Searching for "data mining"
https://www.linkedin.com/groups/934617/934617-6255144273688215555
Call For Chapters: Responsible Analytics and Data Mining in Education: Global Perspectives on Quality, Support, and Decision-Making
SUBMIT A 1-2 PAGE CHAPTER PROPOSAL
Deadline – June 1, 2017
Title: Responsible Analytics and Data Mining in Education: Global Perspectives on Quality, Support, and Decision-Making
Synopsis:
Due to rapid advancements in our ability to collect, process, and analyze massive amounts of data, it is now possible for educators at all levels to gain new insights into how people learn. According to Bainbridge, et. al. (2015), using simple learning analytics models, educators now have the tools to identify, with up to 80% accuracy, which students are at the greatest risk of failure before classes even begin. As we consider the enormous potential of data analytics and data mining in education, we must also recognize a myriad of emerging issues and potential consequences—intentional and unintentional—to implement them responsibly. For example:
· Who collects and controls the data?
· Is it accessible to all stakeholders?
· How are the data being used, and is there a possibility for abuse?
· How do we assess data quality?
· Who determines which data to trust and use?
· What happens when the data analysis yields flawed results?
· How do we ensure due process when data-driven errors are uncovered?
· What policies are in place to address errors?
· Is there a plan for handling data breaches?
This book, published by Routledge Taylor & Francis Group, will provide insights and support for policy makers, administrators, faculty, and IT personnel on issues pertaining the responsible use data analytics and data mining in education.
Important Dates:
· June 1, 2017 – Chapter proposal submission deadline
· July 15, 2017 – Proposal decision notification
· October 15, 2017 – Full chapter submission deadline
· December 1, 2017 – Full chapter decision notification
· January 15, 2018 – Full chapter revisions due
++++++++++++++++++
more on data mining in this IMS blog
https://blog.stcloudstate.edu/ims?s=data+mining
more on analytics in this IMS blog
https://blog.stcloudstate.edu/ims?s=analytics
Beyond the Horizon Webinar on Student Data
March 29, 2017 @ 12-1pm US Central Time
http://www.nmc.org/events/nmc-beyond-the-horizon-integrating-student-data-across-platforms/
The growing use of data mining software in online education has great potential to support student success by identifying and reaching out to struggling students and streamlining the path to graduation. This can be a challenge for institutions that are using a variety of technology systems that are not integrated with each other. As institutions implement learning management systems, degree planning technologies, early alert systems, and tutor scheduling that promote increased interactions among various stakeholders, there is a need for centralized aggregation of these data to provide students with holistic support that improves learning outcomes. Join us to hear from an institutional exemplar who is building solutions that integrate student data across platforms. Then work with peers to address challenges and develop solutions of your own.
+++++++++++++++++++++++
more on altmetrics in this IMS blog
https://blog.stcloudstate.edu/ims?s=altmetrics
more on big data in this IMS blog
https://blog.stcloudstate.edu/ims?s=big+data
http://www.rubedo.com.br/2016/08/38-great-resources-for-learning-data.html
Learn data mining languages: R, Python and SQL
W3Schools – Fantastic set of interactive tutorials for learning different languages. Their SQL tutorial is second to none. You’ll learn how to manipulate data in MySQL, SQL Server, Access, Oracle, Sybase, DB2 and other database systems.
Treasure Data – The best way to learn is to work towards a goal. That’s what this helpful blog series is all about. You’ll learn SQL from scratch by following along with a simple, but common, data analysis scenario.
10 Queries – This course is recommended for the intermediate SQL-er who wants to brush up on his/her skills. It’s a series of 10 challenges coupled with forums and external videos to help you improve your SQL knowledge and understanding of the underlying principles.
TryR – Created by Code School, this interactive online tutorial system is designed to step you through R for statistics and data modeling. As you work through their seven modules, you’ll earn badges to track your progress helping you to stay on track.
Leada – If you’re a complete R novice, try Lead’s introduction to R. In their 1 hour 30 min course, they’ll cover installation, basic usage, common functions, data structures, and data types. They’ll even set you up with your own development environment in RStudio.
Advanced R – Once you’ve mastered the basics of R, bookmark this page. It’s a fantastically comprehensive style guide to using R. We should all strive to write beautiful code, and this resource (based on Google’s R style guide) is your key to that ideal.
Swirl – Learn R in R – a radical idea certainly. But that’s exactly what Swirl does. They’ll interactively teach you how to program in R and do some basic data science at your own pace. Right in the R console.
Python for beginners – The Python website actually has a pretty comprehensive and easy-to-follow set of tutorials. You can learn everything from installation to complex analyzes. It also gives you access to the Python community, who will be happy to answer your questions.
PythonSpot – A complete list of Python tutorials to take you from zero to Python hero. There are tutorials for beginners, intermediate and advanced learners.
Read all about it: data mining books
Data Jujitsu: The Art of Turning Data into Product – This free book by DJ Patil gives you a brief introduction to the complexity of data problems and how to approach them. He gives nice, understandable examples that cover the most important thought processes of data mining. It’s a great book for beginners but still interesting to the data mining expert. Plus, it’s free!
Data Mining: Concepts and Techniques – The third (and most recent) edition will give you an understanding of the theory and practice of discovering patterns in large data sets. Each chapter is a stand-alone guide to a particular topic, making it a good resource if you’re not into reading in sequence or you want to know about a particular topic.
Mining of Massive Datasets – Based on the Stanford Computer Science course, this book is often sighted by data scientists as one of the most helpful resources around. It’s designed at the undergraduate level with no formal prerequisites. It’s the next best thing to actually going to Stanford!
