libraries present themselves to the world in this arena. It may be able to make some rudimentary recommendations. However, based on each library’s specific goals and tasks, further research and work will be needed.
Big Data is becoming an omnipresent term. It is widespread among different disciplines in academia (De Mauro, Greco, & Grimaldi, 2016). This leads to “inconsistency in meanings and necessity for formal definitions” (De Mauro et al, 2016, p. 122). Similarly, to De Mauro et al (2016), Hashem, Yaqoob, Anuar, Mokhtar, Gani and Ullah Khan (2015) seek standardization of definitions. The main connected “themes” of this phenomenon must be identified and the connections to Library Science must be sought. A prerequisite for a comprehensive definition is the identification of Big Data methods. Bughin, Chui, Manyika (2011), Chen et al. (2012) and De Mauro et al (2015) single out the methods to complete the process of building a comprehensive definition.
In conjunction with identifying the methods, volume, velocity, and variety, as defined by Laney (2001), are the three properties of Big Data accepted across the literature. Daniel (2015) defines three stages in big data: collection, analysis, and visualization. According to Daniel, (2015), Big Data in higher education “connotes the interpretation of a wide range of administrative and operational data” (p. 910) and according to Hilbert (2013), as cited in Daniel (2015), Big Data “delivers a cost-effective prospect to improve decision making” (p. 911).
The importance of understanding the process of Big Data analytics is well understood in academic libraries. An example of such “administrative and operational” use for cost-effective improvement of decision making are the Finch & Flenner (2016) and Eaton (2017) case studies of the use of data visualization to assess an academic library collection and restructure the acquisition process. Sugimoto, Ding & Thelwall (2012) call for the discussion of Big Data for libraries. According to the 2017 NMC Horizon Report “Big Data has become a major focus of academic and research libraries due to the rapid evolution of data mining technologies and the proliferation of data sources like mobile devices and social media” (Adams, Becker, et al., 2017, p. 38).
Power (2014) elaborates on the complexity of Big Data in regard to decision-making and offers ideas for organizations on building a system to deal with Big Data. As explained by Boyd and Crawford (2012) and cited in De Mauro et al (2016), there is a danger of a new digital divide among organizations with different access and ability to process data. Moreover, Big Data impacts current organizational entities in their ability to reconsider their structure and organization. The complexity of institutions’ performance under the impact of Big Data is further complicated by the change of human behavior, because, arguably, Big Data affects human behavior itself (Schroeder, 2014).
De Mauro et al (2015) touch on the impact of Dig Data on libraries. The reorganization of academic libraries considering Big Data and the handling of Big Data by libraries is in a close conjunction with the reorganization of the entire campus and the handling of Big Data by the educational institution. In additional to the disruption posed by the Big Data phenomenon, higher education is facing global changes of economic, technological, social, and educational character. Daniel (2015) uses a chart to illustrate the complexity of these global trends. Parallel to the Big Data developments in America and Asia, the European Union is offering access to an EU open data portal (https://data.europa.eu/euodp/home ). Moreover, the Association of European Research Libraries expects under the H2020 program to increase “the digitization of cultural heritage, digital preservation, research data sharing, open access policies and the interoperability of research infrastructures” (Reilly, 2013).
The challenges posed by Big Data to human and social behavior (Schroeder, 2014) are no less significant to the impact of Big Data on learning. Cohen, Dolan, Dunlap, Hellerstein, & Welton (2009) propose a road map for “more conservative organizations” (p. 1492) to overcome their reservations and/or inability to handle Big Data and adopt a practical approach to the complexity of Big Data. Two Chinese researchers assert deep learning as the “set of machine learning techniques that learn multiple levels of representation in deep architectures (Chen & Lin, 2014, p. 515). Deep learning requires “new ways of thinking and transformative solutions (Chen & Lin, 2014, p. 523). Another pair of researchers from China present a broad overview of the various societal, business and administrative applications of Big Data, including a detailed account and definitions of the processes and tools accompanying Big Data analytics. The American counterparts of these Chinese researchers are of the same opinion when it comes to “think about the core principles and concepts that underline the techniques, and also the systematic thinking” (Provost and Fawcett, 2013, p. 58). De Mauro, Greco, and Grimaldi (2016), similarly to Provost and Fawcett (2013) draw attention to the urgent necessity to train new types of specialists to work with such data. As early as 2012, Davenport and Patil (2012), as cited in Mauro et al (2016), envisioned hybrid specialists able to manage both technological knowledge and academic research. Similarly, Provost and Fawcett (2013) mention the efforts of “academic institutions scrambling to put together programs to train data scientists” (p. 51). Further, Asomoah, Sharda, Zadeh & Kalgotra (2017) share a specific plan on the design and delivery of a big data analytics course. At the same time, librarians working with data acknowledge the shortcomings in the profession, since librarians “are practitioners first and generally do not view usability as a primary job responsibility, usually lack the depth of research skills needed to carry out a fully valid” data-based research (Emanuel, 2013, p. 207).
Borgman (2015) devotes an entire book to data and scholarly research and goes beyond the already well-established facts regarding the importance of Big Data, the implications of Big Data and the technical, societal, and educational impact and complications posed by Big Data. Borgman elucidates the importance of knowledge infrastructure and the necessity to understand the importance and complexity of building such infrastructure, in order to be able to take advantage of Big Data. In a similar fashion, a team of Chinese scholars draws attention to the complexity of data mining and Big Data and the necessity to approach the issue in an organized fashion (Wu, Xhu, Wu, Ding, 2014).
Bruns (2013) shifts the conversation from the “macro” architecture of Big Data, as focused by Borgman (2015) and Wu et al (2014) and ponders over the influx and unprecedented opportunities for humanities in academia with the advent of Big Data. Does the seemingly ubiquitous omnipresence of Big Data mean for humanities a “railroading” into “scientificity”? How will research and publishing change with the advent of Big Data across academic disciplines?
Reyes (2015) shares her “skinny” approach to Big Data in education. She presents a comprehensive structure for educational institutions to shift “traditional” analytics to “learner-centered” analytics (p. 75) and identifies the participants in the Big Data process in the organization. The model is applicable for library use.
Being a new and unchartered territory, Big Data and Big Data analytics can pose ethical issues. Willis (2013) focusses on Big Data application in education, namely the ethical questions for higher education administrators and the expectations of Big Data analytics to predict students’ success. Daries, Reich, Waldo, Young, and Whittinghill (2014) discuss rather similar issues regarding the balance between data and student privacy regulations. The privacy issues accompanying data are also discussed by Tene and Polonetsky, (2013).
Privacy issues are habitually connected to security and surveillance issues. Andrejevic and Gates (2014) point out in a decision making “generated by data mining, the focus is not on particular individuals but on aggregate outcomes” (p. 195). Van Dijck (2014) goes into further details regarding the perils posed by metadata and data to the society, in particular to the privacy of citizens. Bail (2014) addresses the same issue regarding the impact of Big Data on societal issues, but underlines the leading roles of cultural sociologists and their theories for the correct application of Big Data.
Library organizations have been traditional proponents of core democratic values such as protection of privacy and elucidation of related ethical questions (Miltenoff & Hauptman, 2005). In recent books about Big Data and libraries, ethical issues are important part of the discussion (Weiss, 2018). Library blogs also discuss these issues (Harper & Oltmann, 2017). An academic library’s role is to educate its patrons about those values. Sugimoto et al (2012) reflect on the need for discussion about Big Data in Library and Information Science. They clearly draw attention to the library “tradition of organizing, managing, retrieving, collecting, describing, and preserving information” (p.1) as well as library and information science being “a historically interdisciplinary and collaborative field, absorbing the knowledge of multiple domains and bringing the tools, techniques, and theories” (p. 1). Sugimoto et al (2012) sought a wide discussion among the library profession regarding the implications of Big Data on the profession, no differently from the activities in other fields (e.g., Wixom, Ariyachandra, Douglas, Goul, Gupta, Iyer, Kulkami, Mooney, Phillips-Wren, Turetken, 2014). A current Andrew Mellon Foundation grant for Visualizing Digital Scholarship in Libraries seeks an opportunity to view “both macro and micro perspectives, multi-user collaboration and real-time data interaction, and a limitless number of visualization possibilities – critical capabilities for rapidly understanding today’s large data sets (Hwangbo, 2014).