Hadoop: The Definitive Guide – As a data scientist, you will undoubtedly be asked about Hadoop. So you’d better know how it works. This comprehensive guide will teach you how to build and maintain reliable, scalable, distributed systems with Apache Hadoop. Make sure you get the most recent addition to keep up with this fast-changing service.
Online learning: data mining webinars and courses
DataCamp – Learn data mining from the comfort of your home with DataCamp’s online courses. They have free courses on R, Statistics, Data Manipulation, Dynamic Reporting, Large Data Sets and much more.
Coursera – Coursera brings you all the best University courses straight to your computer. Their online classes will teach you the fundamentals of interpreting data, performing analyzes and communicating insights. They have topics for beginners and advanced learners in Data Analysis, Machine Learning, Probability and Statistics and more.
Udemy – With a range of free and pay for data mining courses, you’re sure to find something you like on Udemy no matter your level. There are 395 in the area of data mining! All their courses are uploaded by other Udemy users meaning quality can fluctuate so make sure you read the reviews.
CodeSchool – These courses are handily organized into “Paths” based on the technology you want to learn. You can do everything from build a foundation in Git to take control of a data layer in SQL. Their engaging online videos will take you step-by-step through each lesson and their challenges will let you practice what you’ve learned in a controlled environment.
Udacity – Master a new skill or programming language with Udacity’s unique series of online courses and projects. Each class is developed by a Silicon Valley tech giant, so you know what your learning will be directly applicable to the real world.
Treehouse – Learn from experts in web design, coding, business and more. The video tutorials from Treehouse will teach you the basics and their quizzes and coding challenges will ensure the information sticks. And their UI is pretty easy on the eyes.
Learn from the best: top data miners to follow
John Foreman – Chief Data Scientist at MailChimp and author of Data Smart, John is worth a follow for his witty yet poignant tweets on data science.
DJ Patil – Author and Chief Data Scientist at The White House OSTP, DJ tweets everything you’ve ever wanted to know about data in politics.
Nate Silver – He’s Editor-in-Chief of FiveThirtyEight, a blog that uses data to analyze news stories in Politics, Sports, and Current Events.
Andrew Ng – As the Chief Data Scientist at Baidu, Andrew is responsible for some of the most groundbreaking developments in Machine Learning and Data Science.
Bernard Marr – He might know pretty much everything there is to know about Big Data.
Gregory Piatetsky – He’s the author of popular data science blog
KDNuggets, the leading newsletter on data mining and knowledge discovery.
Christian Rudder – As the Co-founder of OKCupid, Christian has access to one of the most unique datasets on the planet and he uses it to give fascinating insight into human nature, love, and relationships
Dean Abbott – He’s contributed to a number of data blogs and authored his own book on Applied Predictive Analytics. At the moment, Dean is Chief Data Scientist at
SmarterHQ.
Practice what you’ve learned: data mining competitions
Kaggle – This is the ultimate data mining competition. The world’s biggest corporations offer big prizes for solving their toughest data problems.
Stack Overflow – The best way to learn is to teach. Stackoverflow offers the perfect forum for you to prove your data mining know-how by answering fellow enthusiast’s questions.
TunedIT – With a live leaderboard and interactive participation, TunedIT offers a great platform to flex your data mining muscles.
DrivenData – You can find a number of nonprofit data mining challenges on DataDriven. All of your mining efforts will go towards a good cause.
Quora – Another great site to answer questions on just about everything. There are plenty of curious data lovers on there asking for help with data mining and data science.
Meet your fellow data miner: social networks, groups and meetups
Facebook – As with many social media platforms, Facebook is a great place to meet and interact with people who have similar interests. There are a number of very active data mining groups you can join.
LinkedIn – If you’re looking for data mining experts in a particular field, look no further than LinkedIn. There are hundreds of data mining groups ranging from the generic to the hyper-specific. In short, there’s sure to be something for everyone.
Meetup – Want to meet your fellow data miners in person? Attend a meetup! Just search for data mining in your city and you’re sure to find an awesome group near you.
——————————
8 fantastic examples of data storytelling
https://www.import.io/post/8-fantastic-examples-of-data-storytelling/
Data storytelling is the realization of great data visualization. We’re seeing data that’s been analyzed well and presented in a way that someone who’s never even heard of data science can get it.
Google’s Cole Nussbaumer provides a friendly reminder of what data storytelling actually is, it’s straightforward, strategic, elegant, and simple.
++++++++++++++++++++++
more on text and data mining in this IMS blog
hthttps://blog.stcloudstate.edu/ims?s=data+mining
The EU just told data mining startups to take their business elsewhere
Lenard Koschwitz
By enabling the development and creation of big data for non-commercial use only, the European Commission has come up with a half-baked policy. Startups will be discouraged from mining in Europe and it will be impossible for companies to grow out of universities in the EU.
++++++++++++++++++
more on copyright and text and data mining in this IMS blog
https://blog.stcloudstate.edu/ims?s=copyrig
hthttps://blog.stcloudstate.edu/ims?s=data+mining
Webinar: Text and Data Mining: The Way Forward, June 30, 10am (EDT)
LITA announcement. Date: Thursday, June 30, 2016, Time: 10am-11:30am (EDT), Platform: WebEx. Registration required.
a critically important means of uncovering patterns of intellectual practice and usage that have the potential for illuminating facets and perspectives in research and scholarship that might otherwise not be noted. At the same time, challenges exist in terms of project management and support, licensing and other necessary protections.
Confirmed speakers include: Audrey McCulloch, Executive Director, ALPSP; Michael Levine-Clark, Dean of Libraries, University of Denver; Ellen Finnie, Head, Scholarly Communications and Collections Strategies, Massachusetts Institute of Technology; and Jeremy Frey, Professor of Physical Chemistry, Head of Computational Systems Chemistry, University of Southampton, UK.
Audrey McCulloch, Chief Executive, Association of Learned Professional and Society Publishers (ALPSP) and Director of the Publishers Licensing Society
Text and Data Mining: Library Opportunities and Challenges
Michael Levine-Clark, Dean and Director of Libraries, University of Denver
As scholars engage with text and data mining (TDM), libraries have struggled to provide support for projects that are unpredictable and tremendously varied. While TDM can be considered a fair use, in many cases contracts need to be renegotiated and special data sets created by the vendor. The unique nature of TDM projects makes it difficult to plan for them, and often the library and scholar have to figure them out as they go along. This session will explore strategies for libraries to effectively manage TDM, often in partnership with other units on campus and will offer suggestions to improve the process for all.
Michael Levine-Clark, the Dean and Director of the University of Denver Libraries, is the recipient of the 2015 HARRASOWITZ Leadership in Library Acquisitions Award. He writes and speaks regularly on strategies for improving academic library collection development practices, including the use of e-books in academic libraries, the development of demand-driven acquisition models, and implications of discovery tool implementation.
Library licensing approaches in text and data mining access for researchers at MIT
Ellen Finnie, Head, Scholarly Communications & Collections Strategy, MIT Libraries
This talk will address the challenges and successes that the MIT libraries have experienced in providing enabling services that deliver TDM access to MIT researchers, including:
· emphasizing TDM in negotiating contracts for scholarly resources
· defining requirements for licenses for TDM access
· working with information providers to negotiate licenses that work for our researchers
· addressing challenges and retooling to address barriers to success
· offering educational guides and workshops
· managing current needs v. the long-term goal– TDM as a reader’s right
Ellen Finnie is Head, Scholarly Communications & Collections Strategy in the MIT Libraries. She leads the MIT Libraries’ scholarly communications and collections strategy in support of the Libraries’ and MIT’s objectives, including in particular efforts to influence models of scholarly publishing and communication in ways that increase the impact and reach of MIT’s research and scholarship and which promote open, sustainable publishing and access models. She leads outreach efforts to faculty in support of scholarly publication reform and open access activities at MIT, and acts as the Libraries’ chief resource for copyright issues and for content licensing policy and negotiations. In that role, she is involved in negotiating licenses to include text/data mining rights and coordinating researcher access to TDM services for licensed scholarly resources. She has written and spoken widely on digital acquisitions, repositories, licensing, and open access.
Jeremy Frey, Professor of Physical Chemistry, Head of Computational Systems Chemistry, University of Southampton, UK
Text and Data Mining (TDM) facilitates the discovery, selection, structuring, and analysis of large numbers of documents/sets of data, enabling the visualization of results in new ways to support innovation and the development of new knowledge. In both academia and commercial contexts, TDM is increasingly recognized as a means to extract, re-use and leverage additional value from published information, by linking concepts, addressing specific questions, and creating efficiencies. But TDM in practice is not straightforward. TDM methodology and use are fast changing but are not yet matched by the development of enabling policies.
This webinar provides a review of where we are today with TDM, as seen from the perspective of the researcher, library, and licensing-publisher communities.
Center for Digital Education (CDE)
real-time impact on curriculum structure, instruction delivery and student learning, permitting change and improvement. It can also provide insight into important trends that affect present and future resource needs.
Big Data: Traditionally described as high-volume, high-velocity and high-variety information.
Learning or Data Analytics: The measurement, collection, analysis and reporting of data about learners and their contexts, for purposes of understanding and optimizing learning and the environments in which it occurs.
Educational Data Mining: The techniques, tools and research designed for automatically extracting meaning from large repositories of data generated by or related to people’s learning activities in educational settings.
Predictive Analytics: Algorithms that help analysts predict behavior or events based on data.
Predictive Modeling: The process of creating, testing and validating a model to best predict the probability of an outcome.
Data analytics, or the measurement, collection, analysis and reporting of data, is driving decisionmaking in many institutions. However, because of the unique nature of each district’s or college’s data needs, many are building their own solutions.
For example, in 2014 the nonprofit company inBloom, Inc., backed by $100 million from the Gates Foundation and the Carnegie Foundation for the Advancement of Teaching, closed its doors amid controversy regarding its plan to store, clean and aggregate a range of student information for states and districts and then make the data available to district-approved third parties to develop tools and dashboards so the data could be used by classroom educators.22
Tips for Student Data Privacy
Know the Laws and Regulations
There are many regulations on the books intended to protect student privacy and safety: the Family Educational Rights and Privacy Act (FERPA), the Protection of Pupil Rights Amendment (PPRA), the Children’s Internet Protection Act (CIPA), the Children’s Online Privacy Protection Act (COPPA) and the Health Insurance Portability and Accountability Act (HIPAA)
— as well as state, district and community laws. Because technology changes so rapidly, it is unlikely laws and regulations will keep pace with new data protection needs. Establish a committee to ascertain your institution’s level of understanding of and compliance with these laws, along with additional safeguard measures.
Make a Checklist Your institution’s privacy policies should cover security, user safety, communications, social media, access, identification rules, and intrusion detection and prevention.
Include Experts
To nail down compliance and stave off liability issues, consider tapping those who protect privacy for a living, such as your school attorney, IT professionals and security assessment vendors. Let them review your campus or district technologies as well as devices brought to campus by students, staff and instructors. Finally, a review of your privacy and security policies, terms of use and contract language is a good idea.
Communicate, Communicate, Communicate
Students, staff, faculty and parents all need to know their rights and responsibilities regarding data privacy. Convey your technology plans, policies and requirements and then assess and re-communicate those throughout each year.