The importance of the library with its traditional roles, as described by Sugimoto et al (2012) may continue, considering the Big Data platform proposed by Wu, Wu, Khabsa, Williams, Chen, Huang, Tuarob, Choudhury, Ororbia, Mitra, & Giles (2014). Such platforms will continue to emerge and be improved, with librarians as the ultimate drivers of such platforms and as the mediators between the patrons and the data generated by such platforms.
Every library needs to find its place in the large organization and in society in regard to this very new and very powerful phenomenon called Big Data. Libraries might not have the trained staff to become a leader in the process of organizing and building the complex mechanism of this new knowledge architecture, but librarians must educate and train themselves to be worthy participants in this new establishment.
Method
The study will be cleared by the SCSU IRB.
The survey will collect responses from library population and it readiness to use and use of Big Data. Send survey URL to (academic?) libraries around the world.
Data will be processed through SPSS. Open ended results will be processed manually. The preliminary research design presupposes a mixed method approach.
The study will include the use of closed-ended survey response questions and open-ended questions. The first part of the study (close ended, quantitative questions) will be completed online through online survey. Participants will be asked to complete the survey using a link they receive through e-mail.
Mixed methods research was defined by Johnson and Onwuegbuzie (2004) as “the class of research where the researcher mixes or combines quantitative and qualitative research techniques, methods, approaches, concepts, or language into a single study” (Johnson & Onwuegbuzie, 2004 , p. 17). Quantitative and qualitative methods can be combined, if used to complement each other because the methods can measure different aspects of the research questions (Sale, Lohfeld, & Brazil, 2002).
Sampling design
Online survey of 10-15 question, with 3-5 demographic and the rest regarding the use of tools.
1-2 open-ended questions at the end of the survey to probe for follow-up mixed method approach (an opportunity for qualitative study)
data analysis techniques: survey results will be exported to SPSS and analyzed accordingly. The final survey design will determine the appropriate statistical approach.
Project Schedule
Complete literature review and identify areas of interest – two months
Prepare and test instrument (survey) – month
IRB and other details – month
Generate a list of potential libraries to distribute survey – month
Contact libraries. Follow up and contact again, if necessary (low turnaround) – month
Collect, analyze data – two months
Write out data findings – month
Complete manuscript – month
Proofreading and other details – month
Significance of the work
While it has been widely acknowledged that Big Data (and its handling) is changing higher education (https://blog.stcloudstate.edu/ims?s=big+data) as well as academic libraries (https://blog.stcloudstate.edu/ims/2016/03/29/analytics-in-education/), it remains nebulous how Big Data is handled in the academic library and, respectively, how it is related to the handling of Big Data on campus. Moreover, the visualization of Big Data between units on campus remains in progress, along with any policymaking based on the analysis of such data (hence the need for comprehensive visualization).
This research will aim to gain an understanding on: a. how librarians are handling Big Data; b. how are they relating their Big Data output to the campus output of Big Data and c. how librarians in particular and campus administration in general are tuning their practices based on the analysis.
Based on the survey returns (if there is a statistically significant return), this research might consider juxtaposing the practices from academic libraries, to practices from special libraries (especially corporate libraries), public and school libraries.
References:
Adams Becker, S., Cummins M, Davis, A., Freeman, A., Giesinger Hall, C., Ananthanarayanan, V., … Wolfson, N. (2017). NMC Horizon Report: 2017 Library Edition.
Andrejevic, M., & Gates, K. (2014). Big Data Surveillance: Introduction. Surveillance & Society, 12(2), 185–196.
Asamoah, D. A., Sharda, R., Hassan Zadeh, A., & Kalgotra, P. (2017). Preparing a Data Scientist: A Pedagogic Experience in Designing a Big Data Analytics Course. Decision Sciences Journal of Innovative Education, 15(2), 161–190. https://doi.org/10.1111/dsji.12125
Bughin, J., Chui, M., & Manyika, J. (2010). Clouds, big data, and smart assets: Ten tech-enabled business trends to watch. McKinsey Quarterly, 56(1), 75–86.