“Anything-as-a-Service” or “X-as-a-Service” solutions can help K-12 and higher education institutions cope with big data by offering storage, analytics capabilities and more. These include:
• Infrastructure-as-a-Service (IaaS): Providers offer cloud-based storage, similar to a campus storage area network (SAN)
• Platform-as-a-Service (PaaS): Opens up application platforms — as opposed to the applications themselves — so others can build their own applications
using underlying operating systems, data models and databases; pre-built application components and interfaces
• Software-as-a-Service (SaaS): The hosting of applications in the cloud
• Big-Data-as-a-Service (BDaaS): Mix all the above together, upscale the amount of data involved by an enormous amount and you’ve got BDaaS
Suggestions:
Use accurate data correctly
Define goals and develop metrics
Eliminate silos, integrate data
Remember, intelligence is the goal
Maintain a robust, supportive enterprise infrastructure.
Prioritize student privacy
Develop bullet-proof data governance guidelines
Create a culture of collaboration and sharing, not compliance.
more on big data in this IMS blog:
https://blog.stcloudstate.edu/ims/?s=big+data&submit=Search
For all the data and feedback they provide, student information systems interfere with learning.
“School isn’t about learning. It’s about doing well.”
The singular focus on grades that these systems encourage turns learning into a competitive, zero-sum game for students.
My notes:
the parallel with the online grades systems at K12 is the Big Data movement at Higher Ed. Big Data must be about assisting teaching, not about determining teaching and instructors must be very well aware and very carefully navigating in this nebulous areas of assisting versus determining.
This article about quantifying management of teaching and learning in K12 reminds me the big hopes put on technocrats governing counties and economies in the 70s of the last centuries when the advent of the computers was celebrated as the solution of all our problems. Haven’t we, as civilization learned anything from that lesson?
Information Overload Helps Fake News Spread, and Social Media Knows It
Understanding how algorithm manipulators exploit our cognitive vulnerabilities empowers us to fight back
https://www.scientificamerican.com/article/information-overload-helps-fake-news-spread-and-social-media-knows-it/
a minefield of cognitive biases.
People who behaved in accordance with them—for example, by staying away from the overgrown pond bank where someone said there was a viper—were more likely to survive than those who did not.
Compounding the problem is the proliferation of online information. Viewing and producing blogs, videos, tweets and other units of information called memes has become so cheap and easy that the information marketplace is inundated. My note: folksonomy in its worst.
At the University of Warwick in England and at Indiana University Bloomington’s Observatory on Social Media (OSoMe, pronounced “awesome”), our teams are using cognitive experiments, simulations, data mining and artificial intelligence to comprehend the cognitive vulnerabilities of social media users.
developing analytical and machine-learning aids to fight social media manipulation.
As Nobel Prize–winning economist and psychologist Herbert A. Simon noted, “What information consumes is rather obvious: it consumes the attention of its recipients.”
attention economy
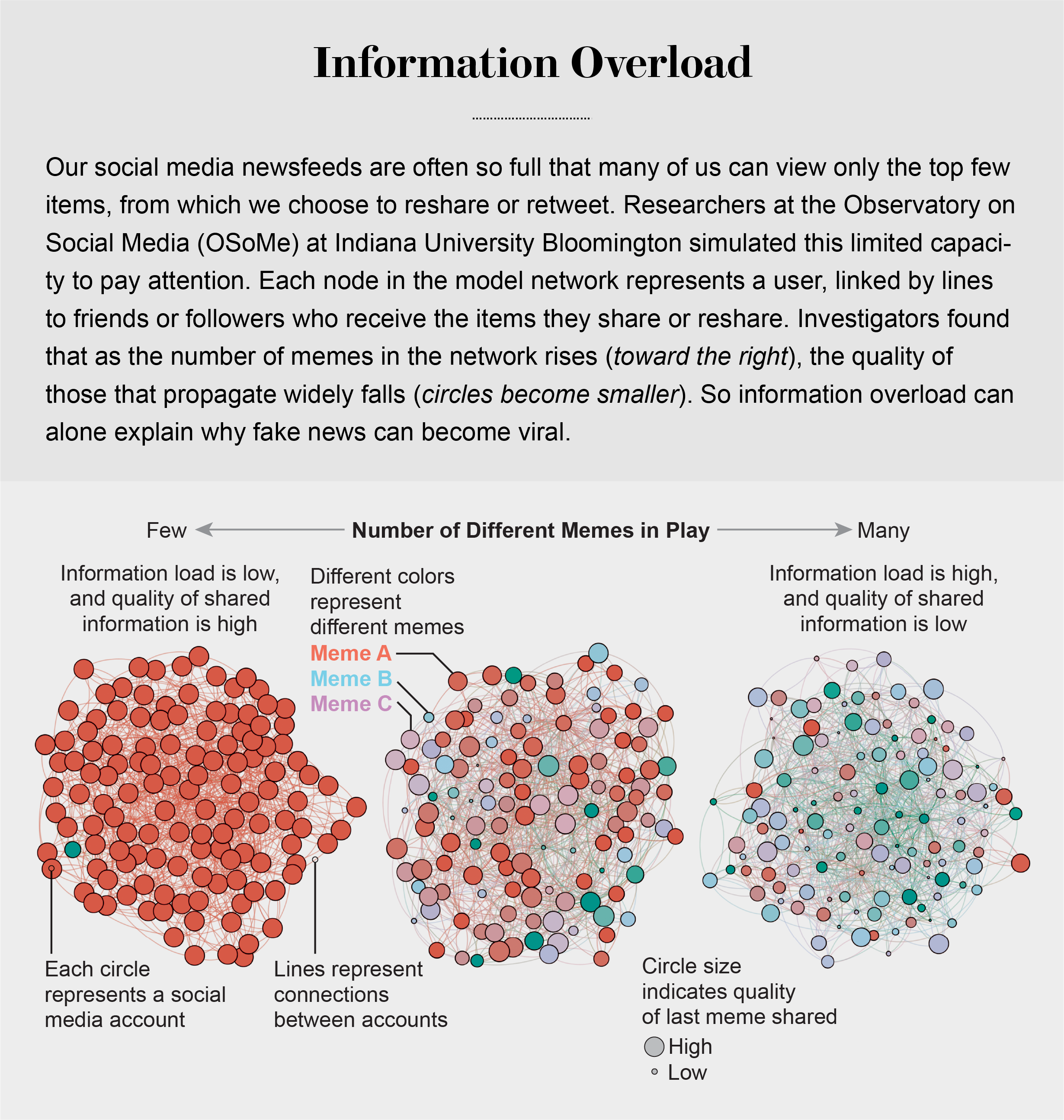
Our models revealed that even when we want to see and share high-quality information, our inability to view everything in our news feeds inevitably leads us to share things that are partly or completely untrue.