Cohen, J., Dolan, B., Dunlap, M., Hellerstein, J. M., & Welton, C. (2009). MAD Skills: New Analysis Practices for Big Data. Proc. VLDB Endow., 2(2), 1481–1492. https://doi.org/10.14778/1687553.1687576
Daniel, B. (2015). Big Data and analytics in higher education: Opportunities and challenges. British Journal of Educational Technology, 46(5), 904–920. https://doi.org/10.1111/bjet.12230
Daries, J. P., Reich, J., Waldo, J., Young, E. M., Whittinghill, J., Ho, A. D., … Chuang, I. (2014). Privacy, Anonymity, and Big Data in the Social Sciences. Commun. ACM, 57(9), 56–63. https://doi.org/10.1145/2643132
De Mauro, A. D., Greco, M., & Grimaldi, M. (2016). A formal definition of Big Data based on its essential features. Library Review, 65(3), 122–135. https://doi.org/10.1108/LR-06-2015-0061
De Mauro, A., Greco, M., & Grimaldi, M. (2015). What is big data? A consensual definition and a review of key research topics. AIP Conference Proceedings, 1644(1), 97–104. https://doi.org/10.1063/1.4907823
Eaton, M. (2017). Seeing Library Data: A Prototype Data Visualization Application for Librarians. Publications and Research. Retrieved from http://academicworks.cuny.edu/kb_pubs/115
Emanuel, J. (2013). Usability testing in libraries: methods, limitations, and implications. OCLC Systems & Services: International Digital Library Perspectives, 29(4), 204–217. https://doi.org/10.1108/OCLC-02-2013-0009
Graham, M., & Shelton, T. (2013). Geography and the future of big data, big data and the future of geography. Dialogues in Human Geography, 3(3), 255–261. https://doi.org/10.1177/2043820613513121
Hashem, I. A. T., Yaqoob, I., Anuar, N. B., Mokhtar, S., Gani, A., & Ullah Khan, S. (2015). The rise of “big data” on cloud computing: Review and open research issues. Information Systems, 47(Supplement C), 98–115. https://doi.org/10.1016/j.is.2014.07.006
Laney, D. (2001, February 6). 3D Data Management: Controlling Data Volume, Velocity, and Variety.
Miltenoff, P., & Hauptman, R. (2005). Ethical dilemmas in libraries: an international perspective. The Electronic Library, 23(6), 664–670. https://doi.org/10.1108/02640470510635746
Philip Chen, C. L., & Zhang, C.-Y. (2014). Data-intensive applications, challenges, techniques and technologies: A survey on Big Data. Information Sciences, 275(Supplement C), 314–347. https://doi.org/10.1016/j.ins.2014.01.015
Provost, F., & Fawcett, T. (2013). Data Science and its Relationship to Big Data and Data-Driven Decision Making. Big Data, 1(1), 51–59. https://doi.org/10.1089/big.2013.1508
Reyes, J. (2015). The skinny on big data in education: Learning analytics simplified. TechTrends: Linking Research & Practice to Improve Learning, 59(2), 75–80. https://doi.org/10.1007/s11528-015-0842-1
Schroeder, R. (2014). Big Data and the brave new world of social media research. Big Data & Society, 1(2), 2053951714563194. https://doi.org/10.1177/2053951714563194
Sugimoto, C. R., Ding, Y., & Thelwall, M. (2012). Library and information science in the big data era: Funding, projects, and future [a panel proposal]. Proceedings of the American Society for Information Science and Technology, 49(1), 1–3. https://doi.org/10.1002/meet.14504901187
Tene, O., & Polonetsky, J. (2012). Big Data for All: Privacy and User Control in the Age of Analytics. Northwestern Journal of Technology and Intellectual Property, 11, [xxvii]-274.
van Dijck, J. (2014). Datafication, dataism and dataveillance: Big Data between scientific paradigm and ideology. Surveillance & Society; Newcastle upon Tyne, 12(2), 197–208.
Waller, M. A., & Fawcett, S. E. (2013). Data Science, Predictive Analytics, and Big Data: A Revolution That Will Transform Supply Chain Design and Management. Journal of Business Logistics, 34(2), 77–84. https://doi.org/10.1111/jbl.12010
West, D. M. (2012). Big data for education: Data mining, data analytics, and web dashboards. Governance Studies at Brookings, 4, 1–0.
Willis, J. (2013). Ethics, Big Data, and Analytics: A Model for Application. Educause Review Online. Retrieved from https://docs.lib.purdue.edu/idcpubs/1
Wixom, B., Ariyachandra, T., Douglas, D. E., Goul, M., Gupta, B., Iyer, L. S., … Turetken, O. (2014). The current state of business intelligence in academia: The arrival of big data. CAIS, 34, 1.
Wu, X., Zhu, X., Wu, G. Q., & Ding, W. (2014). Data mining with big data. IEEE Transactions on Knowledge and Data Engineering, 26(1), 97–107. https://doi.org/10.1109/TKDE.2013.109
Wu, Z., Wu, J., Khabsa, M., Williams, K., Chen, H. H., Huang, W., … Giles, C. L. (2014). Towards building a scholarly big data platform: Challenges, lessons and opportunities. In IEEE/ACM Joint Conference on Digital Libraries (pp. 117–126). https://doi.org/10.1109/JCDL.2014.6970157
Vicky Steeves (@VickySteeves) is the first Research Data Management and Reproducibility Librarian
Reproducibility is made so much more challenging because of computers, and the dominance of closed-source operating systems and analysis software researchers use. Ben Marwick wrote a great piece called ‘How computers broke science – and what we can do to fix it’ which details a bit of the problem. Basically, computational environments affect the outcome of analyses (Gronenschild et. al (2012) showed the same data and analyses gave different results between two versions of macOS), and are exceptionally hard to reproduce, especially when the license terms don’t allow it. Additionally, programs encode data incorrectly and studies make erroneous conclusions, e.g. Microsoft Excel encodes genes as dates, which affects 1/5 of published data in leading genome journals.
technology to capture computational environments, workflow, provenance, data, and code are hugely impactful for reproducibility. It’s been the focus of my work, in supporting an open source tool called ReproZip, which packages all computational dependencies, data, and applications in a single distributable package that other can reproduce across different systems. There are other tools that fix parts of this problem: Kepler and VisTrails for workflow/provenance, Packrat for saving specific R packages at the time a script is run so updates to dependencies won’t break, Pex for generating executable Python environments, and o2r for executable papers (including data, text, and code in one).
a plugin for Jupyter notebooks), and added a user interface to make it friendlier to folks not comfortable on the command line.
what is shall and what does it do. language close to computers, fast.
what is “bash” . cd, ls
shell job is a translator between the binory code, the middle name. several types of shells, with slight differences. one natively installed on MAC and Unix. born-again shell
bash commands: cd change director, ls – list; ls -F if it does not work: man ls (manual for LS); colon lower left corner tells you can scrool; q for escape; ls -ltr
arguments is colloquially used with different names. options, flags, parameters
cd .. – move up one directory . pwd : see the content cd data_shell/ – go down one directory
cd ~ – brings me al the way up . $HOME (universally defined variable
the default behavior of cd is to bring to home directory.
the core shall commands accept the same shell commands (letters)
$ du -h . gives me the size of the files. ctrl C to stop
$ clear . – clear the entire screen, scroll up to go back to previous command
man history $ history $! pwd (to go to pwd . $ history | grep history (piping)
$ cat (and the file name) – standard output
$ cat ../
+++++++++++++++
how to edit and delete files
to create new folder: $ mkdir . – make directory
text editors – nano, vim (UNIX text editors) . $ nano draft.txt . ctrl O (save) ctr X (exit) .