Frederic Bartlett
Cognitive biases greatly worsen the problem.
We now know that our minds do this all the time: they adjust our understanding of new information so that it fits in with what we already know. One consequence of this so-called confirmation bias is that people often seek out, recall and understand information that best confirms what they already believe.
This tendency is extremely difficult to correct.
Making matters worse, search engines and social media platforms provide personalized recommendations based on the vast amounts of data they have about users’ past preferences.
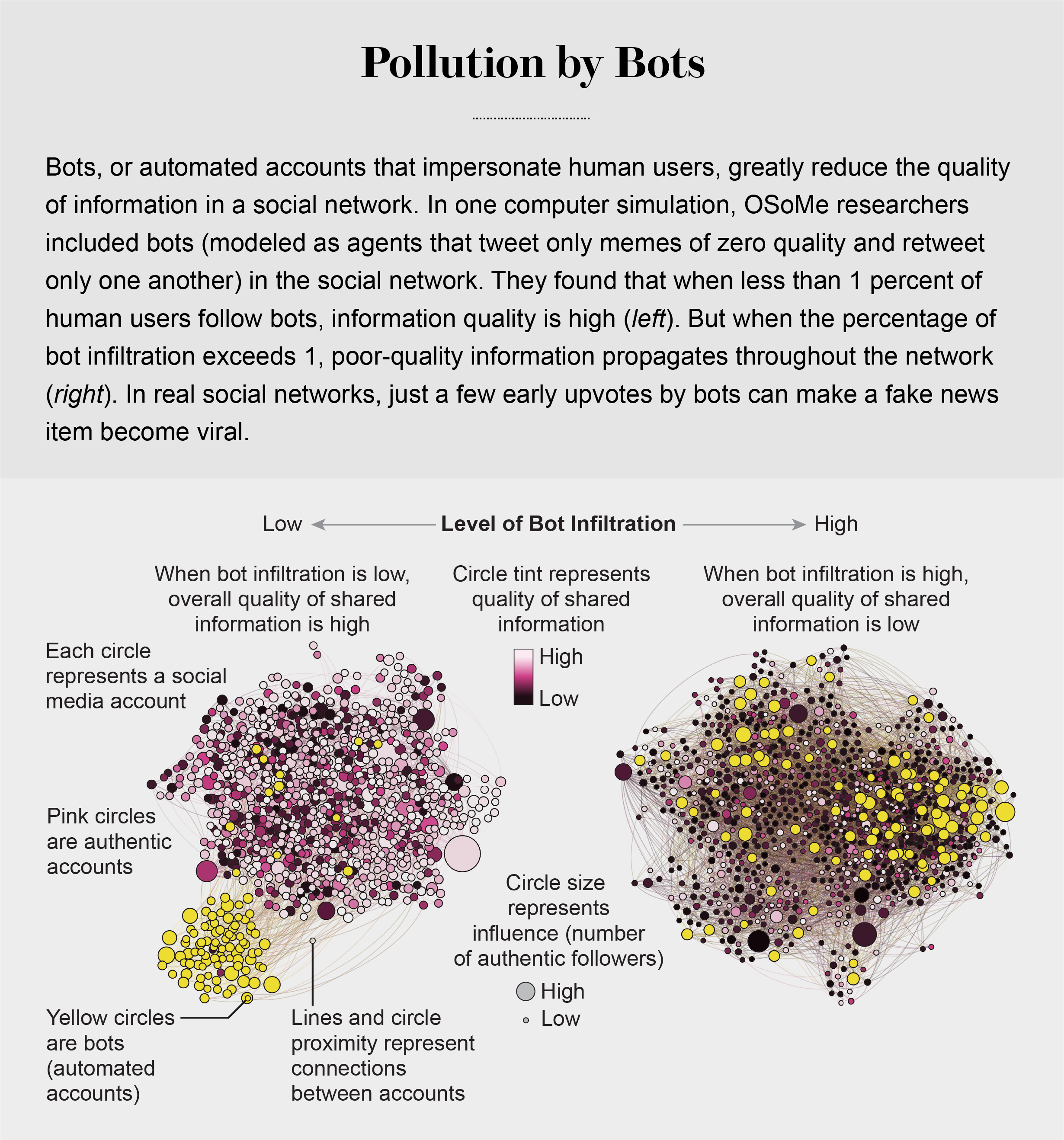
pollution by bots
Social Herding
social groups create a pressure toward conformity so powerful that it can overcome individual preferences, and by amplifying random early differences, it can cause segregated groups to diverge to extremes.
Social media follows a similar dynamic. We confuse popularity with quality and end up copying the behavior we observe.
information is transmitted via “complex contagion”: when we are repeatedly exposed to an idea, typically from many sources, we are more likely to adopt and reshare it.
In addition to showing us items that conform with our views, social media platforms such as Facebook, Twitter, YouTube and Instagram place popular content at the top of our screens and show us how many people have liked and shared something. Few of us realize that these cues do not provide independent assessments of quality.
programmers who design the algorithms for ranking memes on social media assume that the “wisdom of crowds” will quickly identify high-quality items; they use popularity as a proxy for quality. My note: again, ill-conceived folksonomy.
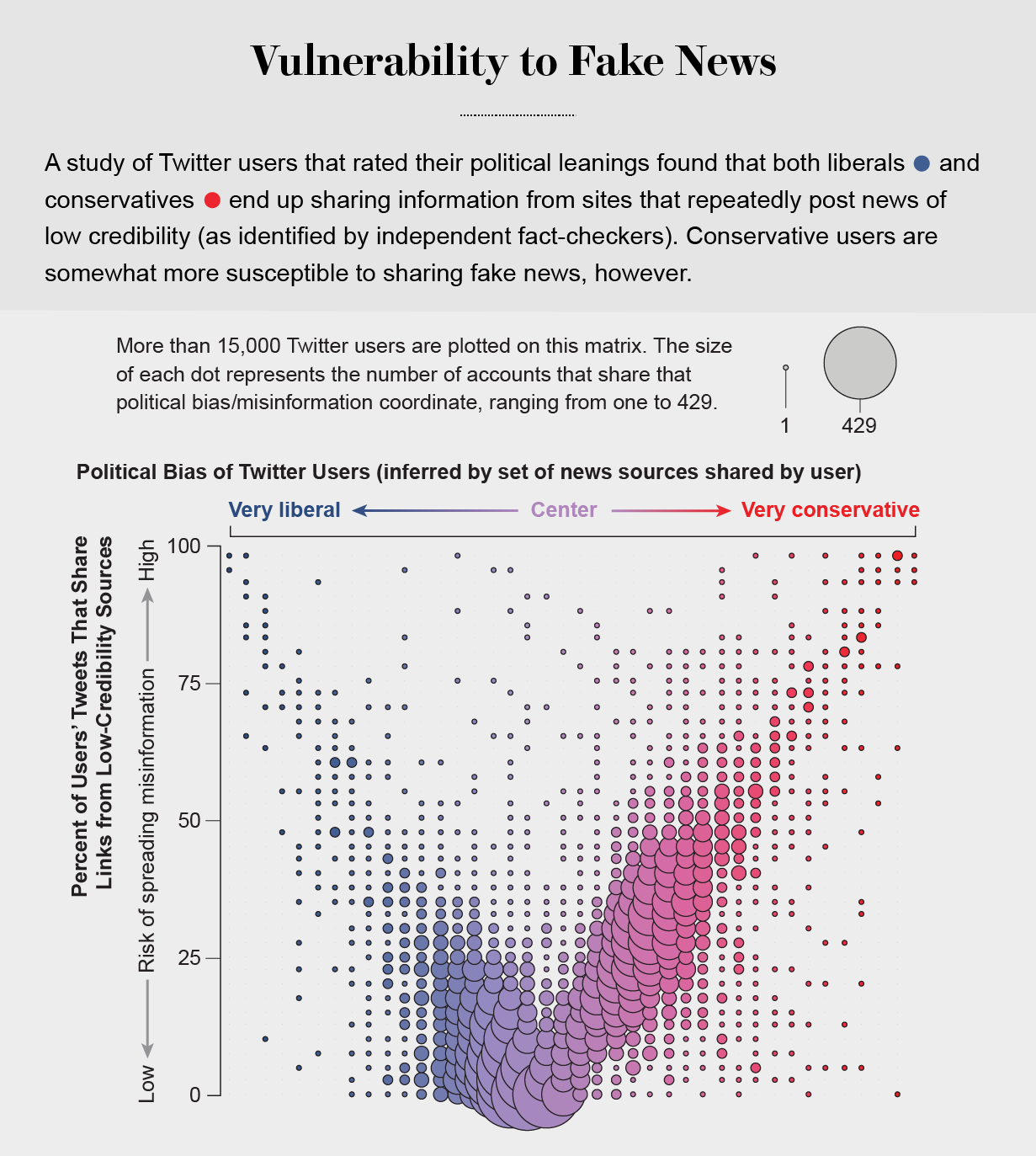
Echo Chambers
the political echo chambers on Twitter are so extreme that individual users’ political leanings can be predicted with high accuracy: you have the same opinions as the majority of your connections. This chambered structure efficiently spreads information within a community while insulating that community from other groups.
socially shared information not only bolsters our biases but also becomes more resilient to correction.
machine-learning algorithms to detect social bots. One of these, Botometer, is a public tool that extracts 1,200 features from a given Twitter account to characterize its profile, friends, social network structure, temporal activity patterns, language and other features. The program compares these characteristics with those of tens of thousands of previously identified bots to give the Twitter account a score for its likely use of automation.
Some manipulators play both sides of a divide through separate fake news sites and bots, driving political polarization or monetization by ads.
recently uncovered a network of inauthentic accounts on Twitter that were all coordinated by the same entity. Some pretended to be pro-Trump supporters of the Make America Great Again campaign, whereas others posed as Trump “resisters”; all asked for political donations.
a mobile app called Fakey that helps users learn how to spot misinformation. The game simulates a social media news feed, showing actual articles from low- and high-credibility sources. Users must decide what they can or should not share and what to fact-check. Analysis of data from Fakey confirms the prevalence of online social herding: users are more likely to share low-credibility articles when they believe that many other people have shared them.