$ vim . shift esc (key) and in command line – wq (write quit) or just “q”
$ mv draft.txt ../data . (move files)
to remove $ rm thesis/: $ man rm
copy files $cp $ touch . (touches the file, creates if new)
C and C++. scripting purposes in microbiology (instructor). libraries, packages alongside Python, which can extend its functionality. numpy and scipy (numeric and science python). Python for academic libraries?
going out of python $ quit () . python expect beginning and end parenthesis
new terminal needed after installation. anaconda 5.0.1
python 3 is complete redesign, not only an update.
python is object oriented and i can define the objects
python creates its own types of objects (which we model) and those are called “DataFrame”
method applied it is an attribute to data that already exists. – difference from function
data.info() . is function – it does not take any arguments
whereas
data.columns . is a method
print (data.T) . transpose. not easy in Excel, but very easy in Python
data = pandas.read_csv(‘/Users/plamen_local/Desktop/data/gapminder_gdp_oceania.csv’ , index_col=’country’)
data.loc[‘Australia’].plot()
plt.xticks(rotation=10)
GD plot 2 is the most well known library.
xelatex is a PDF engine. reST restructured text like Markdown. google what is the best PDF engine with Jupyter
four loops . any computer language will have the concept of “for” loop. In Python: 1. whenever we create a “for” loop, that line must end with a single colon
2. indentation. any “if” statement in the “for” loop, gets indented
Ercegovac, Z., & Richardson, J. J. (2004). Academic Dishonesty, Plagiarism Included, in the Digital Age: A Literature Review. College & Research Libraries, 65(4), 301-318.
what constitutes plagiarism, how prevalent plagiarism is in our schools, colleges, and society, what is done to prevent and reduce plagiarism, the attitudes of faculty toward academic dishonesty in general, and individual differences as predictors of academic dishonesty
the interdisciplinary nature of the topic and the ethical challenges of accessing and using information technology, especially in the age of the Internet. Writings have been reported in the literatures of education, psychology, and library and information studies, each looking at academic dishonesty from different perspectives. The literature has been aimed at instructors and scholars in education and developmental psychology, as well as college librarians and school media specialists.
Although the literature appears to be scattered across many fields, standard dictionaries and encyclopedias agree on the meaning of plagiarism.
According to Webster’s, plagiarism is equated with kidnapping and defined as “the unauthorized use of the language and thoughts of another author and the representation of them as one’s own.”(FN10) The Oxford English Dictionary defines plagiarism as the “wrongful appropriation or purloining, and publication as one’s own, of the ideas, or the expression of the ideas (literary, artistic, musical, mechanical, etc.).”(
plagiarism is an elusive concept and has been treated differently in different contexts.
different types of plagiarism: direct plagiarism; truncation (where strings are deleted in the beginning or ending); excision (strings are deleted from the middle of sentences); insertions; inversions; substitutions; change of tense, person, number, or voice; undocumented factual information; inappropriate use of quotation marks; or paraphrasing.
defined plagiarism as a deliberate use of “someone else’s language, ideas, or other original (not common-knowledge) material without acknowledging its source.”(FN30) This definition is extended to printed and digital materials, manuscripts, and other works. Plagiarism is interrelated to intellectual property, copyright, and authorship, and is discussed from the perspective of multiculturalism.(FN31)
Jeffrey Klausman made three distinctions among direct plagiarism, paraphrase plagiarism, and patchwork plagiarism
+++++++++++++++
Cosgrove, J., Norelli, B., & Putnam, E. (2005). Setting the Record Straight: How Online Database Providers Are Handling Plagiarism and Fabrication Issues. College & Research Libraries, 66(2), 136-148.
None of the database providers used links for corrections. Although it is true that the structure of a particular database (LexisNexis, for instance) may make static links more difficult to create than appending corrections, it is a shame that the most elemental characteristic of online resources–the ability to link–is so underutilized within the databases themselves.
Finding reliable materials using online databases is difficult enough for students, especially undergraduates, without having to navigate easily fixed pitfalls. The articles in this study are those most obviously in need of a correction or a link to a correction–articles identified by the publications themselves as being flawed by error, plagiarism, or fabrication. Academic librarians instruct students to carefully evaluate the literature in their campuses’ database resources. Unfortunately, it is not practical to expect undergraduate students to routinely search at the level necessary to uncover corrections and retractions nor do librarians commonly have the time to teach those skills.
digital resource sets available through MnPALS Plus
Two sets of open access, free digital resources that may be of interest to students and faculty have been added to SCSU’s online catalog (MnPALS Plus).