Hoaxy, shows how any extant meme spreads through Twitter. In this visualization, nodes represent actual Twitter accounts, and links depict how retweets, quotes, mentions and replies propagate the meme from account to account.
Free communication is not free. By decreasing the cost of information, we have decreased its value and invited its adulteration.
Burdick, A. (2012). Digital humanities . Cambridge, MA: MIT Press.
https://mnpals-scs.primo.exlibrisgroup.com/discovery/fulldisplay?docid=alma990078472690104318&context=L&vid=01MNPALS_SCS:SCS&search_scope=MyInst_and_CI&tab=Everything&lang=en
digital humanities is born f the encounter between traditional humanities and computational methods.
p. 5. From Humanism to Humanities
While the foundations of of humanistic inquiry and the liberal arts can be traced back in the west to the medieval trivium and quadrivium, the modern and human sciences are rooted in the Renaissance shift from a medieval, church dominated, theocratic world view to be human centered one period the gradual transformation of early humanism into the disciplines that make up the humanities today Was profoundly shaped by the editorial practices involved in the recovery of the corpus of works from classical antiquity
P. 6. The shift from humanism to the institution only sanctioned disciplinary practices and protocols that we associate with the humanities today is best described as a gradual process of subdivision and specialization.
P. 7. Text-based disciplines in studies (classics, literature, philosophy, the history of ideas) make up, from the very start, the core of both the humanities and the great books curricular instituted in the 1920s and 1930s.
P. 10. Transmedia modes of argumentation
In the 21st-century, we communicate in media significantly more varied, extensible, and multiplicative then linear text. From scalable databases to information visualizations, from video lectures to multi-user virtual platforms serious content and rigorous argumentation take shape across multiple platforms in media. The best digital humanities pedagogy and research projects train students both in “reading “and “writing “this emergent rhetoric and in understanding how the reshape and three model humanistic knowledge. This means developing critically informed literacy expensive enough to include graphic design visual narrative time based media, and the development of interfaces (Rather then the rote acceptance of them as off-the-shelf products).
P. 11. The visual becomes ever more fundamental to the digital humanities, in ways that compliment, enhance, and sometimes are in pension with the textual.
There is no either/or, no simple interchangeability between language and the visual, no strict sub ordination of the one to the other. Words are themselves visual but other kinds of visual constructs do different things. The question is how to use each to its best effect into device meaningful interpret wing links, to use Theodor Nelson’s ludic neologism.
P. 11. The suite of expressive forms now encompasses the use of sound, motion graphics, animation, screen capture, video, audio, and the appropriation and into remix sink of code it underlines game engines. This expanded range of communicative tools requires those who are engaged in digital humanities world to familiarize themselves with issues, discussions, and debates in design fields, especially communication and interaction design. Like their print predecessors, form at the convention center screen environments can become naturalized all too quickly, with the results that the thinking that informed they were designed goes unperceived.
p. 13.
For digital humanists, design is a creative practice harnessing cultural, social, economic, and technological constraints in order to bring systems and objects into the world. Design in dialogue with research is simply a picnic, but when used to pose in frame questions about knowledge, design becomes an intellectual method. Digital humanities is a production based in Denver in which theoretical issues get tested in the design of implementations and implementations or loci after your radical reflection and elaboration.
Did you thaw humanists have much to learn from communication and media design about how to juxtapose and integrate words and images create hire he is of reading, Forge pathways of understanding, deployed grades in templates to best effect, and develop navigational schemata that guide in produce meaningful interactions.
P. 15. The field of digital digital humanities me see the emergence of polymaths who can “ do it all” : Who can research, write, shoot, edit, code, model, design, network, and dialogue with users. But there is also ample room for specialization and, particularly, for collaboration.
P. 16. Computational activities in digital humanities.
The foundational layer, computation, relies on principles that are, on the surface, at odds with humanistic methods.
P. 17. The second level involves processing in a way that conform to computational capacities, and this were explored in the first generation of digital scholarship and stylometrics, concordance development, and indexing.
P. 17.
Duration, analysis, editing, modeling.
Duration, analysis, editing, and modeling comprise fundamental activities at the core of digital humanities. Involving archives, collections, repositories, and other aggregations of materials, duration is the selection and organization of materials in an interpretive framework, argument, or exhibit.
P. 18. Analysis refers to the processing of text or data: statistical and quantitative methods of analysis have brought close readings of texts (stylometrics and genre analysis, correlation, comparisons of versions for alter attribution or usage patterns ) into dialogue with distant reading (The crunching cuff large quantities of information across the corpus of textual data or its metadata).
Edit think has been revived with the advent of digital media and the web and to continue to be an integral activity in textual as well as time based formats.
P. 18. Model link highlights the notion of content models- shapes of argument expressed in information structures in their design he digital project is always an expression of assumptions about knowledge: usually domain specific knowledge given an explicit form by the model in which it is designed.
P. 19. Each of these areas of activity- cure ration, analysis, editing, and modeling is supported by the basic building blocks of digital activity. But they also depend upon networks and infrastructure that are cultural and institutional as well as technical. Servers, software, and systems administration are key elements of any project design.
P. 30. Digital media are not more “evolved” have them print media nor are books obsolete; but the multiplicity of media in the very processes of mediation entry mediation in the formation of cultural knowledge and humanistic inquiry required close attention. Tug link between distant and clothes, macro and micro, and surface in depth becomes the norm. Here, we focus on the importance of visualization to the digital humanities before moving on to other, though often related, genre and methods such as
Locative investigation, thick mapping, animated archives, database documentaries, platform studies, and emerging practices like cultural analytics, data mining and humanities gaming.