Open Textbook Library (a project of the University of Minnesota)
(appears in Collection drop-down menu as “Univ of Mn Open Textbook Library”)
“Open textbooks are textbooks that have been funded, published, and licensed to be freely used, adapted, and distributed. These books have been reviewed by faculty from a variety of colleges and universities to assess their quality. These books can be downloaded for no cost, or printed at low cost. All textbooks are either used at multiple higher education institutions; or affiliated with an institution, scholarly society, or professional organization.”
For more information, see https://open.umn.edu/opentextbooks/
Ebooks Minnesota
“Ebooks Minnesota is an online ebook collection for all Minnesotans. The collection covers a wide variety of subjects for readers of all ages, and features content from our state’s independent publishers, including some of our best literature and nonfiction.”
For more information, see https://mndigital.org/projects/ebooks-minnesota
These resources are included in any search done in the online catalog. To view or search one of these collections specifically, go the the Advanced Search in MnPALS Plus and select the desired collection from the Collection dropdown. Users can add search terms, or just click “Find” without entering any search terms to see the entire collection.
Ms. Joanne Lipman
October 20, 2017
Editor-in-Chief of USA Today
7950 Jones Branch Drive
McLean, VA 22108
Dear Ms. Lipman,
In our roles as the Board of Directors of the Association for Library and Information Science Education (ALISE), we are writing to express our profound disappointment with the USA Today career advice feature on October 13, 2017 entitled “Careers: 8 jobs that won’t exist in 2030,” which declared that “librarian” is the number one career among the eight jobs that inaccurate statement on two fronts: first, that the profession is declining, and second, that this alleged will disappear in 2030. This is a false and decline is a result of libraries as warehouses of printed books.
The author of this article may not realize that a professional librarian position in the U.S. and many other countries requires a Master’s degree. According to a recent article in Library Journal, 86% of recent graduates from American Library Association (ALA) accredited schools have found jobs. Another recent report (released on September 28, 2017) by Pearson, Nesta, and Oxford University predicts growth in the information professions, including librarians, curators, and archivists. They are among the top ten jobs likely to experience increased demand in 2030. The report is summarized by Library Journal in its article entitled “The Job Outlook: In 2030, Librarians Will Be in Demand.” Furthermore, your own job posting section for librarian positions does not show the decline of our profession. A close reading of the job titles should have indicated to the author that librarians do more than simply check out books.
This article demonstrates a lack of understanding of librarians’ work as information professionals. My note: but so do lack understanding a lot of librarians, paraprofessionals and administrators in libraries. They are the one, who leave the impressions reflected in the article of US Today. Information professionals IS the keyword and, as during the hype around year 2000 with Barnes & Nobles, a great number of people working in libraries continue to behave as it is the Middle Ages and care of paper-based materials the one and only responsibility a “librarian” may have. The lack of understanding regarding the wide scope of “information professionals” is profound.
Libraries provide access to print and special collections of media, and subscription-based or free electronic resources. All of these must be curated, cataloged, or organized by professional librarians to make them accessible to their users. My note: beating your own drum is good, but when failing to recognize the existence of folksonomy and its impact, do not get upset when US Today reflects the impact
College and university librarians carry out research consultations and instruct student and faculty in finding, evaluating, and using information. My note: when faculty let them do it. And administration recognizes it. It is a shaky position, which does not exclude the 2030 scenario.
Public librarians connect patrons to community resources, lead programming for children and adults, and engage in community outreach and advocacy. Special librarians work for corporations, federal and state institutions, focusing on gathering competitive intelligence and making sure their organizations have access to the information they need to make sound business or strategic decisions.