P. 35. Fluid texture out what he refers to the mutability of texts in the variants and versions Whether these are produced through Authorial changes, anything, transcription, translation, or print production
Cultural Analytics, aggregation, and data mining.
The field of cultural Analytics has emerged over the past few years, utilizing tools of high-end computational analysis and data visualization today sect large-scale coach data sets. Cultural Analytic does Not analyze cultural artifacts, but operates on the level of digital models of this materials in aggregate. Again, the point is not to pit “close” hermeneutic reading against “distant” data mapping, but rather to appreciate the synergistic possibilities and tensions that exist between a hyper localized, deep analysis and a microcosmic view
p. 42.
Data mining is a term that covers a host of picnics for analyzing digital material by “parameterizing” some feature of information and extract in it. This means that any element of a file or collection of files that can be given explicit specifications, or parameters, can be extracted from those files for analysis.
Understanding the rehtoric of graphics is another essential skill, therefore, in working at a skill where individual objects are lost in the mass of processed information and data. To date, much humanities data mining has merely involved counting. Much more sophisticated statistical methods and use of probability will be needed for humanists to absorb the lessons of the social sciences into their methods
P. 42. Visualization and data design
Currently, visualization in the humanities uses techniques drawn largely from the social sciences, Business applications, and the natural sciences, all of which require self-conscious criticality in their adoption. Such visual displays including graphs and charts, may present themselves is subjective or even unmediated views of reality, rather then is rhetorical constructs.
+++++++++++++++++++++++++++
Warwick, C., Terras, M., & Nyhan, J. (2012). Digital humanities in practice . London: Facet Publishing in association with UCL Centre for Digital Humanities.
https://mnpals-scs.primo.exlibrisgroup.com/discovery/fulldisplay?docid=alma990078423690104318&context=L&vid=01MNPALS_SCS:SCS&search_scope=MyInst_and_CI&tab=Everything&lang=en
proposed topics for IM 260 class
- Media literacy. Differentiated instruction. Media literacy guide.
Fake news as part of media literacy. Visual literacy as part of media literacy. Media literacy as part of digital citizenship.
- Web design / web development
the roles of HTML5, CSS, Java Script, PHP, Bootstrap, JQuery, React and other scripting languages and libraries. Heat maps and other usability issues; website content strategy. THE MODEL-VIEW-CONTROLLER (MVC) design pattern
- Social media for institutional use. Digital Curation. Social Media algorithms. Etiquette Ethics. Mastodon
I hosted a LITA webinar in the fall of 2016 (four weeks); I can accommodate any information from that webinar for the use of the IM students
- OER and instructional designer’s assistance to book creators.
I can cover both the “library part” (“free” OER, copyright issues etc) and the support / creative part of an OER book / textbook
- “Big Data.” Data visualization. Large scale visualization. Text encoding. Analytics, Data mining. Unizin. Python, R in academia.
I can introduce the students to the large idea of Big Data and its importance in lieu of the upcoming IoT, but also departmentalize its importance for academia, business, etc. From infographics to heavy duty visualization (Primo X-Services API. JSON, Flask).
- NetNeutrality, Digital Darwinism, Internet economy and the role of your professional in such environment
I can introduce students to the issues, if not familiar and / or lead a discussion on a rather controversial topic
- Digital assessment. Digital Assessment literacy.
I can introduce students to tools, how to evaluate and select tools and their pedagogical implications
- Wikipedia
a hands-on exercise on working with Wikipedia. After the session, students will be able to create Wikipedia entries thus knowing intimately the process of Wikipedia and its information.
- Effective presentations. Tools, methods, concepts and theories (cognitive load). Presentations in the era of VR, AR and mixed reality. Unity.
I can facilitate a discussion among experts (your students) on selection of tools and their didactically sound use to convey information. I can supplement the discussion with my own findings and conclusions.
- eConferencing. Tools and methods
I can facilitate a discussion among your students on selection of tools and comparison. Discussion about the their future and their place in an increasing online learning environment
- Digital Storytelling. Immersive Storytelling. The Moth. Twine. Transmedia Storytelling
I am teaching a LIB 490/590 Digital Storytelling class. I can adapt any information from that class to the use of IM students
- VR, AR, Mixed Reality.
besides Mark Gill, I can facilitate a discussion, which goes beyond hardware and brands, but expand on the implications for academia and corporate education / world
- IoT , Arduino, Raspberry PI. Industry 4.0
- Instructional design. ID2ID
I can facilitate a discussion based on the Educause suggestions about the profession’s development
- Microcredentialing in academia and corporate world. Blockchain
- IT in K12. How to evaluate; prioritize; select. obsolete trends in 21 century schools. K12 mobile learning
- Podcasting: past, present, future. Beautiful Audio Editor.
a definition of podcasting and delineation of similar activities; advantages and disadvantages.
- Digital, Blended (Hybrid), Online teaching and learning: facilitation. Methods and techniques. Proctoring. Online students’ expectations. Faculty support. Asynch. Blended Synchronous Learning Environment
- Gender, race and age in education. Digital divide. Xennials, Millennials and Gen Z. generational approach to teaching and learning. Young vs old Millennials. Millennial employees.
- Privacy, [cyber]security, surveillance. K12 cyberincidents. Hackers.
- Gaming and gamification. Appsmashing. Gradecraft
- Lecture capture, course capture.
- Bibliometrics, altmetrics
- Technology and cheating, academic dishonest, plagiarism, copyright.