The article also inaccurately presents libraries as dedicated solely to books:
More and more people are clearing out those paperbacks and downloading e-books on their Tablets and Kindles instead. The same goes for borrowing — as books fall out of favor, libraries are not as popular as they once were. That means you’ll have a tough time finding a job if you decide to become a librarian. Many schools and universities are already moving their libraries off the shelves and onto the Internet.
In addition to providing access to books, journals, newspapers, and other media, both electronically and in print, libraries provide access to technology, from computers, laptops, and iPads to 3D printers, My note: are we? are we doing this at our library? Are the reference librarians allowing such blasphemous thoughts penetrate this library? And if they do, do they allow other professionals to collaborate with them, or “keep it for themselves?”
multimedia software, and recording studios. My note: whaaat?
Many libraries have expanded their non-print collections and are circulating a wide variety of objects including tools, musical instruments, toys, wifi hotspots, and artwork. Libraries are highly valued as community centers and safe spaces that allow people to connect with information and with each other. Research shows that libraries are one of the most trusted and valued public institutions in the country.
The article further argues that librarians and libraries are not needed because printed books are falling out of favor. However, there is considerable counter-evidence that printed books are still in demand, including the articles cited below.
Cain, S. (2017, March 14). Ebook sales continue to fall as younger generations drive appetite for print. The Guardian. Retrieved from:
Milliot, J. (2017, January 20). The Bad News About E-books: Nielsen reports units fell 16% in 2016 compared to 2015. Publishers Weekly. Retrieved from:
We respectfully request an open response from you or from the author of the article. Sincerely,
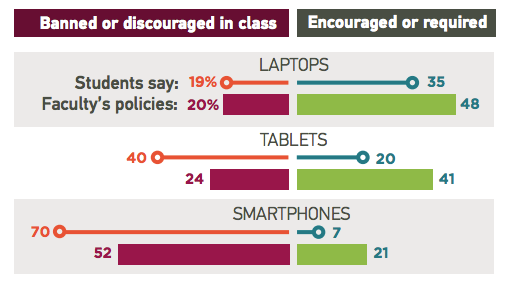
Students match their preference for hybrid learning with a belief that it is the most effective learning environment for them.
Despite the fact that faculty prefer teaching in a hybrid environment, they remain skeptical of online learning. Nearly half do not agree online 45% learning is effective.
Students asked what technologies they wish their instructors used more, and we asked faculty what technologies they think could make them more effective instructors. Both agree that content and resource-focused technologies should be incorporated more and social media and tablets should be incorporated less.
con?:with the advent of personal assistants like Siri and Google Now that aim to serve up information before you even know you need it, you don’t even need to type the questions.
pro: Whenever new technology emerges — including newspapers and television — discussions about how it will threaten our brainpower always crops up, Harvard psychology professor Steven Pinker wrote in a 2010 op-ed in The New York Times. Instead of making us stupid, he wrote, the Internet and technology “are the only things that will keep us smart.”
Pro and con: Daphne Bavelier, a professor at the University of Geneva, wrote in 2011 that we may have lost the ability for oral memorization valued by the Greeks when writing was invented, but we gained additional skills of reading and text analysis.
con: Daphne Bavelier, a professor at the University of Geneva, wrote in 2011 that we may have lost the ability for oral memorization valued by the Greeks when writing was invented, but we gained additional skills of reading and text analysis.
con: A 2008 study commissioned by the British Library found that young people go through information online very quickly without evaluating it for accuracy.
pro or con?: A 2011 study in the journal Science showed that when people know they have future access to information, they tend to have a better memory of how and where to find the information — instead of recalling the information itself.
pro: The bright side lies in a 2009 study conducted by Gary Small, the director of University of California Los Angeles’ Longevity Center, that explored brain activity when older adults used search engines. He found that among older people who have experience using the Internet, their brains are two times more active than those who don’t when conducting Internet searches.
the Internet holds great potential for education — but curriculum must change accordingly. Since content is so readily available, teachers should not merely dole out information and instead focus on cultivating critical thinking
make questions “Google-proof.”
“Design it so that Google is crucial to creating a response rather than finding one,” he writes in his company’s blog. “If students can Google answers — stumble on (what) you want them to remember in a few clicks — there’s a problem with the instructional design.”